AUC-ROC 곡선에 기계 학습 명확하게 설명
AUC-ROC 곡선은 스타는 연기자!
당신은 당신의 기계 학습 모델을 구축했습니다-그래서 다음은 무엇입니까? 필요하신 그것을 평가하고 검증하는 방법에 좋은(나)그것은,그래서 당신은 그때 결정할 수 있는지에 그것을 구현합니다. 그것이 AUC-ROC 곡선이 들어오는 곳입니다.
이름이 될 수 있을 입지만,그것은 단지 우리가 계산하는”곡선 아래의 영역”(AUC)의”수신기 특성 연산자”(ROC). 혼란 스럽습니까? 나는 너를 느낀다! 나는 너의 신발에 있었다. 그러나 걱정하지 마세요,우리는이 용어가 무엇을 의미하는지 자세히 살펴보고 모든 것이 케이크 한 조각이 될 것입니다!

지금 바로 알고 있는 AUC-ROC 곡선에 도움이 우리를 시각화하는 방법론의 기기 분류기 학습을 추가할 수 있습니다. 비록 그것이 작동에 대해서만 이진 분류 문제로,우리는 볼 것이 끝으로 우리가 어떻게 확장할 수 있습 그것을 평가하는 멀티-클래스 분류제도.
이들은 AUC-ROC 곡선 뒤에있는 핵심 주제이기 때문에 감도 및 특이성과 같은 주제를 다룰 것입니다.
나가는 것이 좋습니다 기사를 통해서 혼란을 모체로 소개할 것입니다 몇 가지 중요한 측면 우리가 사용하는 것입니다.
목차
- 민감도와 특이도는 무엇입니까?
- 예측 확률
- AUC-ROC 곡선은 무엇입니까?
- AUC-ROC 곡선은 어떻게 작동합니까?
- 파이썬에서 AUC-ROC
- 다중 클래스 분류를위한 AUC-ROC
민감도와 특이성은 무엇입니까?
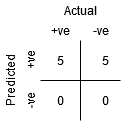
이것은 혼란 행렬의 모습입니다:
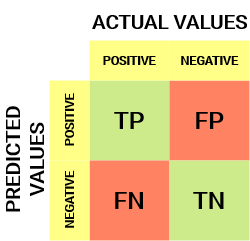
에서 혼란을 매트릭스,우리는 파생 수 있습니다 몇 가지 중요한 지표에서 다루지 않은 이전 문서입니다. 여기서 그들에 대해 이야기합시다.
감성/진정한 긍정적인 평가/리콜
![]()
감도 우리에게 무엇인의 비율은 긍정적인 클래스고 올바르게 분류된다.
간단한 예는 실제 아픈 사람들의 비율이 모델에 의해 올바르게 감지되었는지를 결정하는 것입니다.
거짓 부정적인 비율
![]()
거짓 부정적인 평가(FNR)우리에게 무엇인의 비율은 긍정적인 클래스고 잘못 분류에 의한 분류.
양의 클래스를 올바르게 분류하기를 원하기 때문에 더 높은 TPR 과 더 낮은 FNR 이 바람직합니다.
특이성/진정한 부정적인 비율
![]()
특이성을 우리에게 무엇인의 비율은 부정적인 클래스고 올바르게 분류된다.
로 같은 예를 들어에서 감도,특이성을 의미를 결정의 비율이 건강한 사람들이 제대로 식별되는 모델입니다.
False 긍정적인 비율
![]()
FPR 우리에게 무엇인의 비율은 부정적인 클래스고 잘못 분류에 의한 분류.
음수 클래스를 올바르게 분류하기를 원하기 때문에 더 높은 TNR 과 더 낮은 FPR 이 바람직합니다.
이러한 통계,감도와 특이성은 아마도 가장 중요하고 우리가 볼 수 있습니다 이후에 어떻게 이러한을 구축하는 데 사용되는 평가를 지표입니다. 그러나 그 전에 목표 클래스를 직접 예측하는 것보다 예측 확률이 더 나은 이유를 이해합시다.
의 확률을 예측
기계 학습 분류 모델을 예측하는데 사용될 수 있는 실제의 클래스는 데이터 포인트이 직접 또는 예측의 확률에 속하는 다른 클래스입니다. 후자는 우리에게 결과에 대한 더 많은 통제권을 부여합니다. 우리는 분류 자의 결과를 해석하기 위해 우리 자신의 임계 값을 결정할 수 있습니다. 이것은 때로는 완전히 새로운 모델을 구축하는 것보다 더 신중합니다!
설정이 다른 임계값을 분류하기 위한 긍정적인 클래를 위한 데이터 포인트가 실수로 변경 민감도와 특이성의 모델입니다. 중 하나 이러한 임계값을 것입니다 아마 더 나은 결과를 제공은 다른 사람보다는지 여부에 따라 우리는 것을 목표로 낮은 수의 틀린 네거티브나 틀린 확실성.
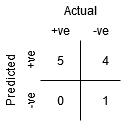
아래 표를 살펴보십시오:
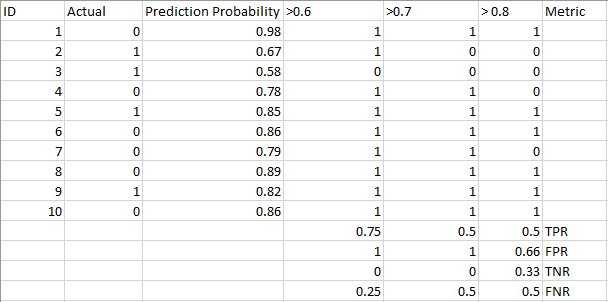
변화하는 임계값에 따라 메트릭이 변경됩니다. 서로 다른 혼란 행렬을 생성하고 이전 섹션에서 논의한 다양한 메트릭을 비교할 수 있습니다. 그러나 그것은 할 수있는 신중한 일이 아닐 것입니다. 대신,우리가 무엇을 할 수 있는 생성에 사는 일부의 이러한 지표 할 수 있도록 우리는 쉽게 시각화하는 임계값을 주고 우리에게 더 나은 결과입니다.
AUC-ROC 곡선은 그 문제를 해결합니다!
AUC-ROC 곡선은 무엇입니까?
수신기 연산자 특성(ROC)곡선은 이진 분류 문제에 대한 평가 메트릭입니다. 다양한 문턱 값에서 FPR 에 대해 TPR 을 플롯하고 본질적으로’신호’를’노이즈’와 분리하는 확률 곡선입니다. 곡선 아래의 영역(AUC)은 분류자가 클래스를 구별하는 능력의 척도이며 ROC 곡선의 요약으로 사용됩니다.
auc 가 높을수록 양수 클래스와 음수 클래스를 구별 할 때 모델의 성능이 향상됩니다.
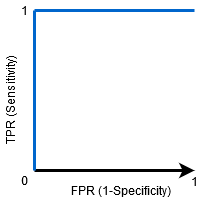
경우 AUC=1 로 분류할 수 있는 완벽하게 구별하는 모든 긍정적이고 부정적인 클래스 포인트습니다. 그러나 AUC 가 0 이었다면 분류자는 모든 네거티브를 긍정으로 예측하고 모든 긍정은 네거티브로 예측합니다.
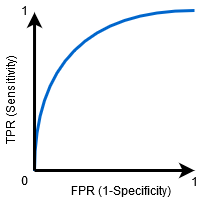
때 0.5<AUC<1,높은 기회가 있다는 분류기 구분할 수 있게 됩니다 긍정적인 클래스에서 값을 부정적인 클래스 값이 있습니다. 분류자가 거짓 네거티브와 거짓 긍정보다 더 많은 수의 진정한 긍정과 진정한 네거티브를 감지 할 수 있기 때문에 그렇습니다.
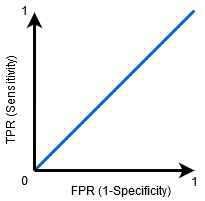
경우 AUC=0.5,다음의 분류되지 않을 구분할 수 있다는 긍정 및 부정적인 클래스 포인트입니다. 분류자가 모든 데이터 요소에 대해 임의의 클래스 또는 상수 클래스를 예측한다는 의미입니다.
따라서 분류 자에 대한 AUC 값이 높을수록 양수 클래스와 음수 클래스를 구별하는 능력이 향상됩니다.
AUC-ROC 곡선은 어떻게 작동합니까?
ROC 곡선에서 x 축 값이 높을수록 True negatives 보다 많은 수의 False positive 를 나타냅니다. 더 높은 Y 축 값은 거짓 네거티브보다 더 높은 수의 True positive 를 나타냅니다. 따라서 임계 값의 선택은 오 탐지와 오 탐지 사이의 균형을 맞추는 능력에 달려 있습니다.
자 발굴 조금 더 깊이 이해하는 방법을 우리 ROC 곡선 같이 다른 임계값 및 방법에 민감도와 특이도 있는 것은 다릅니다.
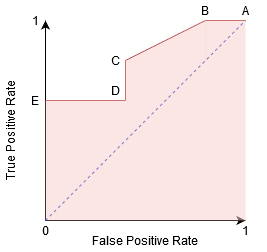
우리는 시도할 수 있고 이해하는 그래프를 생성하여 혼동을 위한 매트릭스의 각 지점에 해당하는 임계값과 이야기의 성능에 대한 우리의류:
A 지점은 대한 민감도가 가장 높은 특이성을 가장 낮다. 즉,모든 양의 클래스 포인트가 올바르게 분류되고 모든 음의 클래스 포인트가 잘못 분류됩니다.
에 사실은,어떤 지점에 블루 라인에 해당하는 상황이 진정한 긍정적인 비율은 동등한 거짓 긍정적인 비율.
위의 모든 점 이 라인에 해당하는 상황이의 비율을 올바르게 분류된 포인트에 속하는 긍정적인 클래스보다 높은 비율의 잘못 분류된 포인트에 속하는 부정적인 클래스입니다.
지만점 B 같은 감도로 점,그것은 더 높은 특이성. 잘못 음수 클래스 포인트의 수가 이전 임계 값에 비해 낮다는 것을 의미합니다. 이것은이 임계 값이 이전 임계 값보다 낫다는 것을 나타냅니다.
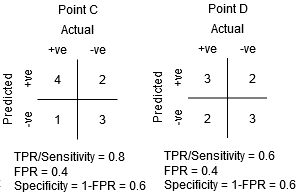
점 C 와 D 사이의 점 C 에서의 감도는 동일한 특이성에 대해 점 D 보다 높습니다. 즉,이는 같은 수의 잘못 분류 부정적인 반점 분류기 예측은 높은 수의 긍정적인 클래스 포인트입니다. 따라서,문턱에서 점 C 보다 낫다는 점 D.
,이제는 방법에 따라 많은 잘못 분류된 포인트는 우리가 원하는 견딜에 대한 우리의 분류,우리는 사이에서 선택점 B C 을 예측하는지 여부를 물리 칠 수 있습니다에 나 PUBG 나지 않습니다.
“거짓 희망은 두려움보다 더 위험합니다.”-J.R.R. Tolkein

점 E 는 특이성된 가장 높다. 모델에 의해 분류 된 오 탐지가 없음을 의미합니다. 모델은 모든 부정적인 클래스 포인트를 올바르게 분류 할 수 있습니다! 우리의 문제가 사용자에게 완벽한 노래 추천을 제공하는 것이라면이 점을 선택할 것입니다.
이 논리로 가면 완벽한 분류 자에 해당하는 점이 그래프에 어디에 있는지 추측 할 수 있습니까?
예! 데카르트 평면의 좌표(0,1)에 해당하는 ROC 그래프의 왼쪽 상단 모서리에있을 것입니다. 여기에 민감도와 특이성이 모두 가장 높으며 분류자가 모든 양수 및 음수 클래스 포인트를 올바르게 분류합니다.
이해 AUC-ROC 곡선에서는 파이썬
이제 하나,우리는 수동으로 테스트 민감도와 특이성을 위해 모든 임계값 또는 sklearn 작업을 수행한다. 우리는 확실히 후자와 함께 가고 있습니다!
sklearn make_classification 방법을 사용하여 임의의 데이터를 만들어 보겠습니다:
I will 의 성능을 테스트합니다 두 분류에 이 데이터 집합:
Sklearn 는 매우 강력한 방법 roc_curve()계산 ROC 대한 분류의 문제에 초! 그것을 반환합니다 FPR,TPR 및 임계 값:
AUC 점수를 계산할 수 있을 사용하여 roc_auc_score()메서드의 sklearn:
0.9761029411764707 0.9233769727403157
이 코드에서 라이브 코딩 창에 아래
우리는 또한 줄거리 ROC 곡선에 대한 두 개의 알고리즘을 사용하여 matplotlib:
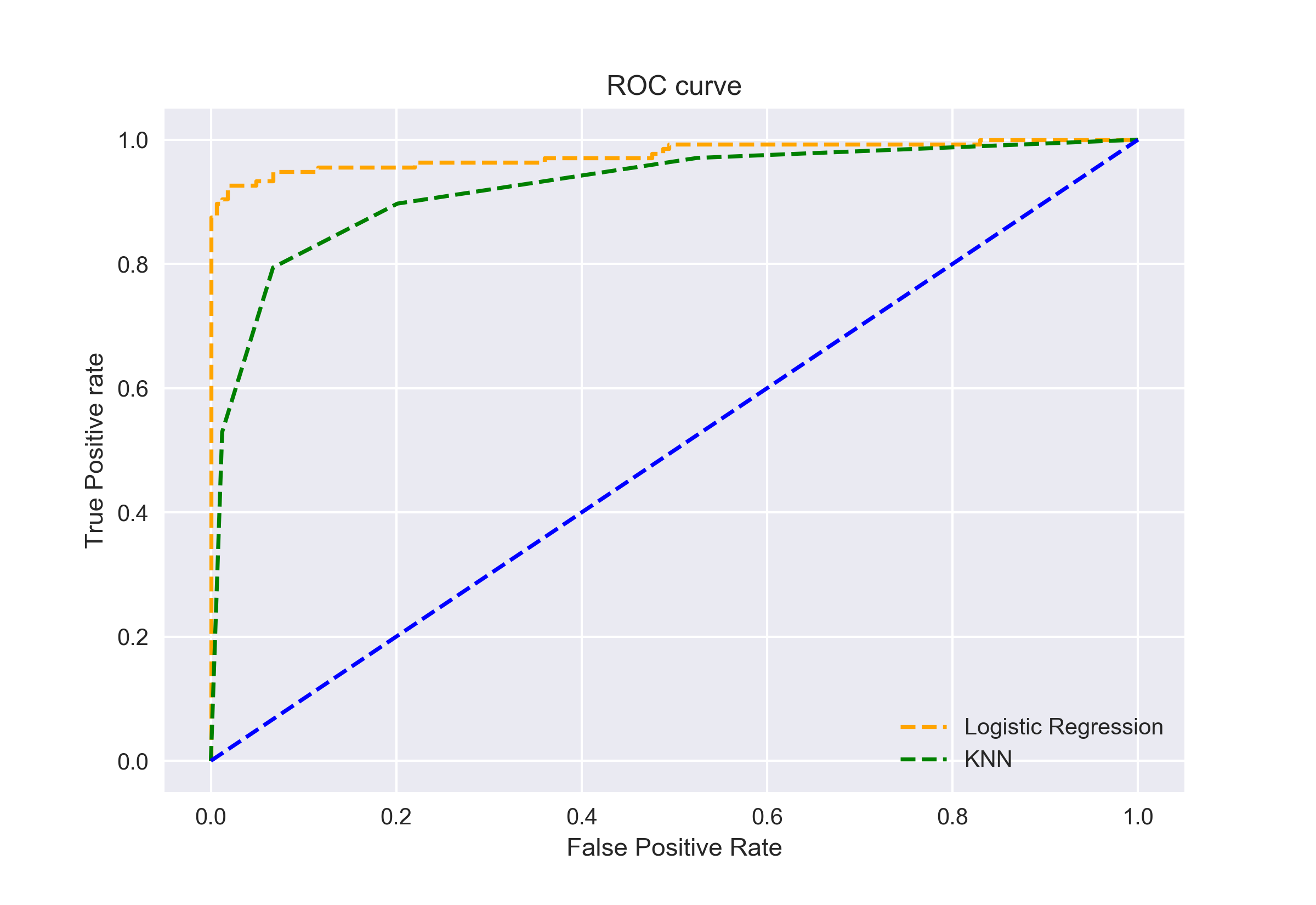
이것은 분명 하에서 음모에 대한 AUC 로지스틱 회귀 ROC 곡선보다 높다는 것에 대한 KNN ROC 곡선입니다. 따라서 로지스틱 회귀가 데이터 세트에서 양의 클래스를 분류하는 더 나은 작업을 수행했다고 말할 수 있습니다.
Auc-ROC 다중 클래스 분류
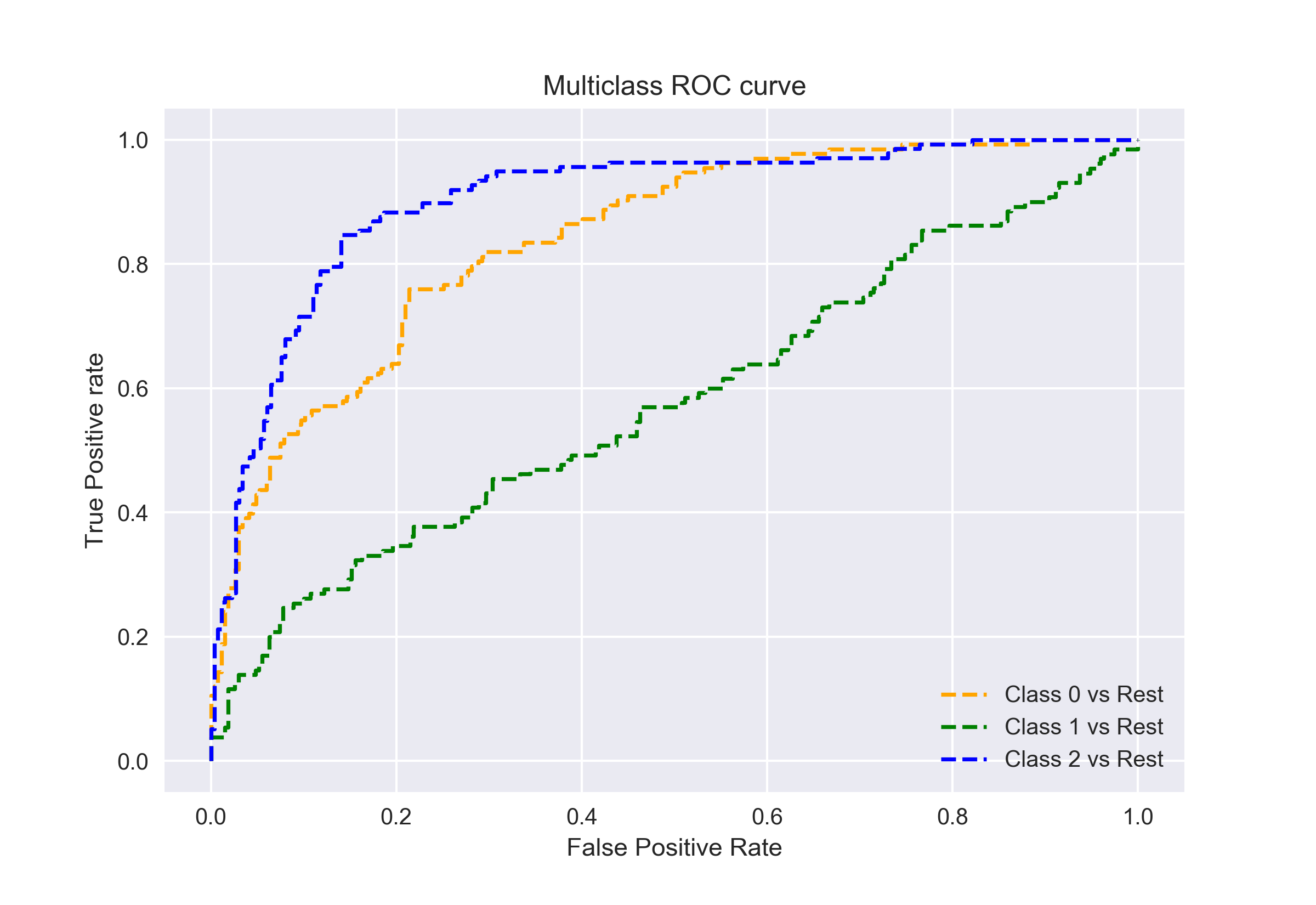
전에 말했듯이 auc-ROC 곡선은 이진 분류 문제에만 해당됩니다. 그러나 우리는 One vs All 기술을 사용하여 multiclass 분류 문제로 확장 할 수 있습니다.
따라서 클래스 0,1 및 2 가 3 개인 경우 클래스 0 의 ROC 는 0 이 아닌 0,즉 1 과 2 에 대해 0 을 분류하는 것으로 생성됩니다. 클래스 1 의 ROC 는 1 이 아닌 것에 대해 1 을 분류하는 등 생성됩니다.
ROC 곡선을 위해 멀티-class 분류 모델을 결정할 수 있는 아래와 같이
끝 주
나는 당신이 문서를 발견 유용하는 방법을 이해하는 강력한 AUC-ROC curve 메트릭은 성능을 측정하기 위한 분류. 업계 및 데이터 과학 또는 기계 학습 해커 톤에서도 많이 사용하게 될 것입니다. 더 잘 익숙해 지십시오!
더가는 것이 좋습니다 당신은 다음과 같은 과정에서 도움이 될 것입니다 건물의 데이터 과학을 통찰력:
- 소개하는 데이터 과학
- 적용한 기계 학습
읽을 수도 있습니다 이 문서에서 우리의 모바일 앱![]()

Leave a Reply