Curva AUC-ROC en Aprendizaje Automático Explicada claramente
Curva AUC-ROC – ¡La Estrella!
Ha creado su modelo de aprendizaje automático, así que, ¿qué sigue? Es necesario evaluarlo y validar lo bueno (o malo) que es, para que luego pueda decidir si implementarlo o no. Ahí es donde entra la curva AUC-ROC.
El nombre puede ser un trabalenguas, pero solo está diciendo que estamos calculando el «Área Bajo la Curva» (AUC) del «Operador Característico del Receptor» (ROC). Confundido? ¡Te entiendo! He estado en tu lugar. Pero no se preocupe, veremos lo que significan estos términos en detalle y ¡todo será pan comido!

Por ahora, solo tenga en cuenta que la curva AUC-ROC nos ayuda a visualizar el rendimiento de nuestro clasificador de aprendizaje automático. Aunque solo funciona para problemas de clasificación binaria, veremos hacia el final cómo podemos ampliarlo para evaluar problemas de clasificación de múltiples clases también.
También cubriremos temas como sensibilidad y especificidad, ya que estos son temas clave detrás de la curva AUC-ROC.
Sugiero revisar el artículo sobre Matriz de confusión, ya que introducirá algunos términos importantes que usaremos en este artículo.
Tabla de contenidos
- ¿Qué son la Sensibilidad y la especificidad?
- Probabilidad de predicciones
- ¿Qué es la curva AUC-ROC?
- ¿Cómo funciona la Curva AUC-ROC?
- AUC-ROC en Python
- AUC-ROC para Clasificación Multiclase
¿Qué son la Sensibilidad y la especificidad?
Así es como se ve una matriz de confusión:
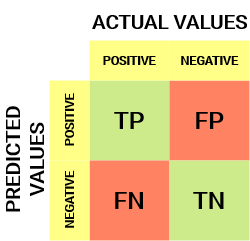
De la matriz de confusión, podemos derivar algunas métricas importantes que no se discutieron en el artículo anterior. Hablemos de ellos aquí.
Sensibilidad / Tasa Positiva verdadera / Recuerdo
![]()
La sensibilidad nos dice qué proporción de la clase positiva se clasificó correctamente.
Un ejemplo sencillo sería determinar qué proporción de las personas enfermas reales fueron detectadas correctamente por el modelo.
Tasa de falsos negativos
![]()
La Tasa de falsos Negativos (FNR) nos dice qué proporción de la clase positiva se clasificó incorrectamente por el clasificador.
Un TPR más alto y un FNR más bajo es deseable ya que queremos clasificar correctamente la clase positiva.
Especificidad / Tasa negativa verdadera
![]()
La especificidad nos dice qué proporción de la clase negativa se clasificó correctamente.
Tomando el mismo ejemplo que en Sensibilidad, Especificidad significaría determinar la proporción de personas sanas que fueron identificadas correctamente por el modelo.
Tasa de falsos positivos
![]()
FPR nos dice qué proporción de la clase negativa se clasificó incorrectamente por el clasificador.
Un TNR más alto y un FPR más bajo es deseable ya que queremos clasificar correctamente la clase negativa.
De estas métricas, la Sensibilidad y la especificidad son quizás las más importantes y veremos más adelante cómo se utilizan para construir una métrica de evaluación. Pero antes de eso, entendamos por qué la probabilidad de predicción es mejor que predecir la clase objetivo directamente.
Probabilidad de predicciones
Se puede utilizar un modelo de clasificación de aprendizaje automático para predecir la clase real del punto de datos directamente o predecir su probabilidad de pertenecer a diferentes clases. Esto último nos da más control sobre el resultado. Podemos determinar nuestro propio umbral para interpretar el resultado del clasificador. ¡Esto a veces es más prudente que simplemente construir un modelo completamente nuevo!
Establecer diferentes umbrales para clasificar la clase positiva para los puntos de datos cambiará inadvertidamente la Sensibilidad y especificidad del modelo. Y uno de estos umbrales probablemente dará un mejor resultado que los otros, dependiendo de si nuestro objetivo es reducir el número de Falsos Negativos o Falsos Positivos.
Eche un vistazo a la siguiente tabla:
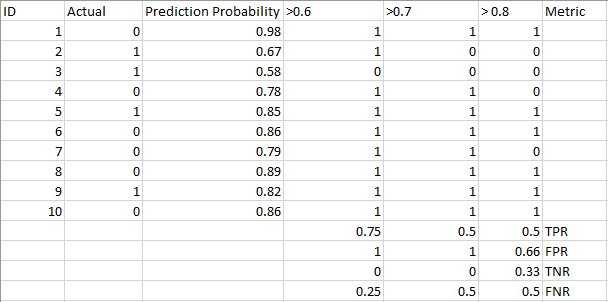
Las métricas cambian con los valores de umbral cambiantes. Podemos generar diferentes matrices de confusión y comparar las diversas métricas que discutimos en la sección anterior. Pero eso no sería prudente. En su lugar, lo que podemos hacer es generar un gráfico entre algunas de estas métricas para que podamos visualizar fácilmente qué umbral nos está dando un mejor resultado.
¡La curva AUC-ROC resuelve precisamente ese problema!
¿Qué es la curva AUC-ROC?
La curva Característica del Operador Receptor (ROC) es una métrica de evaluación para problemas de clasificación binaria. Es una curva de probabilidad que traza el TPR contra el FPR en varios valores de umbral y esencialmente separa la «señal» del «ruido». El Área Bajo la Curva (AUC) es la medida de la capacidad de un clasificador para distinguir entre clases y se utiliza como resumen de la curva ROC.
Cuanto mayor sea el AUC, mejor será el rendimiento del modelo para distinguir entre las clases positiva y negativa.
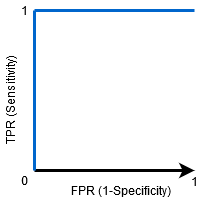
Cuando AUC = 1, el clasificador puede distinguir perfectamente entre todos los puntos de clase Positivos y Negativos correctamente. Sin embargo, si el AUC hubiera sido 0, entonces el clasificador estaría prediciendo todos los Negativos como Positivos, y todos los Positivos como Negativos.
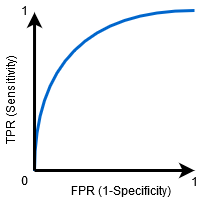
Cuando 0.5<AUC< 1, existe una alta probabilidad de que el clasificador pueda distinguir los valores de clase positivos de los valores de clase negativos. Esto es así porque el clasificador es capaz de detectar más números de Verdaderos positivos y Verdaderos negativos que Falsos negativos y Falsos positivos.
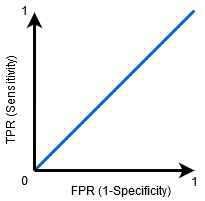
Cuando AUC = 0,5, el clasificador no es capaz de distinguir entre puntos de clase Positivos y Negativos. Lo que significa que el clasificador está prediciendo una clase aleatoria o una clase constante para todos los puntos de datos.
Por lo tanto, cuanto mayor sea el valor de AUC de un clasificador, mejor será su capacidad para distinguir entre clases positivas y negativas.
¿Cómo funciona la Curva AUC-ROC?
En una curva ROC, un valor del eje X más alto indica un mayor número de Falsos positivos que de verdaderos negativos. Mientras que un valor del eje Y más alto indica un mayor número de Verdaderos positivos que de falsos negativos. Por lo tanto, la elección del umbral depende de la capacidad de equilibrar entre Falsos positivos y Falsos negativos.
Profundicemos un poco más y entendamos cómo se vería nuestra curva ROC para diferentes valores de umbral y cómo variarían la especificidad y la sensibilidad.
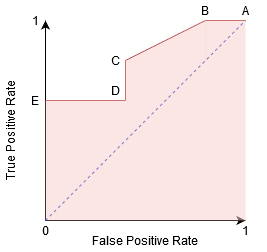
Podemos intentar entender este gráfico generando una matriz de confusión para cada punto correspondiente a un umbral y hablar sobre el rendimiento de nuestro clasificador:
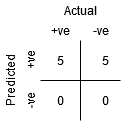
El Punto A es donde la Sensibilidad es la más alta y la especificidad la más baja. Esto significa que todos los puntos de clase positivos se clasifican correctamente y todos los puntos de clase negativos se clasifican incorrectamente.
De hecho, cualquier punto de la línea azul corresponde a una situación en la que la Tasa Positiva Verdadera es igual a la Tasa Positiva Falsa.
Todos los puntos por encima de esta línea corresponden a la situación en la que la proporción de puntos clasificados correctamente pertenecientes a la clase Positiva es mayor que la proporción de puntos clasificados incorrectamente pertenecientes a la clase negativa.
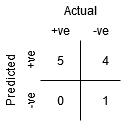
Aunque el Punto B tiene la misma Sensibilidad que el Punto A, tiene una especificidad más alta. Lo que significa que el número de puntos de clase incorrectamente negativos es menor en comparación con el umbral anterior. Esto indica que este umbral es mejor que el anterior.
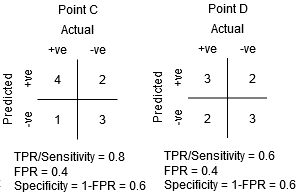
Entre los puntos C y D, la Sensibilidad en el punto C es mayor que el punto D para la misma especificidad. Esto significa que, para el mismo número de puntos de clase negativos clasificados incorrectamente, el clasificador predijo un mayor número de puntos de clase positivos. Por lo tanto, el umbral en el punto C es mejor que el punto D.
Ahora, dependiendo de cuántos puntos clasificados incorrectamente queremos tolerar para nuestro clasificador, elegiríamos entre el punto B o C para predecir si puedes derrotarme en PUBG o no.
«Falsas esperanzas son más peligrosos que los temores.»- J. R. R. Tolkein

El punto E es donde la especificidad se vuelve más alta. Lo que significa que no hay Falsos positivos clasificados por el modelo. ¡El modelo puede clasificar correctamente todos los puntos de clase negativos! Elegiríamos este punto si nuestro problema era dar recomendaciones de canciones perfectas a nuestros usuarios.
Siguiendo esta lógica, ¿puedes adivinar dónde estaría el punto correspondiente a un clasificador perfecto en el gráfico?
¡Sí! Estaría en la esquina superior izquierda del gráfico ROC correspondiente a la coordenada (0, 1) en el plano cartesiano. Es aquí donde tanto la Sensibilidad como la Especificidad serían las más altas y el clasificador clasificaría correctamente todos los puntos de clase Positivos y Negativos.
Entendiendo la curva AUC-ROC en Python
Ahora, podemos probar manualmente la Sensibilidad y Especificidad para cada umbral o dejar que sklearn haga el trabajo por nosotros. ¡Definitivamente vamos con lo último!
Vamos a crear nuestros datos arbitrarios usando el método sklearn make_classification:
Probaré el rendimiento de dos clasificadores en este conjunto de datos:
Sklearn tiene un método muy potente roc_curve () que calcula el ROC para su clasificador en cuestión de segundos! Devuelve los valores de FPR, TPR y umbral:
La puntuación AUC se puede calcular utilizando el método roc_auc_score() de sklearn:
0.9761029411764707 0.9233769727403157
Pruebe este código en la ventana de codificación en vivo a continuación:
También podemos trazar las curvas ROC para los dos algoritmos utilizando matplotlib:
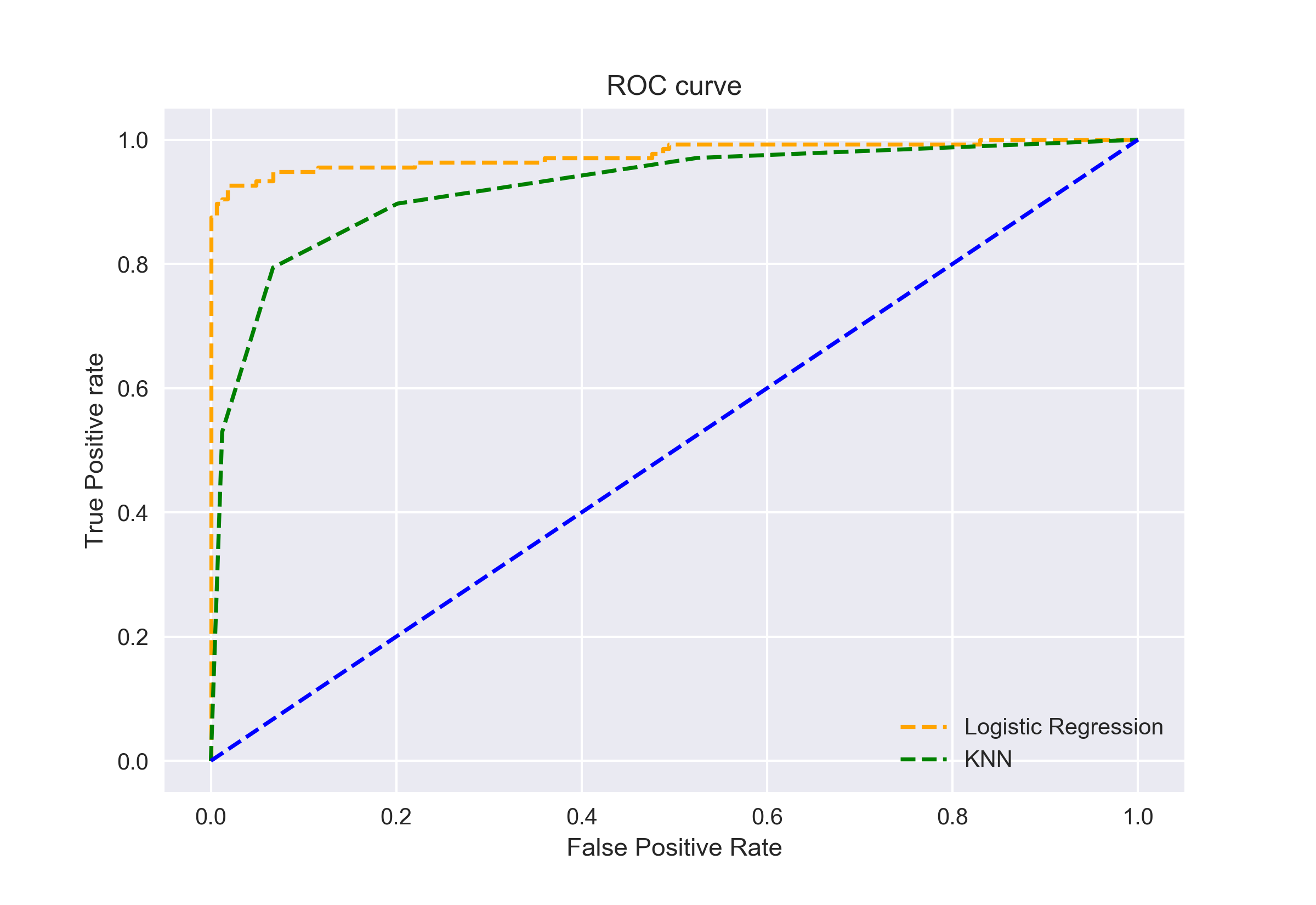
Es evidente a partir de la gráfica que el AUC de la curva ROC de Regresión Logística es mayor que el de la curva ROC de KNN. Por lo tanto, podemos decir que la regresión logística hizo un mejor trabajo al clasificar la clase positiva en el conjunto de datos.
AUC-ROC para Clasificación Multiclase
Como dije antes, la curva AUC-ROC es solo para problemas de clasificación binaria. Pero podemos extenderlo a problemas de clasificación multiclase mediante el uso de la técnica Uno contra todo.
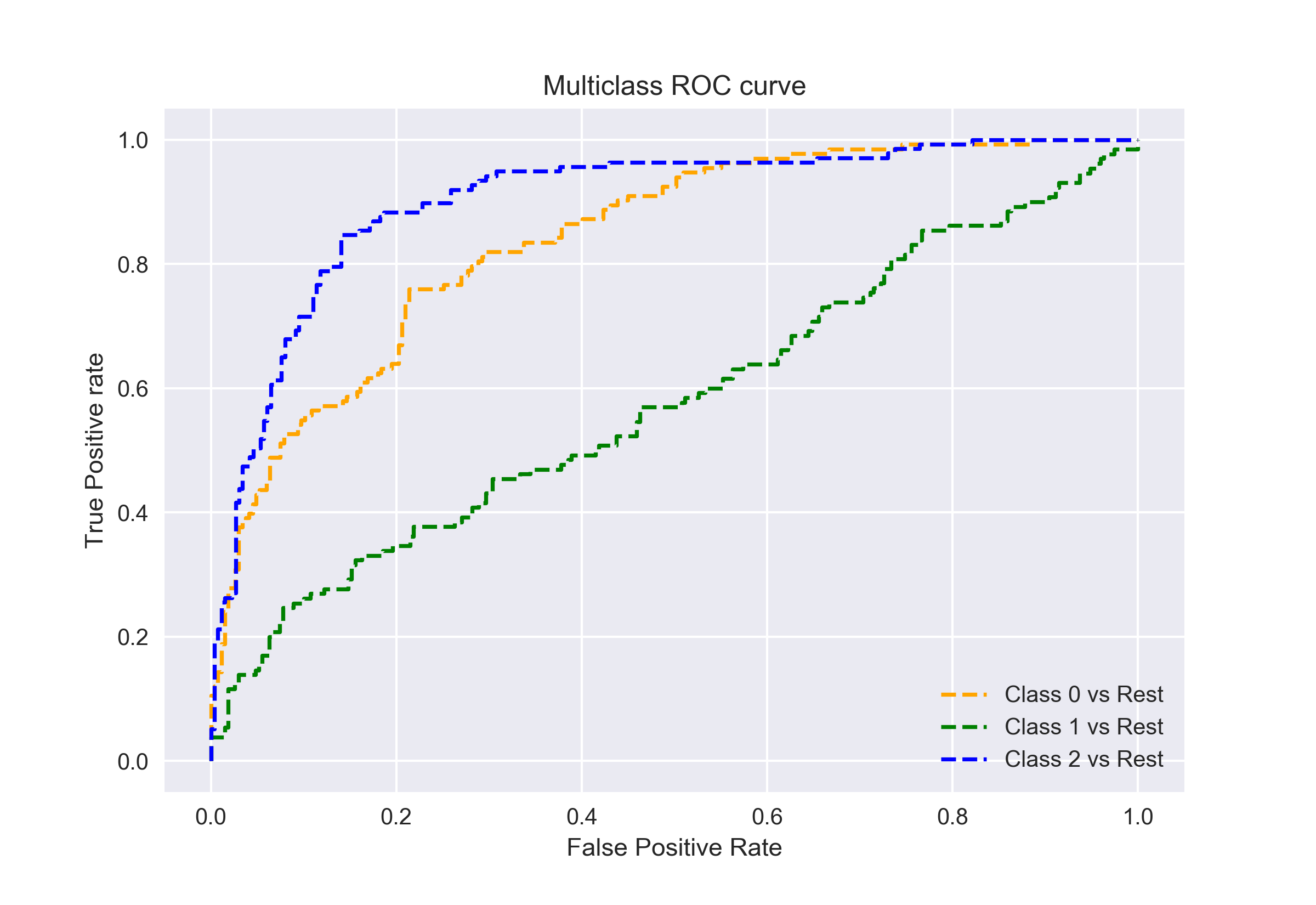
Por lo tanto, si tenemos tres clases 0, 1 y 2, el ROC para la clase 0 se generará clasificando 0 contra no 0, es decir, 1 y 2. El ROC de la clase 1 se generará clasificando 1 contra no 1, y así sucesivamente.
La curva ROC para modelos de clasificación de múltiples clases se puede determinar de la siguiente manera:
Notas finales
Espero que haya encontrado este artículo útil para comprender lo poderosa que es la métrica de curva AUC-ROC para medir el rendimiento de un clasificador. Lo usarás mucho en la industria e incluso en hackatones de ciencia de datos o aprendizaje automático. Mejor familiarizarse con ella!
Yendo más allá, le recomendaría los siguientes cursos que serán útiles para desarrollar su perspicacia en ciencia de datos:
- Introducción a la Ciencia de datos
- Aprendizaje automático aplicado
También puede leer este artículo en nuestra APLICACIÓN móvil![]()

Leave a Reply