Explainer: L1 vs. L2 vs. L3 Cache
Ogni singola CPU trovata in qualsiasi computer, da un laptop economico a un server da milioni di dollari, avrà qualcosa chiamato cache. Più probabile che no, sarà in possesso di diversi livelli di esso, pure.
Deve essere importante, altrimenti perché dovrebbe essere lì? Ma cosa fa cache e perché la necessità di diversi livelli di roba? Cosa diavolo significa anche associativo 12-way set?
Che cos’è esattamente la cache?
TL;DR: È una memoria piccola ma molto veloce che si trova proprio accanto alle unità logiche della CPU.
Ma, naturalmente, c’è molto di più che possiamo imparare sulla cache…
Iniziamo con un sistema di archiviazione immaginario e magico: è infinitamente veloce, può gestire un numero infinito di transazioni di dati contemporaneamente e mantiene sempre i dati al sicuro. Non che esista nulla nemmeno lontanamente a questo, ma se lo facesse, la progettazione del processore sarebbe molto più semplice.
Le CPU avrebbero solo bisogno di avere unità logiche per aggiungere, moltiplicare, ecc. e un sistema per gestire i trasferimenti di dati. Questo perché il nostro sistema di storage teorico può inviare e ricevere istantaneamente tutti i numeri richiesti; nessuna delle unità logiche sarebbe trattenuta in attesa di una transazione di dati.
Ma, come tutti sappiamo, non esiste alcuna tecnologia di archiviazione magica. Invece, abbiamo dischi rigidi o a stato solido, e anche i migliori di questi non sono nemmeno in grado di gestire da remoto tutti i trasferimenti di dati necessari per una CPU tipica.
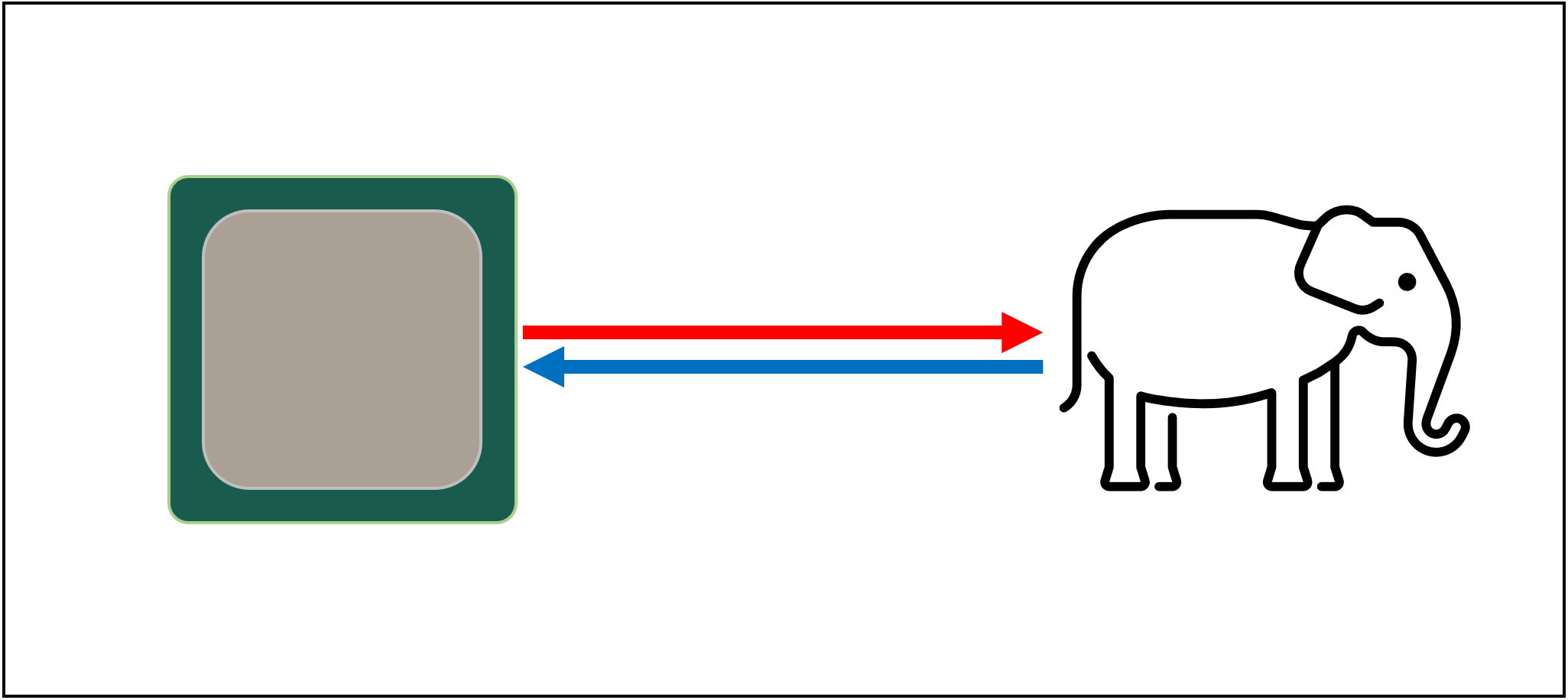
Il grande T’Phon della memorizzazione dei dati
Il motivo per cui è che le CPU moderne sono incredibilmente veloci-prendono solo un ciclo di clock per aggiungere due valori interi a 64 bit insieme, e per una CPU in esecuzione a 4 GHz, questo sarebbe solo 0.00000000025 secondi o un quarto di nanosecondo.
Nel frattempo, filatura hard disk prendere migliaia di nanosecondi solo per trovare i dati sui dischi all’interno, per non parlare di trasferirlo, e unità a stato solido ancora prendere decine o centinaia di nanosecondi.
Tali unità ovviamente non possono essere incorporate nei processori, quindi ciò significa che ci sarà una separazione fisica tra i due. Questo aggiunge solo più tempo allo spostamento dei dati, rendendo le cose ancora peggiori.

Il grande A’Tuin della memorizzazione dei dati, purtroppo
Quindi quello di cui abbiamo bisogno è un altro sistema di memorizzazione dei dati, che si trova tra il processore e lo storage principale. Deve essere più veloce di un’unità, essere in grado di gestire molti trasferimenti di dati contemporaneamente ed essere molto più vicino al processore.
Bene, abbiamo già una cosa del genere, e si chiama RAM, e ogni sistema informatico ne ha alcuni per questo scopo.
Quasi tutto questo tipo di archiviazione è DRAM (dynamic random access memory) ed è in grado di trasmettere dati molto più velocemente di qualsiasi unità.
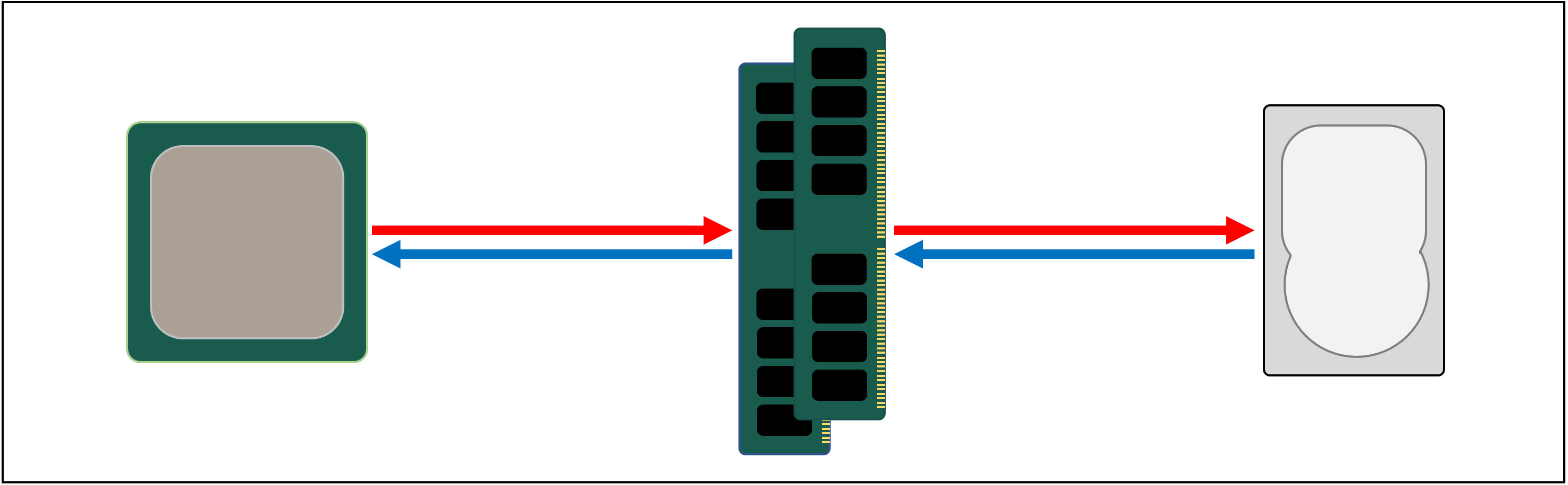
Tuttavia, mentre DRAM è super veloce, non può memorizzare da nessuna parte vicino a quanti più dati.
Alcuni dei più grandi chip di memoria DDR4 realizzati da Micron, uno dei pochi produttori di DRAM, contiene 32 Gbit o 4 GB di dati; i dischi rigidi più grandi contengono 4.000 volte più di questo.
Quindi, anche se abbiamo migliorato la velocità della nostra rete dati, saranno necessari sistemi aggiuntivi-hardware e software-per capire quali dati dovrebbero essere conservati nella quantità limitata di DRAM, pronti per la CPU.
Almeno DRAM può essere prodotto per essere nel pacchetto di chip (noto come embedded DRAM). Le CPU sono piuttosto piccole, quindi non puoi attaccarle così tanto.

10 MB di DRAM appena a sinistra del processore grafico di Xbox 360. Fonte: CPU Grave Yard
La stragrande maggioranza delle DRAM si trova proprio accanto al processore, collegato alla scheda madre, ed è sempre il componente più vicino alla CPU, in un sistema informatico. Eppure, non è ancora abbastanza veloce…
DRAM richiede ancora circa 100 nanosecondi per trovare i dati, ma almeno può trasferire miliardi di bit ogni secondo. Sembra che avremo bisogno di un altro stadio di memoria, per andare tra le unità del processore e la DRAM.
Inserire il livello a sinistra: SRAM (static random access memory). Dove DRAM utilizza condensatori microscopici per memorizzare i dati sotto forma di carica elettrica, SRAM utilizza transistor per fare la stessa cosa e questi possono funzionare quasi veloce come le unità logiche in un processore (circa 10 volte più veloce di DRAM).
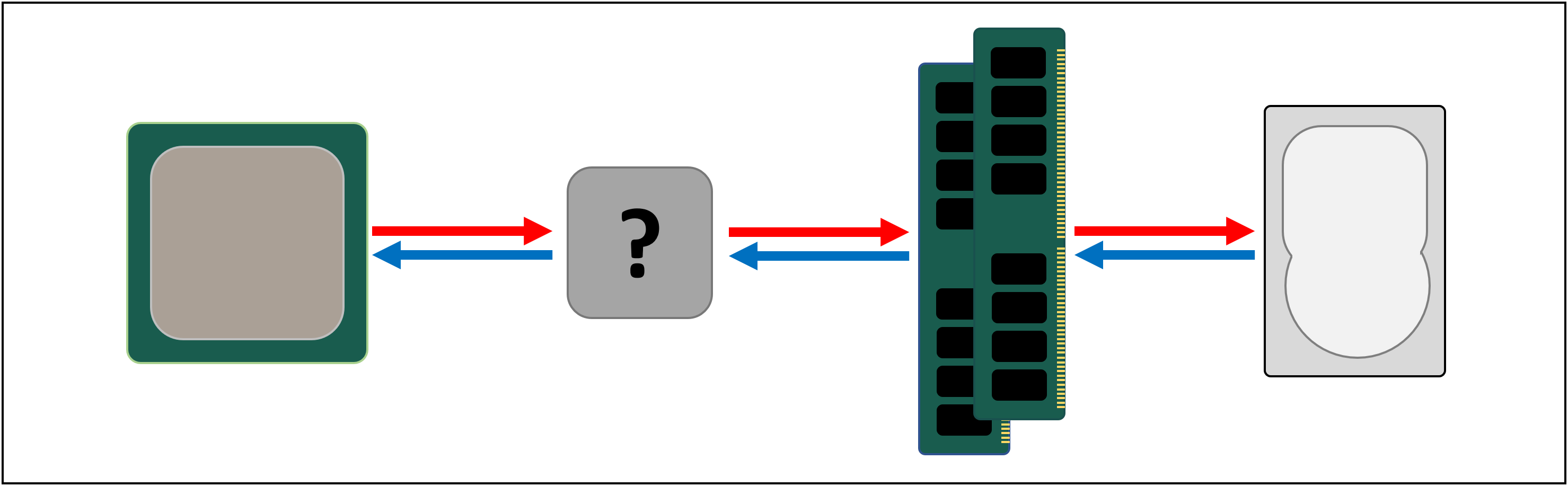
C’è, ovviamente, un inconveniente per SRAM e, ancora una volta, si tratta di spazio.
La memoria basata su transistor occupa molto più spazio della DRAM: per la stessa dimensione del chip DDR4 da 4 GB, si otterrebbe meno di 100 MB di SRAM. Ma dal momento che è realizzato attraverso lo stesso processo di creazione di una CPU, SRAM può essere costruito proprio all’interno del processore, il più vicino possibile alle unità logiche.
La memoria basata su transistor occupa molto più spazio della DRAM: per la stessa dimensione del chip DDR4 da 4 GB, si otterrebbe meno di 100 MB di SRAM.
Con ogni fase in più, abbiamo aumentato la velocità di spostamento dei dati, al costo di quanto possiamo memorizzare. Potremmo continuare ad aggiungere più sezioni, ognuna più veloce ma più piccola.
E così arriviamo a una definizione più tecnica di cosa sia la cache: sono più blocchi di SRAM, tutti situati all’interno del processore; sono usati per garantire che le unità logiche siano tenute il più occupate possibile, inviando e memorizzando i dati a velocità super veloci. Contento? Bene because perché sta andando a diventare molto più complicato da qui in poi!
Cache: un parcheggio multilivello
Come abbiamo discusso, la cache è necessaria perché non esiste un sistema di archiviazione magico in grado di tenere il passo con le richieste di dati delle unità logiche in un processore. Le moderne CPU e processori grafici contengono un certo numero di blocchi SRAM, che sono internamente organizzati in una gerarchia-una sequenza di cache che sono ordinate come segue:

Nell’immagine sopra, la CPU è rappresentata dal rettangolo tratteggiato nero. Le ALU (unità logiche aritmetiche) sono all’estrema sinistra; queste sono le strutture che alimentano il processore, gestendo la matematica che il chip fa. Mentre tecnicamente non è cache, il livello di memoria più vicino alle ALU sono i registri (sono raggruppati in un file di registro).
Ognuno di questi contiene un singolo numero, ad esempio un numero intero a 64 bit; il valore stesso potrebbe essere un pezzo di dati su qualcosa, un codice per un’istruzione specifica o l’indirizzo di memoria di altri dati.
Il file di registro in una CPU desktop è piuttosto piccolo-ad esempio, nel Core i9-9900K di Intel, ci sono due banche in ogni core, e quello per interi contiene solo 180 registri a 64 bit. L’altro file di registro, per i vettori (piccoli array di numeri), ha 168 voci a 256 bit. Quindi il file di registro totale per ogni core è un po ‘ meno di 7 kB. In confronto, il file di registro nei multiprocessori di streaming (l’equivalente della GPU del core di una CPU) di una Nvidia GeForce RTX 2080 Ti ha una dimensione di 256 kB.
I registri sono SRAM, proprio come la cache, ma sono altrettanto veloci delle ALU che servono, spingendo i dati dentro e fuori in un singolo ciclo di clock. Ma non sono progettati per contenere molti dati (solo un singolo pezzo di esso), motivo per cui ci sono sempre blocchi di memoria più grandi nelle vicinanze: questa è la cache di livello 1.
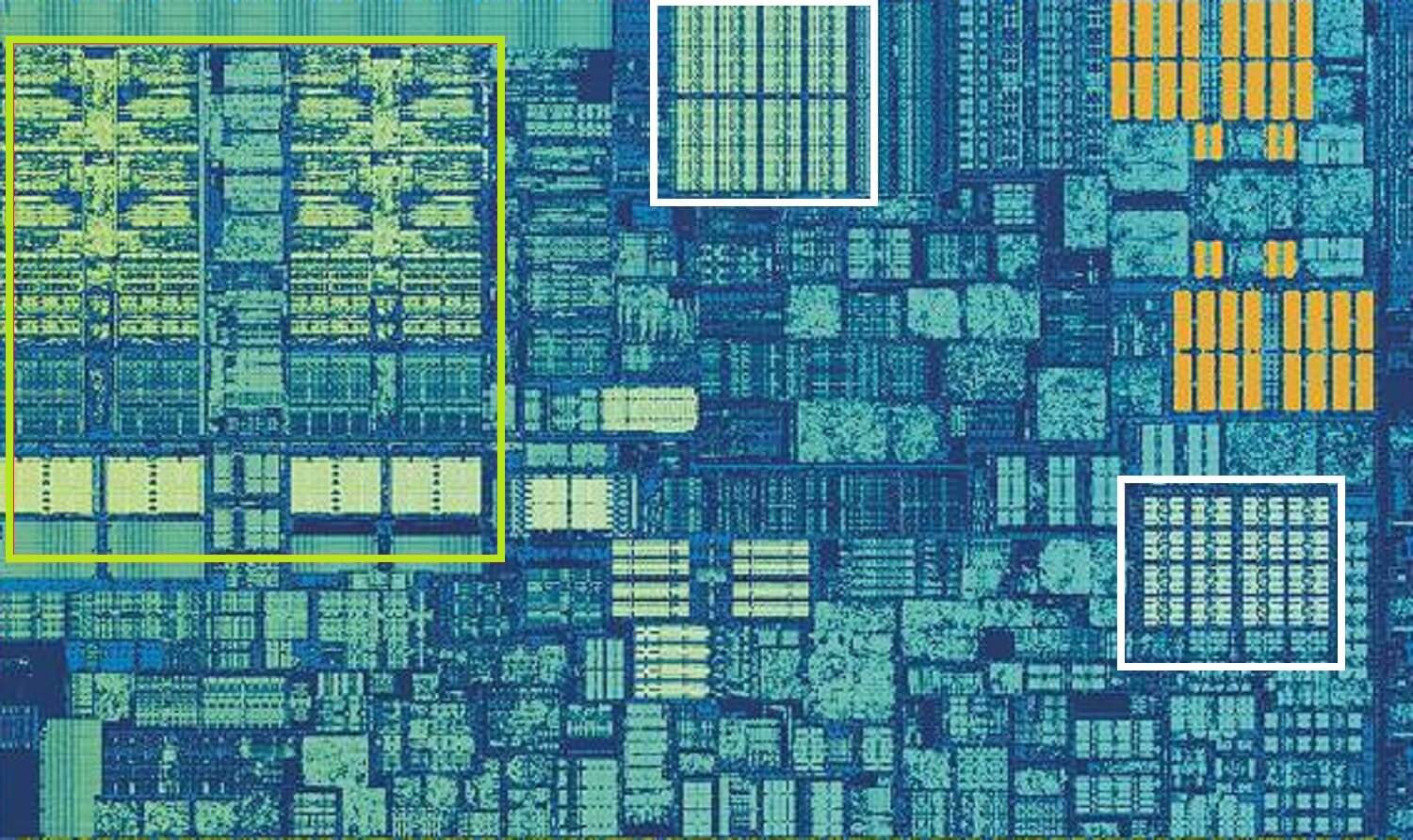
CPU Intel Skylake, ingrandita colpo di un singolo core. Fonte: Wikichip
L’immagine sopra è uno scatto ingrandito di un singolo core dal design del processore desktop Skylake di Intel.
I file ALU e register possono essere visualizzati all’estrema sinistra, evidenziati in verde. Nella parte superiore-centrale dell’immagine, in bianco, è il livello 1 cache di dati. Questo non contiene molte informazioni, solo 32 kB, ma come i registri, è molto vicino alle unità logiche e funziona alla stessa velocità di loro.
L’altro rettangolo bianco indica la cache delle istruzioni di livello 1, anch’essa di 32 kB. Come suggerisce il nome, questo memorizza vari comandi pronti per essere suddivisi in piccole, cosiddette micro operazioni (di solito etichettate come µops), per le ALU da eseguire. C’è anche una cache per loro, e puoi classificarla come Livello 0, poiché è più piccola (solo con 1.500 operazioni) e più vicina delle cache L1.
Potresti chiederti perché questi blocchi di SRAM sono così piccoli; perché non hanno una dimensione di megabyte? Insieme, i dati e le cache di istruzioni occupano quasi la stessa quantità di spazio nel chip come fanno le unità logiche principali, quindi renderle più grandi aumenterebbe la dimensione complessiva del dado.
Ma il motivo principale per cui hanno solo pochi kB, è che il tempo necessario per trovare e recuperare i dati aumenta man mano che la capacità di memoria aumenta. La cache L1 deve essere molto veloce, e quindi deve essere raggiunto un compromesso, tra dimensioni e velocità-nella migliore delle ipotesi, ci vogliono circa 5 cicli di clock (più lunghi per i valori in virgola mobile) per ottenere i dati da questa cache, pronti per l’uso.
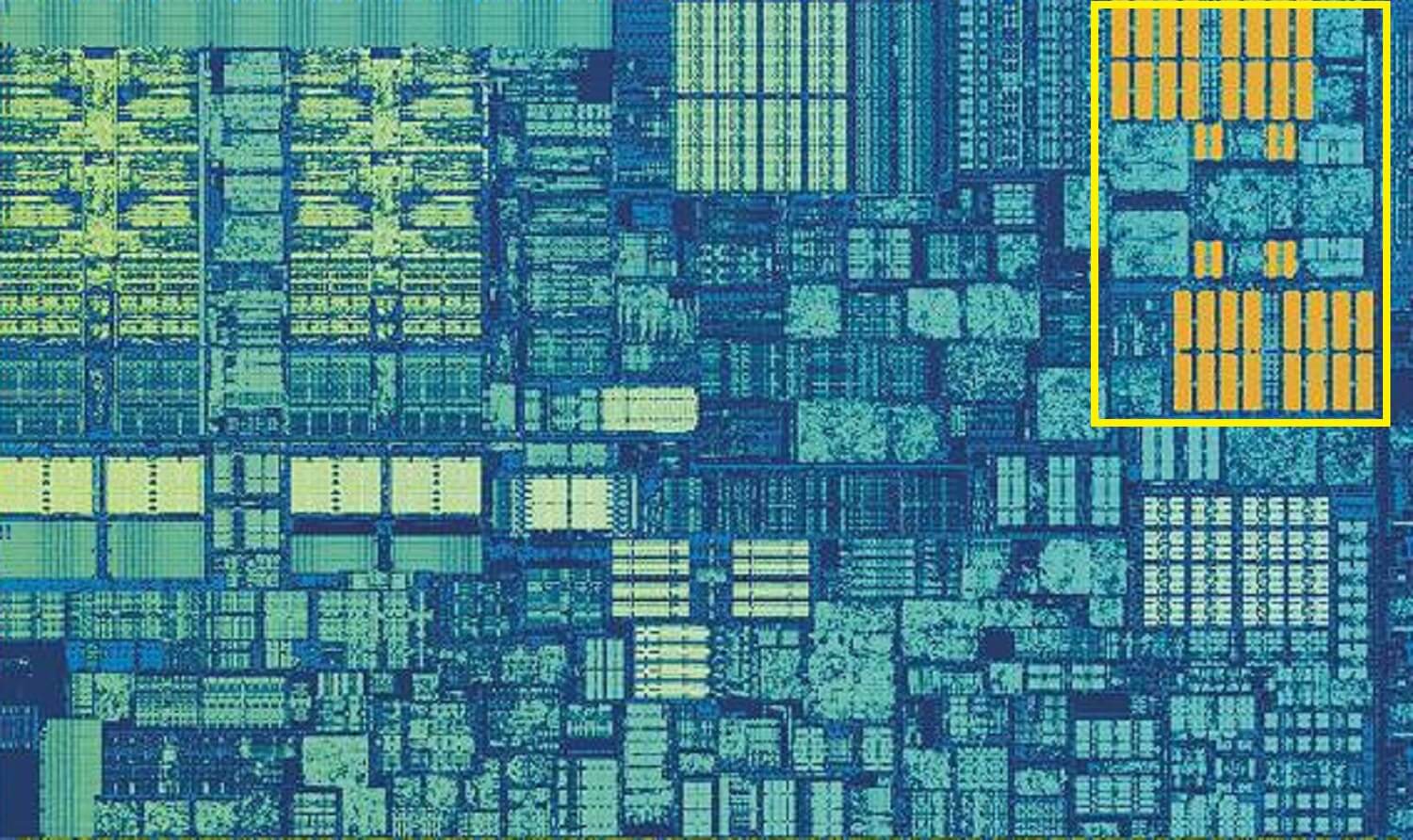
La cache L2 di Skylake: 256 kB di bontà SRAM
Ma se questa fosse l’unica cache all’interno di un processore, le sue prestazioni colpirebbero un muro improvviso. Questo è il motivo per cui tutti hanno un altro livello di memoria integrato nei core: la cache di livello 2. Questo è un blocco generale di archiviazione, trattenendo istruzioni e dati.
È sempre un po ‘ più grande del livello 1: i processori AMD Zen 2 imballano fino a 512 kB, quindi le cache di livello inferiore possono essere mantenute ben fornite. Questa dimensione extra ha un costo, però, e ci vuole circa il doppio del tempo per trovare e trasferire i dati da questa cache, rispetto al livello 1.
Tornando indietro nel tempo, ai tempi dell’Intel Pentium originale, la cache di livello 2 era un chip separato, su un piccolo circuito plug-in (come un DIMM RAM) o integrato nella scheda madre principale. Alla fine si è fatto strada sul pacchetto CPU stesso, fino ad essere finalmente integrato nel die CPU, come i processori Pentium III e AMD K6-III.
Questo sviluppo è stato presto seguito da un altro livello di cache, lì per supportare gli altri livelli inferiori, ed è nato a causa dell’aumento dei chip multi-core.

Intel Kaby lago di chip. Fonte: Wikichip
Questa immagine, di un chip Intel Kaby Lake, mostra 4 core nel centro-sinistra (una GPU integrata occupa quasi la metà del dado, a destra). Ogni core ha il proprio set ‘privato’ di cache di livello 1 e 2 (evidenziazioni bianche e gialle), ma vengono anche con un terzo set di blocchi SRAM.
La cache di livello 3, anche se è direttamente attorno a un singolo core, è completamente condivisa con gli altri-ognuno può accedere liberamente al contenuto della cache L3 di un altro. È molto più grande (tra 2 e 32 MB) ma anche molto più lento, con una media di oltre 30 cicli, specialmente se un core ha bisogno di utilizzare dati che si trovano in un blocco di cache a una certa distanza.
Di seguito, possiamo vedere un singolo core nell’architettura Zen 2 di AMD: il livello 32 kB 1 cache di dati e istruzioni in bianco, il livello 512 KB 2 in giallo e un enorme blocco 4 MB di cache L3 in rosso.

AMD Zen 2 CPU, ingrandita colpo di un singolo core. Fonte: Fritzchens Fritz
Aspetta un secondo. Come può 32 kB occupare più spazio fisico di 512 kB? Se il livello 1 contiene così pochi dati, perché è proporzionalmente molto più grande della cache L2 o L3?
Più di un semplice numero
La cache aumenta le prestazioni accelerando il trasferimento dei dati alle unità logiche e mantenendo una copia delle istruzioni e dei dati utilizzati di frequente nelle vicinanze. Le informazioni memorizzate nella cache sono divise in due parti: i dati stessi e la posizione in cui si trovava originariamente nella memoria/archiviazione di sistema-questo indirizzo è chiamato tag cache.
Quando la CPU esegue un’operazione che desidera leggere o scrivere dati da/alla memoria, inizia controllando i tag nella cache di livello 1. Se è presente quello richiesto (un hit della cache), è possibile accedere a tali dati quasi immediatamente. Un errore di cache si verifica quando il tag richiesto non si trova nel livello di cache più basso.
Quindi viene creato un nuovo tag nella cache L1 e il resto dell’architettura del processore prende il sopravvento, tornando indietro attraverso gli altri livelli di cache (fino all’unità di archiviazione principale, se necessario) per trovare i dati per quel tag. Ma per fare spazio nella cache L1 per questo nuovo tag, qualcos’altro deve invariabilmente essere avviato in L2.
Ciò si traduce in un miscuglio quasi costante di dati, il tutto raggiunto in una manciata di cicli di clock. L’unico modo per raggiungere questo obiettivo è avere una struttura complessa attorno alla SRAM, per gestire la gestione dei dati. In altre parole: se un core della CPU consisteva in una sola ALU, la cache L1 sarebbe molto più semplice, ma poiché ce ne sono dozzine (molte delle quali giocoleranno due thread di istruzioni), la cache richiede più connessioni per mantenere tutto in movimento.
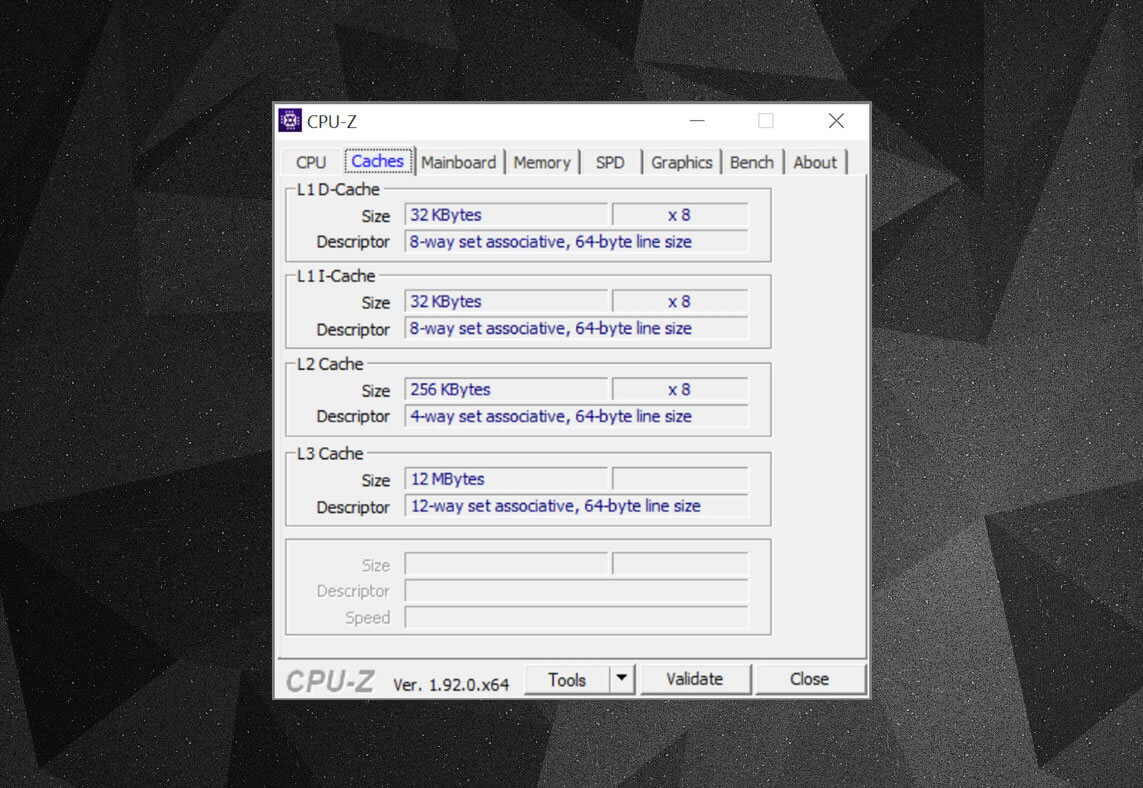
È possibile utilizzare programmi gratuiti, come CPU-Z, per controllare le informazioni della cache per il processore che alimenta il proprio computer. Ma che cosa significa tutte queste informazioni? Un elemento importante è il set di etichette associative: si tratta delle regole applicate da come i blocchi di dati dalla memoria di sistema vengono copiati nella cache.
Le informazioni di cache di cui sopra sono per un Intel Core i7-9700K. Le sue cache di livello 1 sono suddivise in 64 piccoli blocchi, chiamati set, e ognuno di questi è ulteriormente diviso in linee di cache (64 byte di dimensione). Set associativo significa che un blocco di dati dalla memoria di sistema viene mappato sulle linee di cache in un particolare set, piuttosto che essere liberi di mappare ovunque.
La parte a 8 vie ci dice che un blocco può essere associato a 8 linee di cache in un set. Maggiore è il livello di associatività (cioè più “modi”), maggiori sono le possibilità di ottenere un hit della cache quando la CPU va a caccia di dati e una riduzione delle penalità causate dagli errori di cache. Gli aspetti negativi sono che aggiunge più complessità, maggiore consumo energetico e può anche ridurre le prestazioni perché ci sono più linee di cache da elaborare per un blocco di dati.

Cache inclusa L1+L2, cache vittima L3, politiche di write-back, anche ECC. Fonte: Fritzchens Fritz
Un altro aspetto della complessità della cache ruota attorno al modo in cui i dati vengono conservati nei vari livelli. Le regole sono impostate in qualcosa chiamato la politica di inclusione. Ad esempio, i processori Intel Core hanno una cache L1+L3 completamente inclusa. Ciò significa che gli stessi dati nel livello 1, ad esempio, possono essere anche nel livello 3. Questo potrebbe sembrare come se stesse sprecando spazio prezioso nella cache, ma il vantaggio è che se il processore ottiene una miss, durante la ricerca di un tag in un livello inferiore, non ha bisogno di cacciare attraverso il livello più alto per trovarlo.
Negli stessi processori, la cache L2 non è inclusiva: tutti i dati memorizzati non vengono copiati su nessun altro livello. Ciò consente di risparmiare spazio, ma il sistema di memoria del chip deve cercare L3 (che è sempre molto più grande) per trovare un tag mancato. Le cache delle vittime sono simili a queste, ma sono abituate a memorizzare informazioni che vengono espulse da un livello inferiore-ad esempio, i processori Zen 2 di AMD usano la cache L3 victim che memorizza solo i dati da L2.
Esistono altri criteri per la cache, ad esempio quando i dati vengono scritti nella cache e nella memoria di sistema principale. Questi sono chiamati criteri di scrittura e la maggior parte delle CPU odierne utilizza cache di write-back; questo significa che quando i dati vengono scritti in un livello di cache, c’è un ritardo prima che la memoria di sistema venga aggiornata con una copia di esso. Per la maggior parte, questa pausa viene eseguita finché i dati rimangono nella cache-solo una volta avviato, la RAM ottiene le informazioni.

Il processore grafico GA100 di Nvidia, dotato di un totale di 20 MB di cache L1 e 40 MB di cache L2
Per i progettisti di processori, scegliere la quantità, il tipo e la politica della cache significa bilanciare il desiderio di una maggiore capacità del processore con una maggiore complessità e Se fosse possibile avere 20 MB, cache di livello 1 completamente associative a 1000 vie senza che i chip diventino le dimensioni di Manhattan (e consumino lo stesso tipo di potenza), allora avremmo tutti computer con tali chip!
Il livello più basso di cache nelle CPU di oggi non è cambiato molto negli ultimi dieci anni. Tuttavia, la cache di livello 3 ha continuato a crescere di dimensioni. Un decennio fa, si potrebbe ottenere 12 MB di esso, se si ha la fortuna di possedere un Intel 999 Intel i7-980X. Per la metà di tale importo oggi, si ottiene 64 MB.
Cache, in poche parole: assolutamente necessario, assolutamente impressionante pezzi di tecnologia. Non abbiamo esaminato altri tipi di cache in CPU e GPU (come buffer di ricerca di traduzione o cache di texture), ma dal momento che tutti seguono una struttura semplice e un modello di livelli come abbiamo trattato qui, forse non sembreranno così complicati.
Possedevi un computer con cache L2 sulla scheda madre? Che ne dici di quelle CPU Pentium II e Celeron basate su slot (ad esempio 300a) che sono arrivate in una scheda figlia? Riesci a ricordare la tua prima CPU che aveva condiviso L3? Fateci sapere nella sezione commenti.
Shopping scorciatoie:
- AMD Ryzen 9 3900X su Amazon
- AMD Ryzen 9 3950X su Amazon
- Intel Core i9-10900K su Amazon
- AMD Ryzen 7 3700X su Amazon
- Intel Core i7-10700K su Amazon
- AMD Ryzen 5 3600 su Amazon
- Intel Core i5-10600K su Amazon
continua a Leggere. Spiegatori a TechSpot
- Wi-Fi 6 Spiegato: La prossima generazione di Wi-Fi
- Cosa sono i Tensor Core?
- Che cosa è Chip Binning?
Leave a Reply