forklarer: L1 vs. L2 vs. L3 Cache
hver eneste CPU, der findes i enhver computer, fra en billig bærbar computer til en million dollar server, vil have noget, der hedder cache. Mere sandsynligt end ikke, det vil også have flere niveauer af det.
det skal være vigtigt, ellers hvorfor skulle det være der? Men hvad gør cache, og hvorfor behovet for forskellige niveauer af de ting? Hvad I alverden betyder 12-vejs sat associativ endda?
hvad er cache?
TL;DR: det er lille, men meget hurtig hukommelse, der sidder lige ved siden af CPU ‘ ens logiske enheder.
men selvfølgelig er der meget mere, vi kan lære om cache…
lad os begynde med et imaginært, magisk lagringssystem: det er uendeligt hurtigt, kan håndtere et uendeligt antal datatransaktioner på en gang og holder altid data sikkert og sikkert. Ikke at noget endda fjernt til dette eksisterer, men hvis det gjorde det, ville processordesign være meget enklere.
CPU ‘ er behøver kun at have logiske enheder til tilføjelse, multiplikation osv. og et system til håndtering af dataoverførsler. Dette skyldes, at vores teoretiske lagersystem øjeblikkeligt kan sende og modtage alle de krævede numre; ingen af de logiske enheder ville blive holdt op med at vente på en datatransaktion.
men som vi alle ved, er der ikke nogen magisk lagringsteknologi. I stedet har vi hårde eller solid state-drev, og selv de bedste af disse er ikke engang fjernt i stand til at håndtere alle de dataoverførsler, der kræves til en typisk CPU.
den store T ‘Phon af datalagring
årsagen er, at moderne CPU’ er er utroligt hurtige-de tager kun en urcyklus for at tilføje to 64 bit heltalværdier sammen, og for en CPU, der kører ved 4 g, ville dette kun være 0.00000000025 sekunder eller en fjerdedel af et nanosekund.i mellemtiden tager spinning harddiske tusindvis af nanosekunder bare for at finde data på diskene inde, endsige overføre det, og solid state-drev tager stadig tiere eller hundredvis af nanosekunder.
sådanne drev kan naturligvis ikke indbygges i processorer, så det betyder, at der vil være en fysisk adskillelse mellem de to. Dette tilføjer bare mere tid til flytning af data, hvilket gør tingene endnu værre.

den store A ‘ tuin af datalagring, desværre
så hvad vi har brug for er et andet datalagringssystem, der sidder mellem processoren og hovedlageret. Det skal være hurtigere end et drev, være i stand til at håndtere mange dataoverførsler samtidigt og være meget tættere på processoren.
Nå, vi har allerede sådan en ting, og det hedder RAM, og hvert computersystem har nogle til dette formål.
næsten af al denne form for opbevaring er DRAM (dynamic random access memory), og det er i stand til at videregive data meget hurtigere end noget drev.
men mens DRAM er super hurtig, kan den ikke gemme overalt nær så mange data.
nogle af de største DDR4-hukommelseschips lavet af Micron, en af de få producenter af DRAM, har 32 Gbits eller 4 GB data; de største harddiske har 4.000 gange mere end dette.
så selvom vi har forbedret hastigheden på vores datanetværk, kræves der yderligere systemer-udstyr og programmer-for at finde ud af, hvilke data der skal opbevares i den begrænsede mængde DRAM, klar til CPU ‘ en.
i det mindste kan DRAM fremstilles til at være i chippakken (kendt som indlejret DRAM). CPU ‘ er er dog ret små, så du kan ikke holde så meget ind i dem.

10 MB DRAM lige til venstre for 360 ‘ s grafikprocessor. Kilde: CPU Grave Yard
langt størstedelen af DRAM er placeret lige ved siden af processoren, tilsluttet bundkortet, og det er altid den nærmeste komponent til CPU ‘ en, i et computersystem. Og alligevel er det stadig ikke hurtigt nok…
DRAM tager stadig omkring 100 nanosekunder at finde data, men i det mindste kan det overføre milliarder af bits hvert sekund. Det ser ud til, at vi har brug for en anden fase af hukommelsen, for at gå mellem processorens enheder og DRAM.
indtast trin til venstre: SRAM (statisk tilfældig adgangshukommelse). Hvor DRAM bruger mikroskopiske kondensatorer til at gemme data i form af elektrisk ladning, bruger SRAM transistorer til at gøre det samme, og disse kan fungere næsten lige så hurtigt som de logiske enheder i en processor (cirka 10 gange hurtigere end DRAM).
Der er selvfølgelig en ulempe for SRAM og igen handler det om plads.Transistorbaseret hukommelse tager meget mere plads end DRAM: for samme størrelse 4 GB DDR4 chip, vil du få mindre end 100 MB værd af SRAM. Men da det er lavet gennem samme proces som at skabe en CPU, kan SRAM bygges lige inde i processoren, så tæt på de logiske enheder som muligt.Transistorbaseret hukommelse tager meget mere plads end DRAM: for samme størrelse 4 GB DDR4 chip, vil du få mindre end 100 MB værd af SRAM.
med hvert ekstra trin har vi øget hastigheden af at flytte data om, til prisen for, hvor meget vi kan gemme. Vi kunne fortsætte med at tilføje i flere sektioner, hvor hver enkelt er hurtigere, men mindre.
og så kommer vi til en mere teknisk definition af, hvad cache er: det er flere blokke af SRAM, alle placeret inde i processoren; de bruges til at sikre, at de logiske enheder holdes så travlt som muligt ved at sende og gemme data med superhurtige hastigheder. Tilfreds med det? Godt – fordi det bliver meget mere kompliceret herfra!
Cache: en parkeringsplads på flere niveauer
som vi diskuterede, er cache nødvendig, fordi der ikke er et magisk lagringssystem, der kan holde trit med datakravene fra de logiske enheder i en processor. Moderne CPU ‘ er og grafikprocessorer indeholder et antal SRAM-blokke, der er internt organiseret i et hierarki-en sekvens af cacher, der er ordnet som følger:

i ovenstående billede er CPU ‘ en repræsenteret af det sorte stiplede rektangel. ALUs (aritmetiske logiske enheder) er længst til venstre; dette er de strukturer, der driver processoren og håndterer den matematik, chippen gør. Selvom det teknisk set ikke er cache, er det nærmeste hukommelsesniveau til Alu ‘ erne registre (de er grupperet sammen i en registerfil).
hver af disse har et enkelt tal, såsom et 64-bit heltal; selve værdien kan være et stykke data om noget, en kode til en bestemt instruktion eller hukommelsesadressen til nogle andre data.
registerfilen i en desktop CPU er ret lille-for eksempel i Intels Core i9-9900k er der to banker af dem i hver kerne, og den for heltal indeholder kun 180 64-bit registre. Den anden registerfil, for vektorer (små arrays af tal), har 168 256-bit poster. Så den samlede registerfil for hver kerne er lidt under 7 kB. Til sammenligning er registerfilen i Streaming multiprocessorer (GPU ‘s ækvivalent af en CPU’ s kerne) af en Nvidia GeForce 2080 Ti 256 kB i størrelse.
registre er SRAM, ligesom cache, men de er lige så hurtige som de Alu ‘ er, de tjener, skubber data ind og ud i en enkelt urcyklus. Men de er ikke designet til at holde meget data (kun et enkelt stykke af det), hvorfor der altid er nogle større blokke af hukommelse i nærheden: Dette er Niveau 1 cache.
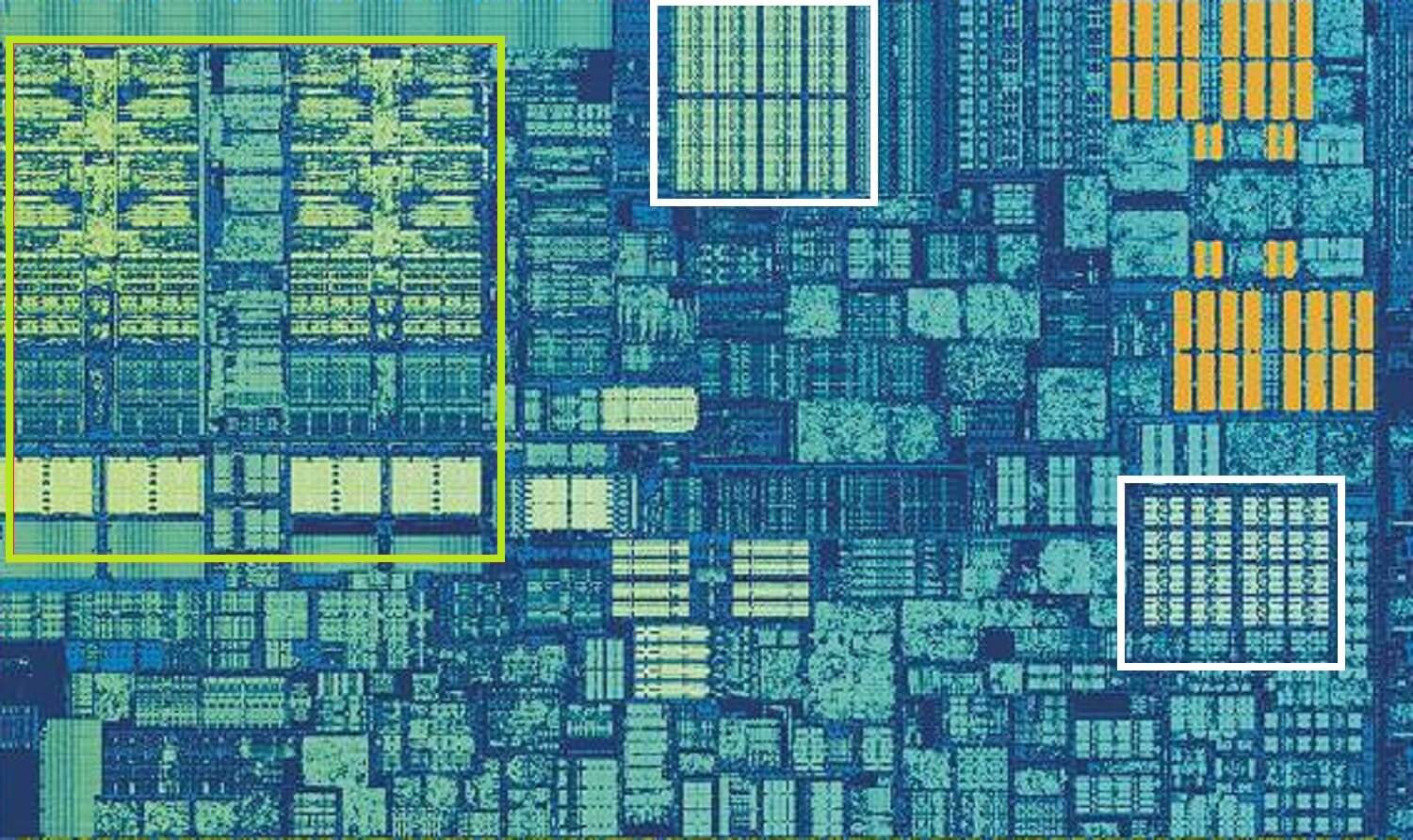
Intel Skylake CPU, skudt i skud af en enkelt kerne. Ovenstående billede er et billede af en enkelt kerne fra Intels Skylake desktop processor design.
Alu ‘ erne og registerfilerne kan ses længst til venstre, fremhævet med grønt. I øverste midten af billedet, i hvidt, er Niveau 1 data cache. Dette indeholder ikke meget information, kun 32 kB, men ligesom registre er det meget tæt på de logiske enheder og kører med samme hastighed som dem.
det andet hvide rektangel angiver Niveau 1 Instruktionscache, også 32 kB i størrelse. Som navnet antyder, gemmer dette forskellige kommandoer, der er klar til at blive opdelt i mindre, såkaldte mikrooperationer (normalt mærket som pristops), så Alu ‘ erne kan udføre. Der er også en cache til dem, og du kan klassificere det som Niveau 0, da det er mindre (kun med 1.500 operationer) og tættere end L1 caches.
du undrer dig måske over, hvorfor disse blokke af SRAM er så små; hvorfor er de ikke en megabyte i størrelse? Sammen tager data-og instruktionscacherne næsten samme plads i chippen som de vigtigste logiske enheder gør, så at gøre dem større ville øge den samlede størrelse af matricen.
men hovedårsagen til, at de bare holder et par kB, er, at den tid, der er nødvendig for at finde og hente data, øges, når hukommelseskapaciteten bliver større. L1 cache skal være rigtig hurtig, og så skal der opnås et kompromis mellem størrelse og hastighed-i bedste fald tager det omkring 5 urcyklusser (længere for flydende punktværdier) for at få dataene ud af denne cache, klar til brug.
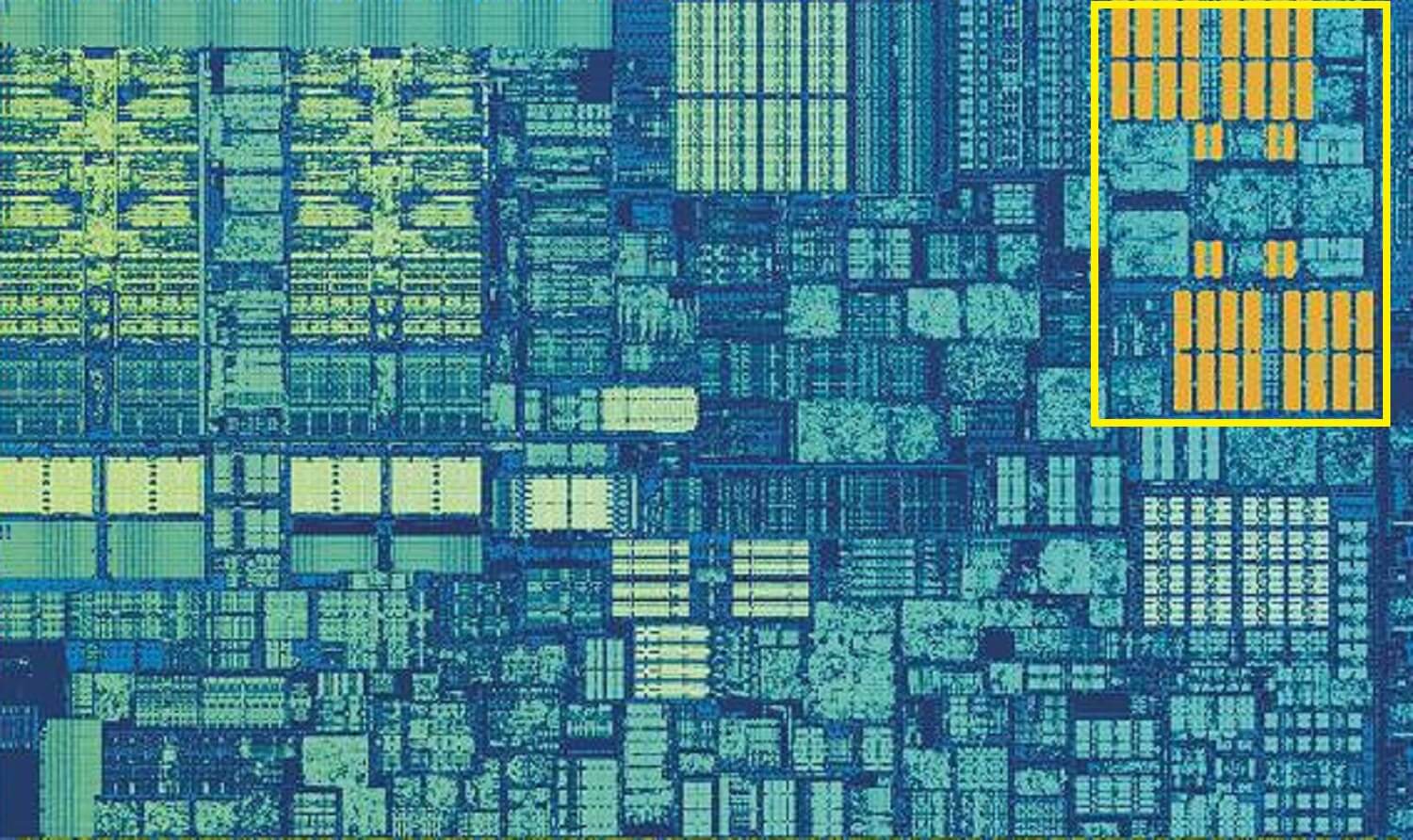
Skylake ‘ s L2 cache: 256 kB SRAM godhed
men hvis dette var den eneste cache inde i en processor, ville dens ydeevne ramme en pludselig væg. Dette er grunden til, at de alle har et andet hukommelsesniveau indbygget i kernerne: niveau 2-cachen. Dette er en generel blok af opbevaring, der holder på instruktioner og data.
det er altid ret større end Niveau 1: AMD 2-processorer pakker op til 512 kB, så cacherne på lavere niveau kan holdes godt leveret. Denne ekstra størrelse koster dog, og det tager cirka dobbelt så lang tid at finde og overføre dataene fra denne cache sammenlignet med Niveau 1.
går tilbage i tiden, til de dage af den oprindelige Intel Pentium, niveau 2 cache var en separat chip, enten på en lille plug-in printkort (som en RAM DIMM) eller indbygget i de vigtigste bundkort. Det arbejdede til sidst på selve CPU-pakken, indtil det endelig blev integreret i CPU-matricen, som Pentium III og AMD K6-III processorer.
denne udvikling blev snart efterfulgt af et andet niveau af cache, der for at understøtte de andre lavere niveauer, og det skete på grund af stigningen i multi-core chips.

Intel Kaby Lake chip. Dette billede af en Intel Kaby Lake-chip viser 4 kerner i venstre midten (en integreret GPU optager næsten halvdelen af matricen til højre). Hver kerne har sit eget ‘private’ sæt cacher på niveau 1 og 2 (hvide og gule højdepunkter), men de leveres også med et tredje sæt SRAM-blokke.niveau 3 cache, selvom det er direkte omkring en enkelt kerne, deles fuldt ud med de andre-hver enkelt kan frit få adgang til indholdet af en andens L3 cache. Det er meget større (mellem 2 og 32 MB), men også meget langsommere, i gennemsnit over 30 cyklusser, især hvis en kerne skal bruge data, der er i en cache-blok et stykke væk.
nedenfor kan vi se en enkelt kerne i AMDs 2-arkitektur: 32 kB Niveau 1 data og instruktion caches i hvid, 512 KB niveau 2 i gul og en enorm 4 MB blok L3 cache i rødt.

AMD med 2 CPU, skudt i skud af en enkelt kerne. Kilde: Fritschens Frits
vent et sekund. Hvordan kan 32 kB optage mere fysisk plads end 512 kB? Hvis niveau 1 indeholder så lidt data, hvorfor er det proportionalt så meget større end L2 eller L3 cache?
mere end blot et tal
Cache øger ydeevnen ved at fremskynde dataoverførslen til de logiske enheder og holde en kopi af ofte anvendte instruktioner og data i nærheden. Oplysningerne, der er gemt i cachen, er opdelt i to dele: selve dataene og placeringen af, hvor de oprindeligt var placeret i systemhukommelsen/lageret-denne adresse kaldes et cache-tag.
når CPU ‘ en kører en handling, der ønsker at læse eller skrive data fra/til hukommelsen, starter den med at kontrollere tags i niveau 1-cachen. Hvis den krævede er til stede (et cache-hit), kan disse data derefter fås næsten med det samme. En cache-miss opstår, når det krævede tag ikke er på det laveste cache-niveau.
så der oprettes et nyt tag i L1-cachen, og resten af processorarkitekturen overtager og jager tilbage gennem de andre cache-niveauer (om nødvendigt helt tilbage til hovedlagringsdrevet) for at finde dataene til det tag. Men for at gøre plads i L1-cachen til dette nye tag, skal noget andet altid startes ud i L2.
dette resulterer i en næsten konstant blanding af data, alt opnået i blot en håndfuld urcyklusser. Den eneste måde at opnå dette på er ved at have en kompleks struktur omkring SRAM til at håndtere styringen af dataene. Sæt en anden måde: hvis en CPU-kerne bestod af kun en ALU, ville L1-cachen være meget enklere, men da der er snesevis af dem (hvoraf mange vil jonglere med to tråde med instruktioner), kræver cachen flere forbindelser for at holde alt på farten.
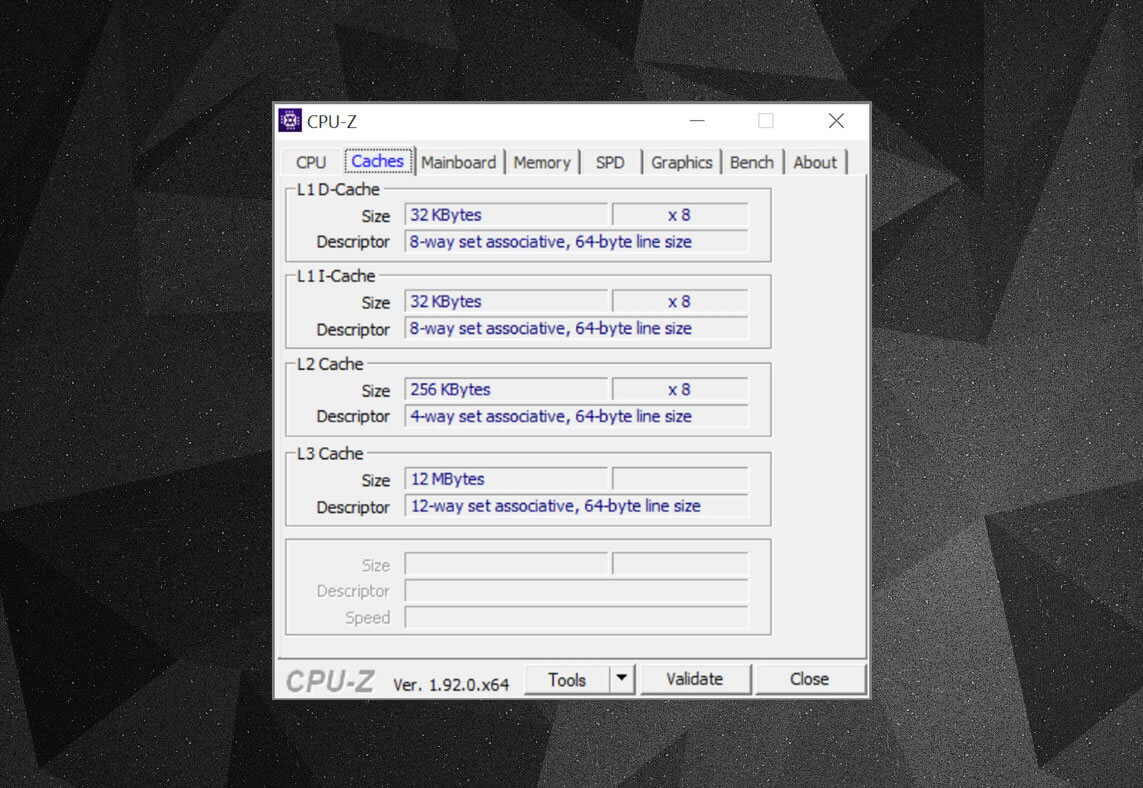
Du kan bruge gratis programmer, f.eks. Men hvad betyder alle disse oplysninger? Et vigtigt element er etiketten sæt associativ-det handler om de regler, der håndhæves af, hvordan blokke af data fra systemhukommelsen kopieres til cachen.
ovenstående cache oplysninger er for en Intel Core i7-9700k. dens niveau 1 caches er hver opdelt i 64 små blokke, kaldet sæt, og hver enkelt af disse er yderligere opdelt i cache linjer (64 bytes i størrelse). Set associative betyder, at en blok af data fra systemhukommelsen er kortlagt på cachelinierne i et bestemt sæt, snarere end at være fri til at kortlægge overalt.
den 8-vejs del fortæller os, at en blok kan være forbundet med 8 cache linjer i et sæt. Jo større niveau af associativitet (dvs.flere ‘måder’), jo større er chancerne for at få ET cache-hit, når CPU ‘ en går på jagt efter data, og en reduktion i sanktionerne forårsaget af cache-misser. Ulemperne er, at det tilføjer mere kompleksitet, øget strømforbrug og også kan reducere ydeevnen, fordi der er flere cache-linjer at behandle for en datablok.

L1+L2 inklusive cache, L3 offer cache, skrive-back politikker, selv ECC. Kilde: Et andet aspekt af cachens kompleksitet drejer sig om, hvordan data opbevares på tværs af de forskellige niveauer. Reglerne er fastsat i noget, der hedder inklusionspolitikken. For eksempel har Intel Core-processorer fuldt inkluderende L1+L3-cache. Dette betyder, at de samme data i niveau 1 For eksempel også kan være i niveau 3. Dette kan virke som om det spilder værdifuld cache-plads, men fordelen er, at hvis processoren får en miss, når den søger efter et tag på et lavere niveau, behøver den ikke at jage gennem det højere niveau for at finde det.
i de samme processorer er L2-cachen ikke inklusive: alle data, der er gemt der, kopieres ikke til noget andet niveau. Dette sparer plads, men resulterer i, at chippens hukommelsessystem skal søge gennem L3 (som altid er meget større) for at finde et savnet tag. Offercacher ligner dette, men de er vant til lagrede oplysninger, der bliver skubbet ud af et lavere niveau-for eksempel bruger AMDs 2-processorer L3-offercache, der bare gemmer data fra L2.
der er andre politikker for cache, såsom når data bliver skrevet i cache og hovedsystemhukommelsen. Disse kaldes skrivepolitikker, og de fleste af nutidens CPU ‘ er bruger skrivebagringscacher; dette betyder, at når data skrives til et cache-niveau, er der en forsinkelse, før systemhukommelsen opdateres med en kopi af den. For det meste kører denne pause, så længe dataene forbliver i cachen-kun når den er startet ud, får RAM ‘ en oplysningerne.

Nvidias GA100-grafikprocessor, pakket med i alt 20 MB L1 og 40 MB L2-cache
for processordesignere handler valg af mængde, type og cache-Politik om at afbalancere ønsket om større processorkapacitet mod øget kompleksitet og krævet matrice-plads. Hvis det var muligt at have 20 MB, 1000-vejs fuldt associative niveau 1 caches uden chips bliver størrelsen af Manhattan (og forbruge den samme slags strøm), så ville vi alle have computere sportslige sådanne chips!
det laveste niveau af caches i dagens CPU ‘ er har ikke ændret sig så meget i det sidste årti. Niveau 3 cache er dog fortsat med at vokse i størrelse. For et årti siden kunne du få 12 MB af det, hvis du var heldig nok til at eje en $999 Intel i7-980h. for halvdelen af det beløb i dag får du 64 MB.
Cache, i en nøddeskal: absolut nødvendigt, absolut fantastiske stykker teknologi. Vi har ikke set på andre cachetyper i CPU ‘er og GPU’ er (såsom oversættelsesopslagbuffere eller teksturcacher), men da de alle følger en enkel struktur og mønster af niveauer, som vi har dækket her, lyder de måske ikke så kompliceret.
har du en computer, der havde L2 cache på bundkortet? Hvad med de slotbaserede Pentium II-og Celeron-CPU ‘ er (f. eks. 300a), der kom i et daughterboard? Kan du huske din første CPU, der havde delt L3? Lad os vide i kommentarfeltet.
Shopping genveje:
- AMD Ryson 9 3900
- AMD Ryson 9 3950
- Intel Core i9-10900k på Ryson
- AMD Ryson 7 3700 på Ryson
- Intel Core i7-10700k på Ryson
- AMD Ryson 5 3600 på Ryson
- Intel Core i5-10600k på
Fortsæt læsning. Forklarere på TechSpot
- trådløst internet 6 forklaret: den næste Generation af trådløst internet
- hvad er Tensorkerner?
- hvad er Chip Binning?
Leave a Reply