설명자:L1 대 L2 대 L3 캐시
Every single CPU 에서 발견되는 모든 컴퓨터에서 저렴한 노트북 백만 달러의 서버가 있을 것이라는 것 캐시입니다. 그렇지 않은 것보다 더 많은 가능성도 여러 수준을 보유하게됩니다.
그것은 중요해야합니다,그렇지 않으면 왜 거기에있을 것입니까? 그러나 캐시는 무엇을합니까,왜 물건의 다른 수준의 필요? 지구상에서 12 웨이 세트 연관성조차도 무엇을 의미합니까?
캐시 란 정확히 무엇입니까?
TL;DR:cpu 의 로직 유닛 바로 옆에 앉아있는 작지만 매우 빠른 메모리입니다.
그러나 물론 캐시에 대해 배울 수있는 것이 훨씬 더 많습니다…
으로 시작되자 상상 속의 마법의 저장 시스템은:그것은 무한히 빠르게 처리할 수 있습니다 무한한 수의 데이터 트랜잭션에서 한 번,그리고 항상 유지한 데이터 안전하고 있습니다. 이 심지어 원격으로 아무것도 존재하지 않는 것이 아니라,그렇게한다면,프로세서 디자인은 훨씬 간단 할 것이다.
Cpu 는 추가,곱하기 등을위한 논리 단위 만 있으면됩니다. 그리고 데이터 전송을 처리하는 시스템. 이는 이론적 인 스토리지 시스템이 필요한 모든 번호를 즉시 보내고받을 수 있기 때문입니다; 논리 단위 중 어느 것도 데이터 트랜잭션을 기다리는 동안 유지되지 않습니다.그러나 우리 모두가 알고 있듯이 마법 저장 기술은 없습니다. 대신에,우리는 하드 또는 솔리드 스테이트 드라이브,심지어 가장 좋지 않습도 원격으로 처리할 수 있는 모든 데이터 전송에 필요한 일반적인 CPU.
The Great T’Phon 의 데이터 저장
는 이유는 현대 Cpu 에는 믿을 수 없을만큼 빨리-그들을 그냥 하나의 클럭 사이클을 추가 두 64 비트의 정수 값을 함께하고,CPU 에 실행되는 4GHz,이 0.000000000025 초 또는 나노초의 1/4.
한편,회전 하드 드라이브의 수천을 그냥 나노초 데이터를 찾을 디스크에 내부에 혼자 전송과 솔리드 스테이트 드라이브는 여전히 수십 또는 수백 개의 나노초입니다.
이러한 드라이브는 분명히 프로세서에 내장 할 수 없으므로 둘 사이에 물리적 분리가있을 것임을 의미합니다. 이것은 단지 데이터의 이동에 더 많은 시간을 추가하여 상황을 더욱 악화시킵니다.

좋은 ‘Tuin 데이터의 저장,슬프게도
그래서 우리가 필요한 것은 또다른 데이터 저장 시스템,그 사이에 앉아 프로세서 및 주장입니다. 드라이브보다 빠르며 동시에 많은 데이터 전송을 처리 할 수 있어야하며 프로세서에 훨씬 가까워 야합니다.
음,우리는 이미지가 같은 것,그리고 그것은이라고 RAM,그리고 모든 컴퓨터 시스템에 대한 몇 가지 있습니다.
거의 모든 종류의 스토리지는 DRAM(dynamic random access memory)이며 어떤 드라이브보다 훨씬 빠르게 데이터를 전달할 수 있습니다.
동안 그러나,DRAM 슈퍼 빠른 저장할 수 없습 근처에 많은 데이터입니다.
일부의 가장 큰 DDR4 메모리 칩에 의해 만들어인 마이크론 하나의 몇 가지 제조업체의 DRAM,보 32 기가비트 또는 4GB 데이터의 가장 큰 하드 드라이브를 개최 4,000 보다 더 많은 시간이다.
그렇지만 우리의 속도를 향상 우리의 데이터 네트워크,추가 시스템-하드웨어 및 소프트웨어-기 위해 필요한 것입을 어떻게 데이터를 보관해야에서의 제한된 양의 DRAM,에 대한 준비했다.
적어도 DRAM 은 칩 패키지(임베디드 DRAM 이라고도 함)로 제조 될 수 있습니다. Cpu 는 꽤 작은,하지만,그래서 당신은 그들에 그 정도 스틱 수 없습니다.xbox360 의 그래픽 프로세서 왼쪽에 10MB 의 DRAM 이 있습니다. 원:CPU 원
대부분의 DRAM 은 바로 옆에 위치하고 있으며 프로세서에 꽂혀 있는 마더보드,그리고 그것은 항상 가장 가까운 구성 요소 또는 프로그램을 만에 컴퓨터 시스템입니다. 그럼에도 불구하고 여전히 충분히 빠르지는 않습니다…
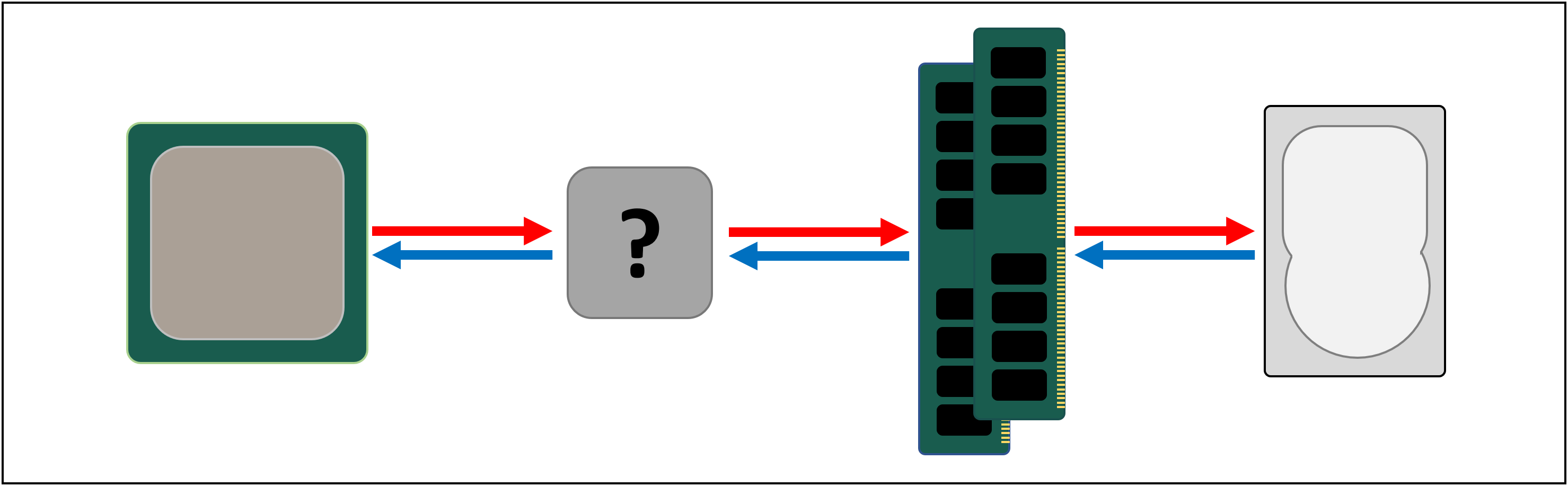
DRAM 은 여전히 데이터를 찾는 데 약 100 나노초가 걸리지 만 적어도 매초 수십억 비트를 전송할 수 있습니다. 프로세서의 유닛과 DRAM 사이에 들어가려면 다른 메모리 단계가 필요할 것 같습니다.
단계 왼쪽 입력:sram(정적 랜덤 액세스 메모리). 어디에 DRAM 을 사용하여 미세한 커패시터에 데이터를 저장 형태의 전기료,SRAM 사용하여 트랜지스터 같은 일을 하고 이러한 일할 수 있는 기반으로 한 새로운 로직 유닛에서 프로세서(약 10 배 이상 빠른 DRAM).
물론 SRAM 에 단점이 있으며 다시 한 번 공간에 관한 것입니다.
트랜지스터를 기반으로 하는 메모리를 소요하보다 더 많은 공간을 DRAM:을 위해 동일한 크기 4GB DDR4 칩,당신을 얻을 것보다 100MB 의 가치가 SRAM. 그러나 그 이후의 통해와 동일한 프로세스를 만드는 CPU,SRAM 구축할 수 있습 마우스 오른쪽 내부 프로세서 가까운 로직 유닛으로 가능합니다.
트랜지스터를 기반으로 하는 메모리를 소요하보다 더 많은 공간을 DRAM:을 위해 동일한 크기 4GB DDR4 칩,당신을 얻을 것보다 100MB 의 가치가 SRAM.
각 여분의 무대,우리 증가하는 속도의 데이터 이동에 대한 비용이 얼마나 우리가 저장할 수 있습니다. 우리는 각자가 더 빠르지 만 더 작아서 더 많은 섹션을 계속 추가 할 수 있습니다.
고 그래서 우리는 우리에 도착 더 자세한 기술의 정의는 무엇 캐시이다:그것은 여러 개의 블록을 SRAM,모든 위치한 내부 프로세서,그들은 보장하기 위해 사용되는 논리 단위로 유지 바로 가능하여 전송 및 데이터 저장에 슈퍼 빠른 속도입니다. 그걸로 행복해? 좋은–왜냐하면 그것은 여기에서 훨씬 더 복잡해 질 것이기 때문입니다!
캐시: 다단계 주차장을
로는 우리가 논의 캐시 필요 없기 때문에 마법의 스토리지 시스템과 함께 유지할 수 있는 데이터 요구의 논리 단위에서 프로세서입니다. 현대 Cpu 과 그래픽 프로세서의 숫자를 포함 SRAM 블록,그것은 내부적으로 계층 구조로 구성됩–의 순서 캐시 주문한 다음과 같다:

위의 이미지,CPU 로 표시되는 검은 점선 사각형입니다. ALUs(산술 논리 단위)는 맨 왼쪽에 있습니다; 이들은 칩이하는 수학을 처리하면서 프로세서에 전원을 공급하는 구조입니다. 기술적으로 캐시는 아니지만 ALUs 에 가장 가까운 메모리 수준은 레지스터입니다(레지스터 파일로 함께 그룹화됩니다).
각각 하나의 이유는 하나의 숫자와 같은 64 비트의 정수는 값은 그 자체이 될 수 있습의 데이터에 대해 뭔가 코드에 대한 특정 명령어나 메모리 주소의 일부는 다른 데이터입니다.
등록 파일에서 바탕 화면 CPU 는 매우 작은–예를 들면,인텔의 핵심 i9-9900K,두 개의 은행에서 그들의 각각의 핵심이며,하나를 위해 정수만 포함 180 64 비트 레지스터가 있습니다. 벡터(작은 숫자 배열)의 다른 레지스터 파일에는 168 개의 256 비트 항목이 있습니다. 따라서 각 코어의 총 레지스터 파일은 7kb 미만입니다. 이에 비해 Nvidia GeForce RTX2080Ti 의 스트리밍 멀티 프로세서(CPU 코어에 해당하는 GPU)의 레지스터 파일 크기는 256kb 입니다.
레지스터는 SRAM,처럼 캐시이지만,그만큼 빠르게 ALUs 그들은 봉사를 밀어,데이터는 단일 클럭 사이클. 하지만 그들은 개최하도록 설계되지 않았습니다 아주 많이 데이터(단지 하나의 그것의 조각),는 이유는 항상 거기에 몇 가지 더 큰 블록의 메모리:인근 이 레벨 1 캐시입니다.
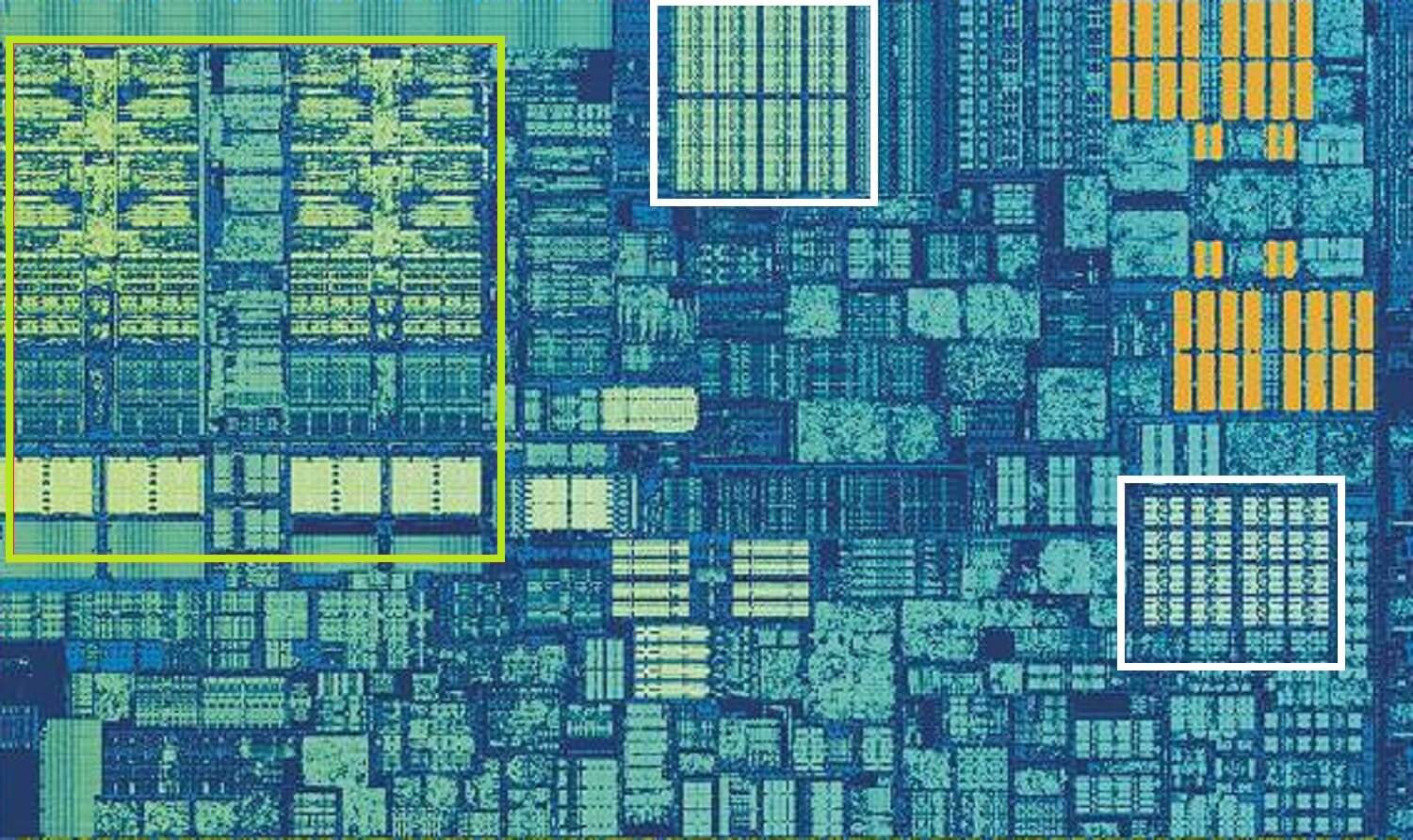
인텔 스카이 레이크 CPU,확대 촬영의 핵심입니다. 출처:Wikichip
위의 이미지는 Intel 의 Skylake 데스크탑 프로세서 디자인에서 단일 코어를 확대 한 샷입니다.
ALUs 와 레지스터 파일은 맨 왼쪽에서 볼 수 있으며 녹색으로 강조 표시됩니다. 그림의 상단-중간에는 흰색으로 레벨 1 데이터 캐시가 있습니다. 이 보전되지 않는 정보,막 32kB 지만,등록,그것은 매우 가까운 로직 유닛과에서 실행되는 동일한 속도로 그들이다.
다른 흰색 사각형은 레벨 1 명령어 캐시를 나타내며 크기는 32kb 입니다. 그 이름에서 알 수 있듯이 이 상점이 다양한 명령을 준비하는 것으로 나누어 작은,그래서 소위 마이크로 작업(일반적으로 붙여 µops),에 대한 ALUs 를 수행할 수 있습니다. 그들에게도 캐시가 있으며 l1 캐시보다 작고(1,500 개의 작업 만 유지)더 가깝기 때문에 레벨 0 으로 분류 할 수 있습니다.
SRAM 의 이러한 블록이 왜 그렇게 작은지 궁금 할 것입니다. 함께,데이터와 지 캐시 거의 동일한 공간의 칩으로 주요 논리 단위로,그래서 그들을 더 크게 만드는 것이 늘리의 전체 크기는 죽습니다.그러나 몇 kB 만 보유하고있는 주된 이유는 메모리 용량이 커짐에 따라 데이터를 찾고 검색하는 데 필요한 시간이 증가한다는 것입니다. L1 캐시될 필요가 정말 빠르게,그리고 그렇게 타협 도달 할 수 있어야 사이 크기고 속도에서 최고의,그것은 5 주위 사이클 시계(상에 대한 부동 소수점의 값)을 얻는 데이터의 이 캐시를 사용할 준비가 되었습니다.
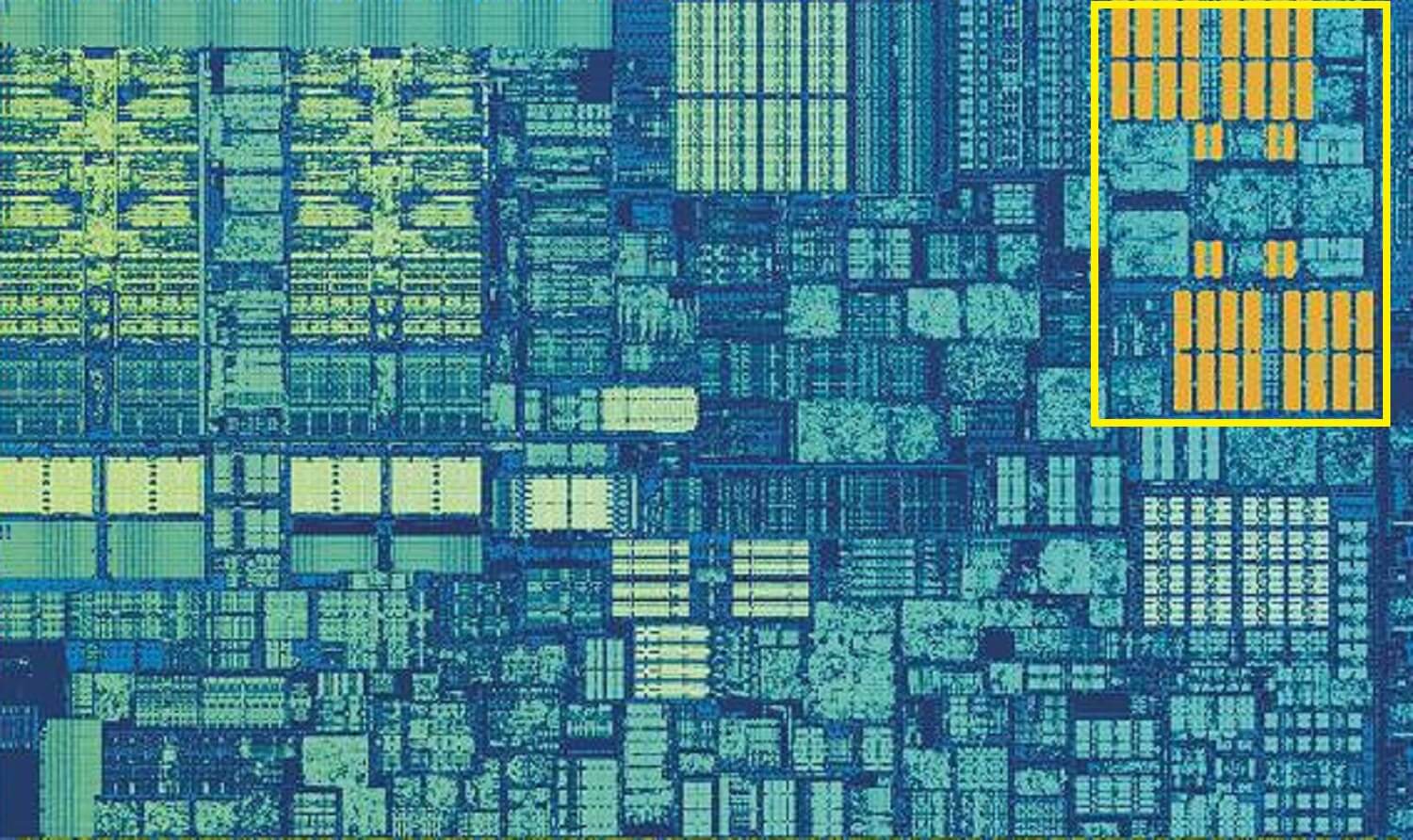
스카이 레이크의 L2 캐시:256kB 의 SRAM 선
이 경우 그러나이었 캐시 내부 프로세서,다음의 성능을 칠 것 갑작스런 벽입니다. 이것이 모두 코어에 내장 된 또 다른 수준의 메모리를 가지고있는 이유입니다:레벨 2 캐시. 이것은 지침과 데이터를 유지하는 일반적인 저장 블록입니다.
항상 꽤 보다 큰 수준 1:AMD 선 프로세서 2 팩 512kB 다,그래서 낮은 수준 캐시할 수 있습이 잘 유지되어 공급됩니다. 이 추가 크기는 비용이 많이 들지만 레벨 1 에 비해이 캐시에서 데이터를 찾아 전송하는 데 약 두 배의 시간이 걸립니다.
시에서 시간을 원래의 인텔 펜티엄,레벨 2 캐시던 별도의 칩을 하나의 작은 플러그인 회로 기판(처럼 램 DIMM)또는 내장된 기본 마더보드. 결국 펜티엄 III 와 AMD K6-III 프로세서의 좋아하는에,마지막으로 CPU 다이에 통합 될 때까지,CPU 패키지 자체에 그것의 방법을 일했다.
이 개발이 곧 다른 수준의 캐시기를 지원하는 다른 낮은 수준,그것에 대해 상승으로 인해 멀티 코어 칩이 있습니다.

인텔 Kaby 호수 칩. 출처:Wikichip
이 이미지는 Intel Kaby 호 칩,4 개의 코어에서 왼쪽 중간(통합 GPU 걸리는 최대의 거의 절반이 죽을,오른쪽에서). 각 코어에는 자체’개인’레벨 1 및 2 캐시 세트(흰색 및 노란색 하이라이트)가 있지만 세 번째 SRAM 블록 세트도 함께 제공됩니다.
레벨 3 캐시더라도,그것은 바로 하나의 핵심은 완전히 다른 사람과 공유–수 있습니다 각각의 하나는 자유롭게 컨텐츠에 액세스의 다른 사람의 L3 캐시입니다. 그것은 훨씬 더 큰(2 32MB)뿐만 아니라 많은 느리고,평균 30 여기는 경우에 특히 핵심을 사용할 필요가 있는 데이터의 블록에 캐시 일부리는 거리에 있습니다.
아래에서는 AMD 의 Zen2 아키텍처에서 단일 코어를 볼 수 있습니다: 32kb 레벨 1 데이터 및 명령어는 흰색으로 캐시되고 512kb 레벨 2 는 노란색으로 표시되며 거대한 4mb 블록의 l3 캐시는 빨간색으로 표시됩니다.이 문제를 해결하려면 다음 단계를 따르고 싶습니다. 출처:Fritzchens Fritz
잠깐 기다려. 어떻게 32kb 가 512kB 보다 더 많은 물리적 공간을 차지할 수 있습니까? 레벨 1 이 너무 적은 데이터를 보유하고 있다면 l2 또는 L3 캐시보다 비례 적으로 훨씬 큰 이유는 무엇입니까?
보다 더 많
캐시 성능 향상 가속화하여 데이터 전송을 논리 단위 및 복사본을 유지하의 자주 사용하는 지침과 데이터습니다. 정보가 캐시에 저장되는 분할에서 두 부분의 데이터 자체와 있는 곳의 위치를 원래 위치한 시스템에서 메모리/저장소–이소라고 캐시 태그입니다.
CPU 가/에서 메모리로 데이터를 읽거나 쓰려는 작업을 실행하면 레벨 1 캐시의 태그를 확인하여 시작합니다. 필요한 것이 있으면(캐시 적중)해당 데이터에 거의 바로 액세스 할 수 있습니다. 필요한 태그가 가장 낮은 캐시 수준에 있지 않을 때 캐시 미스가 발생합니다.
그래서 새로운 태그를 만들에 L1 캐시고,나머지 프로세서의 아키텍처는 이상,사냥을 통해 다시 다른 캐시준(모든 방법을 저장 드라이브,필요한 경우)을 찾기 위한 데이터는 태그이다. 그러나이 새로운 태그에 대한 L1 캐시에 공간을 확보하려면 다른 것이 항상 l2 로 부팅되어야합니다.
이것은 단지 소수의 클록 사이클에서 달성 된 데이터의 거의 일정한 셔플 링을 초래합니다. 이를 달성하는 유일한 방법은 SRAM 주위에 복잡한 구조를 가짐으로써 데이터의 관리를 처리하는 것입니다. 다른 방법을 넣어: 면 CPU 중핵 구성되어 단 하나의 알루미늄,다음 L1 캐시는 것이 훨씬 간단하지만,이 있기 때문에 그들의 수십(게 될 것이다 많은 것이 저글링은 두 개의 스레드의 지침에),캐시 필요 여러 연결을 유지하는 모든 것을에서 이동합니다.
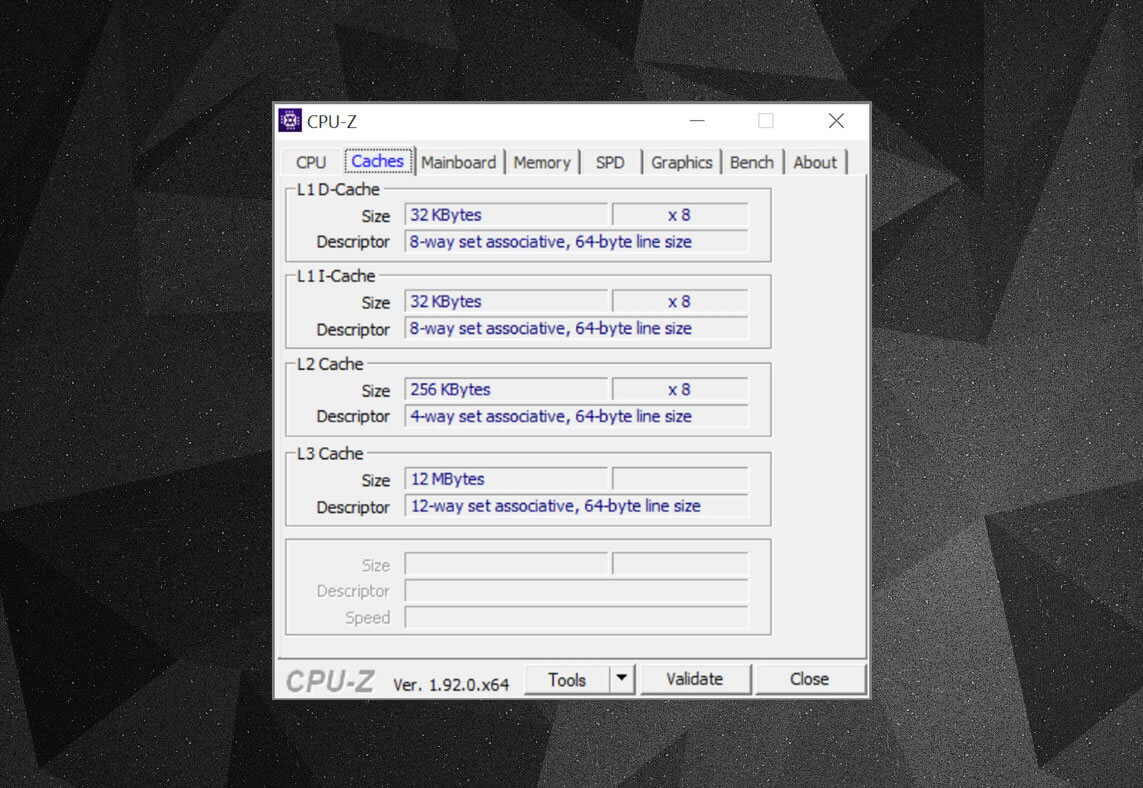
사용할 수 있는 무료 프로그램과 같은 CPU-Z,을 확인하는 캐쉬에 대한 정보를 프로세서를 지원하는 자신의 컴퓨터입니다. 그러나 그 모든 정보는 무엇을 의미합니까? 중요한 요소 라벨을 설정하는 연관–이에 대한 모든 규칙을 적용하여 블록의 시스템에서 데이터 메모리로 복사되 캐시입니다.
위한 캐시 정보는 Intel Core i7-9700K. 레벨 1 캐시 각각으로 분할 64 작은 블록,라 세트,그리고 각각의 하나 이러한으로 더 분할됩니다 캐시 라인(64 바이트로 크기). 트 연합 의미하는 데이터 블록에서 이 시스템 메모리에 매핑된 캐시 라인에서 하나의 특별한 설정,보다는 오히려 무료하지도에서 어디서나.
8 방향 부분은 한 블록이 세트의 8 개의 캐시 라인과 연결될 수 있음을 알려줍니다. 큰 수준의 연관성(즉,’더 방법’),의 더 나은 기회를 얻 캐시 적중할 때 CPU 가 사냥을 위해,데이터 및 감소에서 형벌에 의 캐시를 벗어났습니다. 단점은 그것에 추가 더 복잡성,증가된 전력 소비 및 수 있도 성능이 감소가 있기 때문에 더 캐시선을 위한 프로세스의 데이터 블록.

L1+L2 포함 캐시,L3 피해자 캐시,쓰기 백 정책,심지어 ECC. 소스: Fritzchens Fritz
또 다른 측면에 복잡성을 캐시의 주위에 회귀한 데이터를 어떻게 지켜에 걸쳐 다양한 수준이다. 규칙은 포함 정책이라고하는 것으로 설정됩니다. 예를 들어 Intel Core 프로세서에는 완전히 포함 된 L1+L3 캐시가 있습니다. 즉,예를 들어 레벨 1 의 동일한 데이터가 레벨 3 에있을 수도 있습니다. 이처럼 보일 수도 있다의 낭비하는 소중한 캐시 공간,하지만 활용하는 경우 프로세서 얻을 놓치를 검색할 때 태그에서 더 낮은 수준에,그것은 필요가 없는 사냥을 통해 높은 수준에 그것을 찾을 수 있습니다.
동일한 프로세서에서 L2 캐시는 포함되지 않습니다:거기에 저장된 모든 데이터는 다른 수준으로 복사되지 않습니다. 이 공간을 절약하지만 결과는 칩의 메모리 시스템을 통해 검색할 필요 L3(항상은 훨씬 더 큰)을 찾을 놓친 태그입니다. 피해자 캐시 비슷하지만,이들이 사용하여 저장된 정보 가져오는 밖으로 밀려 낮은 수준–예를 들어,AMD 의 선 2 개 프로세서에서 사용 L3 피해자를 캐쉬는 저장 데이터에서 L2.
데이터가 캐시 및 기본 시스템 메모리에 기록되는 경우와 같이 캐시에 대한 다른 정책이 있습니다. 이라고 쓰기 정책 및 오늘날 대부분의 Cpu 를 사용하여 다시 쓰기 캐시며 이는 때 데이터가 서면으로 캐시 수준,지연이 발생하기 전에 시스템 메모리가 가 업데이트로 복사합니다. 대부분의 경우,이 일시 중지 실행에 대한 한 데이터에 남아–캐시 한 번만 그만두지 않 RAM 정보를 얻을.

Nvidia 의 GA100 그래픽 프로세서,포장의 총 20MB L1 40MB L2cache
프로세서 디자이너,선택하는 금액 입력,그리고 정책의 캐쉬에 대한 모든 균형에 대한 열망이 더 큰 프로세서 기능에 대한 복잡성이 증가하고 필요한 죽는 공간입니다. 는 경우에 가능했 20MB,1000-방법으로 완전히 연결 레벨 1 없이 캐시 칩되고 크기의 맨해튼(과이 걸리는 같은 종류의 힘),그리고 우리는 모든 컴퓨터 스포츠와 같은 칩!
오늘날의 Cpu 에서 가장 낮은 수준의 캐시는 지난 10 년 동안 모두 많이 변경되지 않았습니다. 그러나 레벨 3 캐시의 크기는 계속 증가했습니다. 10 년 전,당신은$999Intel i7-980X 를 소유 할만큼 운이 좋다면 12mb 를 얻을 수 있습니다.
캐시,간단히 말해서 절대적으로 필요,절대적으로 최고의 조각 기술이다. 우리가 보지 않았기에 다른 캐시 형태에서 Cpu 와 Gpu(와 같은 번역 조회 버퍼 또는 질감 캐시),그 이후 그들은 모두를 따라 간단한 구조의 패턴 레벨로 우리가 여기서 그들은 아마 소리 하지 않습니다 그렇게 복잡합니다.
마더 보드에 L2 캐시가있는 컴퓨터를 소유 했습니까? Daughterboard 에 제공된 슬롯 기반 Pentium II 및 Celeron Cpu(예:300a)는 어떻습니까? L3 을 공유 한 첫 번째 CPU 를 기억할 수 있습니까? 의견 섹션에서 알려주십시오.
쇼핑 바로가기:
- AMD Ryzen9 3900X Amazon
- AMD Ryzen9 3950X Amazon
- Intel Core i9-10900K Amazon
- AMD Ryzen7 3700X Amazon
- Intel Core i7-10700K Amazon
- AMD Ryzen5 3600Amazon
- Intel Core i5-10600K Amazon
계속 읽고 있습니다. TechSpot 의 Explainers
- Wi-Fi6 설명:차세대 Wi-Fi
- 텐서 코어 란 무엇입니까?
- 칩 비닝이란 무엇입니까?
Leave a Reply