Curva AUC-ROC nell’apprendimento automatico Chiaramente Spiegata
Curva AUC-ROC-La Star Performer!
Hai costruito il tuo modello di apprendimento automatico-quindi quali sono le prospettive? È necessario valutarlo e convalidare quanto sia buono (o cattivo), in modo da poter decidere se implementarlo. Ecco dove entra in gioco la curva AUC-ROC.
Il nome potrebbe essere un boccone, ma sta solo dicendo che stiamo calcolando l ‘ “Area Sotto la curva” (AUC) di “Receiver Characteristic Operator” (ROC). Confuso? Ti sento! Sono stato nei tuoi panni. Ma non preoccupatevi, vedremo cosa significano questi termini in dettaglio e tutto sarà un pezzo di torta!

Per ora, basta sapere che la curva AUC-ROC ci aiuta a visualizzare quanto bene il nostro classificatore di apprendimento automatico sta eseguendo. Sebbene funzioni solo per problemi di classificazione binaria, vedremo verso la fine come possiamo estenderlo per valutare anche i problemi di classificazione multi-classe.
Tratteremo argomenti come sensibilità e specificità, poiché questi sono argomenti chiave dietro la curva AUC-ROC.
Suggerisco di passare attraverso l’articolo su Confusion Matrix in quanto introdurrà alcuni termini importanti che useremo in questo articolo.
Sommario
- Quali sono la sensibilità e la specificità?
- Probabilità di previsioni
- Qual è la curva AUC-ROC?
- Come funziona la curva AUC-ROC?
- AUC-ROC in Python
- AUC-ROC per la classificazione multi-classe
Quali sono la sensibilità e la specificità?
Ecco come appare una matrice di confusione:
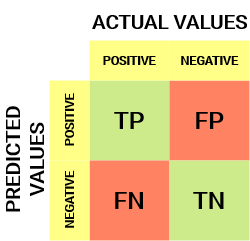
Dalla matrice di confusione, possiamo ricavare alcune metriche importanti che non sono state discusse nell’articolo precedente. Parliamo di loro qui.
Sensitivity / True Positive Rate / Recall
![]()
Sensitivity ci dice quale proporzione della classe positiva è stata correttamente classificata.
Un semplice esempio potrebbe essere quello di determinare quale percentuale delle persone malate effettive sia stata correttamente rilevata dal modello.
Tasso falso negativo
![]()
Il tasso falso negativo (FNR) ci dice quale proporzione della classe positiva è stata erroneamente classificata dal classificatore.
Un TPR più alto e un FNR più basso sono desiderabili poiché vogliamo classificare correttamente la classe positiva.
Specificità/Tasso negativo vero
![]()
La specificità ci dice quale proporzione della classe negativa è stata classificata correttamente.
Prendendo lo stesso esempio della Sensibilità, la specificità significherebbe determinare la proporzione di persone sane che sono state correttamente identificate dal modello.
Tasso di falsi positivi
![]()
FPR ci dice quale proporzione della classe negativa è stata erroneamente classificata dal classificatore.
Un TNR più alto e un FPR più basso sono desiderabili poiché vogliamo classificare correttamente la classe negativa.
Di queste metriche, la sensibilità e la specificità sono forse le più importanti e vedremo più avanti come queste vengono utilizzate per costruire una metrica di valutazione. Ma prima di questo, capiamo perché la probabilità di previsione è migliore della previsione diretta della classe di destinazione.
Probabilità di previsioni
Un modello di classificazione di apprendimento automatico può essere utilizzato per prevedere direttamente la classe effettiva del punto dati o prevedere la sua probabilità di appartenenza a classi diverse. Quest’ultimo ci dà più controllo sul risultato. Possiamo determinare la nostra soglia per interpretare il risultato del classificatore. Questo a volte è più prudente della semplice costruzione di un modello completamente nuovo!
L’impostazione di soglie diverse per la classificazione della classe positiva per i punti dati cambierà inavvertitamente la sensibilità e la specificità del modello. E una di queste soglie probabilmente darà un risultato migliore delle altre, a seconda che stiamo puntando ad abbassare il numero di Falsi negativi o Falsi positivi.
Dai un’occhiata alla tabella sottostante:
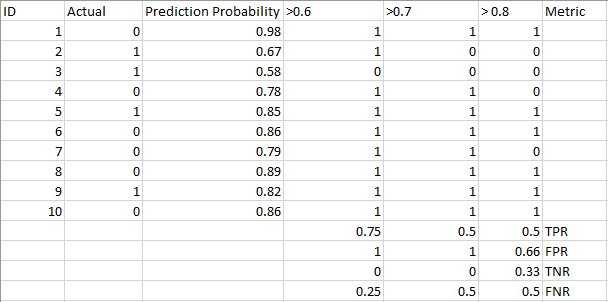
Le metriche cambiano con i valori di soglia che cambiano. Possiamo generare diverse matrici di confusione e confrontare le varie metriche che abbiamo discusso nella sezione precedente. Ma non sarebbe una cosa prudente da fare. Invece, quello che possiamo fare è generare una trama tra alcune di queste metriche in modo che possiamo facilmente visualizzare quale soglia ci sta dando un risultato migliore.
La curva AUC-ROC risolve proprio questo problema!
Qual è la curva AUC-ROC?
La curva ROC (Receiver Operator Characteristic) è una metrica di valutazione per problemi di classificazione binaria. È una curva di probabilità che traccia il TPR contro FPR a vari valori di soglia e separa essenzialmente il “segnale” dal “rumore”. L’Area sotto la curva (AUC) è la misura della capacità di un classificatore di distinguere tra classi e viene utilizzata come riepilogo della curva ROC.
Maggiore è l’AUC, migliori sono le prestazioni del modello nel distinguere tra le classi positive e negative.
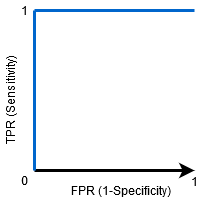
Quando AUC = 1, il classificatore è in grado di distinguere perfettamente correttamente tutti i punti di classe positivi e negativi. Se, tuttavia, l’AUC fosse stata 0, il classificatore avrebbe predetto tutti i Negativi come positivi e tutti i positivi come negativi.
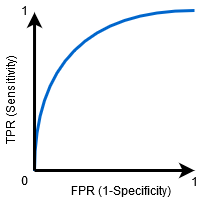
Quando 0.5 <AUC<1, c’è un’alta probabilità che il classificatore sia in grado di distinguere i valori di classe positivi dai valori di classe negativi. Questo perché il classificatore è in grado di rilevare più numeri di Veri positivi e veri negativi rispetto ai falsi negativi e ai falsi positivi.
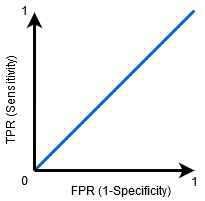
Quando AUC=0.5, il classificatore non è in grado di distinguere tra punti di classe positivi e negativi. Significa che il classificatore prevede una classe casuale o una classe costante per tutti i punti dati.
Quindi, maggiore è il valore AUC per un classificatore, migliore è la sua capacità di distinguere tra classi positive e negative.
Come funziona la curva AUC-ROC?
In una curva ROC, un valore dell’asse X più alto indica un numero maggiore di Falsi positivi rispetto ai Veri negativi. Mentre un valore dell’asse Y più alto indica un numero maggiore di Veri positivi rispetto ai Falsi negativi. Quindi, la scelta della soglia dipende dalla capacità di bilanciare tra falsi positivi e Falsi negativi.
Scaviamo un po ‘ più a fondo e capiamo come apparirebbe la nostra curva ROC per diversi valori di soglia e come varierebbero la specificità e la sensibilità.
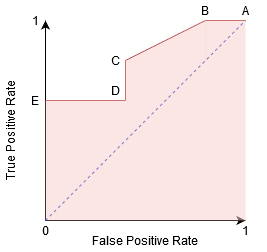
Possiamo provare a capire questo grafico generando una confusione matrice per ogni punto corrispondente a un valore di soglia e parlare delle prestazioni dei nostri classificazione:
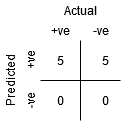
il Punto è dove la Sensibilità è la più alta e la Specificità più basso. Ciò significa che tutti i punti di classe positivi sono classificati correttamente e tutti i punti di classe negativi sono classificati in modo errato.
In effetti, qualsiasi punto sulla linea blu corrisponde a una situazione in cui il tasso vero positivo è uguale al tasso falso positivo.
Tutti i punti sopra questa linea corrispondono alla situazione in cui la proporzione di punti correttamente classificati appartenenti alla classe Positiva è maggiore della proporzione di punti erroneamente classificati appartenenti alla classe Negativa.
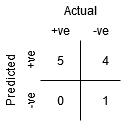
Sebbene il punto B abbia la stessa Sensibilità del punto A, ha una specificità maggiore. Significa che il numero di punti di classe non correttamente negativi è inferiore rispetto alla soglia precedente. Ciò indica che questa soglia è migliore della precedente.
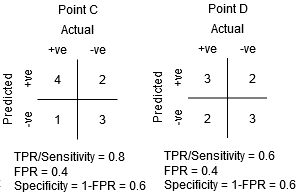
Tra i punti C e D, la sensibilità al punto C è superiore al punto D per la stessa specificità. Ciò significa che, per lo stesso numero di punti di classe negativi classificati in modo errato, il classificatore ha previsto un numero maggiore di punti di classe positivi. Pertanto, la soglia al punto C è migliore del punto D.
Ora, a seconda di quanti punti classificati in modo errato vogliamo tollerare per il nostro classificatore, sceglieremo tra il punto B o C per prevedere se puoi sconfiggermi in PUBG o meno.
“Le false speranze sono più pericolose delle paure.”- J. R. R. Tolkein

Il punto E è dove la Specificità diventa più alta. Significa che non ci sono falsi positivi classificati dal modello. Il modello può classificare correttamente tutti i punti di classe negativi! Sceglieremmo questo punto se il nostro problema fosse quello di dare consigli di canzoni perfette ai nostri utenti.
Seguendo questa logica, puoi indovinare dove si troverebbe il punto corrispondente a un classificatore perfetto sul grafico?
Sì! Sarebbe nell’angolo in alto a sinistra del grafico ROC corrispondente alla coordinata (0, 1) nel piano cartesiano. È qui che entrambi, la Sensibilità e la Specificità, sarebbero i più alti e il classificatore classificherebbe correttamente tutti i punti di classe positivi e Negativi.
Comprendere la curva AUC-ROC in Python
Ora, o possiamo testare manualmente la sensibilità e la specificità per ogni soglia o lasciare che sklearn faccia il lavoro per noi. Stiamo sicuramente andando con quest’ultimo!
Creiamo i nostri dati arbitrari usando il metodo sklearn make_classification:
Testerò le prestazioni di due classificatori su questo set di dati:
Sklearn ha un metodo molto potente roc_curve() che calcola il ROC per il tuo classificatore in pochi secondi! Restituisce i valori FPR, TPR e threshold:
Il punteggio AUC può essere calcolato usando il metodo roc_auc_score() di sklearn:
0.9761029411764707 0.9233769727403157
Prova questo codice nella finestra live coding qui sotto:
Possiamo anche tracciare le curve ROC per i due algoritmi usando matplotlib:
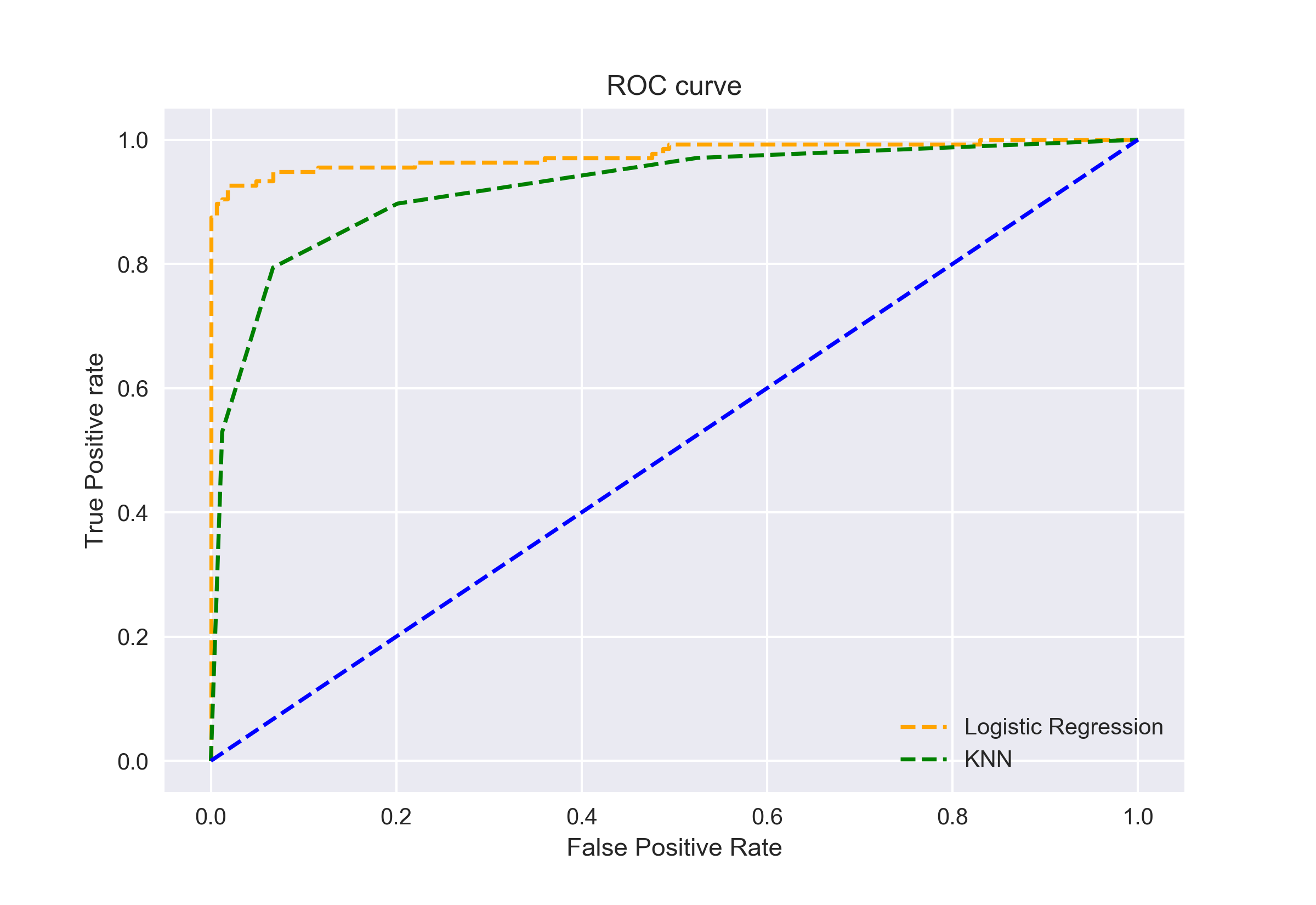
È evidente dal grafico che l’AUC per la curva ROC di regressione logistica è superiore a quella per la curva ROC KNN. Pertanto, possiamo dire che la regressione logistica ha fatto un lavoro migliore nel classificare la classe positiva nel set di dati.
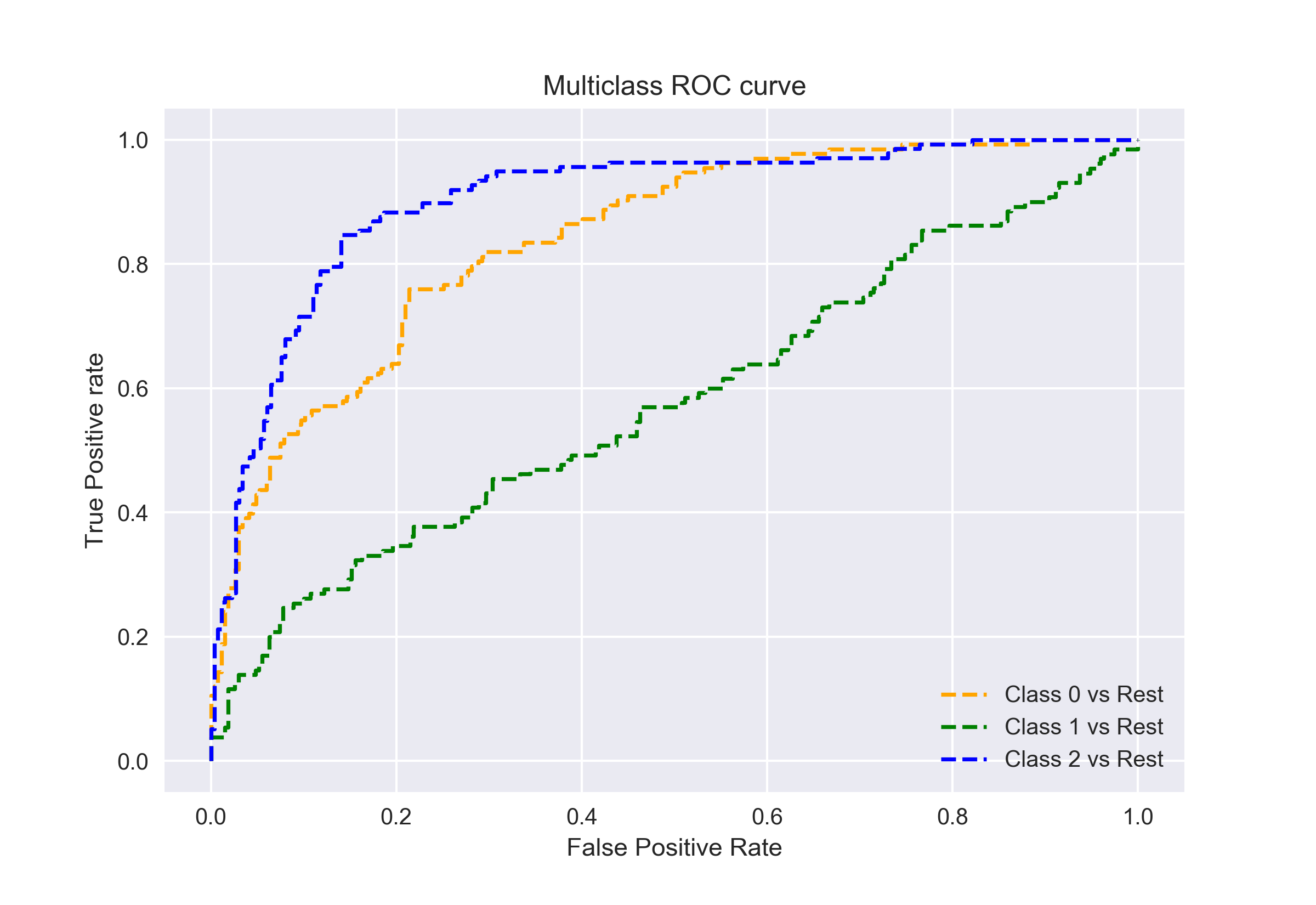
AUC-ROC per la classificazione multi-classe
Come ho detto prima, la curva AUC-ROC è solo per problemi di classificazione binaria. Ma possiamo estenderlo ai problemi di classificazione multiclasse usando la tecnica One vs All.
Quindi, se abbiamo tre classi 0, 1 e 2, il ROC per la classe 0 verrà generato come classificazione 0 contro non 0, cioè 1 e 2. Il ROC per la classe 1 verrà generato come classificazione 1 contro non 1 e così via.
La curva ROC per i modelli di classificazione multi-classe può essere determinata come di seguito:
Note finali
Spero che tu abbia trovato questo articolo utile per capire quanto sia potente la metrica della curva AUC-ROC nel misurare le prestazioni di un classificatore. Lo userai molto nel settore e persino negli hackathon di data science o machine learning. Meglio familiarizzare con esso!
Andando avanti, ti consiglierei i seguenti corsi che saranno utili nella creazione di un data science di acume:
- Introduzione alla Scienza di Dati
- Applicare Apprendimento automatico
puoi leggere anche questo articolo sulla nostra APP Mobile![]()

Leave a Reply