평균,중앙값,모드,범위 계산기
계산하려면 쉼표로 구분 된 숫자를 제공하십시오.
관련 통계산|표준 편차를 계산기|는 샘플 크기 계산기
의미
단어를 의미있는 동음 이의어의를 위해 여러 다른 단어,영어도 마찬가지로 모호한도의 영역에서 수학했다. 문맥에 따라,수학적 또는 통계적 여부에 관계없이”평균”이 의미하는 것이 변경됩니다. 에서는 가장 간단한 수학적 정의에 관한 데이터 세트,의미로 사용되는 것은 산술 평균으로도 불리는 수학적 기대 또는 평균입니다. 이 양식에서 평균을 말하는 중간 사이의 값이 이산 집합의 숫자,즉,모든 값의 합계에서 데이터 세트로 나눈 총수의 값입니다. 방정식에 대한 계산을 산술 평균은 거의 그것과 동일한 계산을 위한 통계적 개념의 인구와 샘플을 의미,약간의 변형으로서 변수 사용:
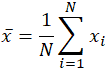
균은 종종로 표시됩 x,발음”x bar,”도에서 다른 사용하면 변하지 않 x,바 표기법의 일반적인 지표의 일부 양식을 의미합니다. 모집단 평균의 특정 경우에는 변수 x 를 사용하는 대신 그리스어 기호 mu 또는 μ 가 사용됩니다. 유사하게,또는 오히려 혼란스럽게,통계의 샘플 평균은 종종 자본 X 로 표시됩니다. 주어진 데이터 세트 10, 2, 38, 23, 38, 23, 21, 수익률 위의 합계 적용:
|
10 + 2 + 38 + 23 + 38 + 23 + 21 |
= | =22.143 |
이전에 언급한,이것은 하나의 가장 간단한 정의의 의미,그리고 일부는 다른 사람 포함 산술 평균 가중(단지 다르다는 점에서 특정 값을 데이터세트에 기여 보다 더 많은 가치를 다른 사람),그리고 기하학적인 의미합니다. 의 올바른 이해를 주어진 상황과 상황을 제공할 수 있는 사람이 필요한 도구가 무엇인지 결정하는 통계적으로 관련 방법을 사용합니다. 일반적으로,평균값,중앙값과 범위 이상적으로 모든 계산 및 분석된 특정한 샘플 또는 데이터 설정 이후 그들은 명료의 다양한 측면은 주어진 데이터,그리고 간주 하는 경우,혼자 이어질 수 있는 허위 진술,데이터의로 설명 될 것이에서 다음과 같은 섹션을 포함합니다.
중간
통계적 개념의 평균 값을 나누는 데이터 견본,인구,또는 확률 분포로 두 부분으로 나누어집니다. 중간을 찾는 기본적으로 포함 찾기 값을 데이터 샘플에서는 물리적 위치 사이의 나머지 숫자입니다. 유한 숫자 목록의 중앙값을 계산할 때 데이터 샘플의 순서가 중요하다는 점에 유의하십시오. 일반적으로 값은 오름차순으로 나열되지만 내림차순으로 값을 나열하면 다른 결과를 제공 할 실제 이유는 없습니다. 데이터 샘플의 총 값 수가 홀수 인 경우 중앙값은 단순히 모든 값 목록의 중간에있는 숫자입니다. 데이터 샘플에 짝수 개의 값이 포함되면 중앙값은 두 개의 중간 값의 평균입니다. 이 혼동 될 수 있습니다,단순히 기억하는 것도 중간 때때로 포함한 계산의 말은,이 사건이 발생했을,포함 할 것이 단 두 가지 중간에 값이면서,평균을 포함한 모든 값을 데이터 샘플입니다. 에서 이상한 사례가 있는 두 개의 데이터 샘플나가 짝수 샘플의 모든 값들은 동일한 의미와 중 같은 것입니다. 정 같은 데이터로 설정하기 전에,평균 것입 취득은 다음과 같은 방법으로.
2,10,21,23,23,38,38
나열 후에 데이터을 오름차순으로 결정이 있다는 홀수의 값을,그것은 분명하다는 23 일이 중간 이 경우입니다. 데이터 세트에 다른 값이 추가 된 경우:
2,10,21,23,23,38,38,1027892
있기 때문에 짝수 값의 평균이 될 것이다 평균 가운데 두 번호,이 경우 23 23,의 의미 있는 23. 이는 특정 데이터 세트를 추가 특이치(값으로 예상되는 값의 범위),가치 1,027,892,진짜에 효과 데이터를 설정합니다. 그러나이 데이터 세트에 대해 평균이 계산되면 결과는 128,505.875 입니다. 이 값은 명확하지 않는 좋은 표현의 다른 값을 설정한 데이터는 훨씬 작고 가까이에서 값보다 평균 그리고 특. 이것은 평균과 비교할 때 통계 데이터를 설명하는 데 중앙값을 사용하는 주요 이점입니다. 모두 동안뿐만 아니라,기타 통계 값을 계산해야 할 때 데이터를 설명하는 경우에는 사용할 수 있습니다,평균을 제공할 수 있는 더 나은 추정치의 일반적인 값에서 특정 데이터 세트가 있을 때 매우 큰 변화 사이의 값이다.
모드
통계에서 모드는 재발 횟수가 가장 높은 데이터 세트의 값입니다. 데이터 세트가 다중 모드 일 수 있으므로 둘 이상의 모드가 있음을 의미합니다. 예:
2,10,21,23,23,38,38
23 과 38 모두 각각 두 번 나타나며 위의 데이터 세트에 대한 모드가됩니다.
평균 및 중앙값과 유사하게 모드는 무작위 변수 및 모집단에 대한 정보를 표현하는 방법으로 사용됩니다. 달리 의미와 중간 그러나,모드는 개념에 적용할 수 있는 비 숫자 값과 같이 브랜드의 옥수수 칩 가장 일반적으로 구매에서 식료품 가게가 있었습니다. 예를 들어,비교할 때 브랜드 Tostitos,임무 및 XOCHiTL,발견되는 경우에는 판매의 옥수수 칩,XOCHiTL 형태 그리고 판매에서 3:2:1 비율의 비교를 Tostitos 고무 브랜드 또띠아 칩,각각의 비율이 될 수 있는 방법을 결정하는 데 사용됩 많은 가방 각각의 브랜드를 주식. 는 경우 24 부대의 옥수수 칩 판매하는 지정된 기간 동안,상점 재고 12 가방 XOCHiTL 칩,8 의 Tostitos,4 개의 미션을 사용하는 경우 모드입니다. 그러나 저는 단순히 사용되는 평균 판매 8 방의 각,이것을 잃게 4 개의 판매하는 경우 고객이 원하는만 XOCHiTL 칩과하지 않는 모든 다른 브랜드입니다. 이 예에서 알 수 있듯이 모든 데이터 샘플에 대한 결론을 도출하려고 할 때 통계 값의 모든 매너를 고려하는 것이 중요합니다.
범위
범위의 데이터 설정에서 통계 간의 차이입니다 가장 크고 가장 작은 값입니다. 동 범위는 다른 의미 내에서의 서로 다른 영역 및 통계학,이것은 가장 기본적인 정의와 사용되는 것에 의해 제공되는 계산기입니다. 를 사용하여 동일한 예제:
2,10,21,23,23,38,38
38-2=36
범위에서 이 예제는 36. 평균과 유사하게 범위는 매우 크거나 작은 값에 의해 크게 영향을받을 수 있습니다. 이전 예제와 동일한 예제 사용:
Leave a Reply