AUC-ROC-Kurve im maschinellen Lernen klar erklärt
AUC–ROC-Kurve – Der Star!
Sie haben Ihr Modell für maschinelles Lernen erstellt – was kommt als nächstes? Sie müssen es bewerten und validieren, wie gut (oder schlecht) es ist, damit Sie dann entscheiden können, ob Sie es implementieren möchten. Hier kommt die AUC-ROC-Kurve ins Spiel.
Der Name könnte ein Schluck sein, aber er sagt nur, dass wir die „Fläche unter der Kurve“ (AUC) des „Receiver Characteristic Operator“ (ROC) berechnen. Verwirrt? Ich fühle dich! Ich war in deinen Schuhen. Aber keine Sorge, wir werden sehen, was diese Begriffe im Detail bedeuten und alles wird ein Kinderspiel!

Im Moment wissen wir nur, dass die AUC-ROC-Kurve uns hilft, zu visualisieren, wie gut unser Klassifikator für maschinelles Lernen funktioniert. Obwohl es nur für binäre Klassifizierungsprobleme funktioniert, werden wir gegen Ende sehen, wie wir es erweitern können, um auch Mehrklassenklassifizierungsprobleme zu bewerten.
Wir werden auch Themen wie Sensitivität und Spezifität behandeln, da diese Schlüsselthemen hinter der AUC-ROC-Kurve sind.
Ich schlage vor, den Artikel über Confusion Matrix durchzugehen, da er einige wichtige Begriffe vorstellt, die wir in diesem Artikel verwenden werden.
Inhaltsverzeichnis
- Was sind Sensitivität und Spezifität?
- Wahrscheinlichkeit von Vorhersagen
- Was ist die AUC-ROC-Kurve?
- Wie funktioniert die AUC-ROC-Kurve?
- AUC-ROC in Python
- AUC-ROC für die Klassifizierung mehrerer Klassen
Was sind Sensitivität und Spezifität?
So sieht eine Verwirrungsmatrix aus:
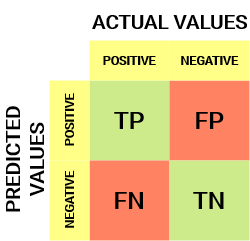
Aus der Verwirrungsmatrix können wir einige wichtige Metriken ableiten, die im vorherigen Artikel nicht behandelt wurden. Lassen Sie uns hier über sie sprechen.
Empfindlichkeit / True Positive Rate / Recall
![]()
Die Empfindlichkeit gibt an, welcher Anteil der positiven Klasse korrekt klassifiziert wurde.
Ein einfaches Beispiel wäre, zu bestimmen, welcher Anteil der tatsächlich kranken Menschen vom Modell korrekt erkannt wurde.
False Negative Rate
![]()
Die False Negative Rate (FNR) gibt an, welcher Anteil der positiven Klasse vom Klassifikator falsch klassifiziert wurde.
Eine höhere TPR und eine niedrigere FNR ist wünschenswert, da wir die positive Klasse korrekt klassifizieren wollen.
Spezifität / Wahre negative Rate
![]()
Die Spezifität gibt an, welcher Anteil der negativen Klasse korrekt klassifiziert wurde.
Am selben Beispiel wie bei der Sensitivität würde Spezifität bedeuten, den Anteil gesunder Menschen zu bestimmen, die vom Modell korrekt identifiziert wurden.
False Positive Rate
![]()
FPR gibt an, welcher Anteil der negativen Klasse vom Klassifikator falsch klassifiziert wurde.
Eine höhere TNR und eine niedrigere FPR ist wünschenswert, da wir die negative Klasse korrekt klassifizieren wollen.
Von diesen Metriken sind Sensitivität und Spezifität vielleicht die wichtigsten, und wir werden später sehen, wie diese verwendet werden, um eine Bewertungsmetrik zu erstellen. Aber vorher wollen wir verstehen, warum die Wahrscheinlichkeit der Vorhersage besser ist als die direkte Vorhersage der Zielklasse.
Wahrscheinlichkeit von Vorhersagen
Ein Klassifikationsmodell für maschinelles Lernen kann verwendet werden, um die tatsächliche Klasse des Datenpunkts direkt vorherzusagen oder seine Wahrscheinlichkeit, zu verschiedenen Klassen zu gehören, vorherzusagen. Letzteres gibt uns mehr Kontrolle über das Ergebnis. Wir können unseren eigenen Schwellenwert bestimmen, um das Ergebnis des Klassifikators zu interpretieren. Das ist manchmal klüger, als nur ein komplett neues Modell zu bauen!
Wenn Sie unterschiedliche Schwellenwerte für die Klassifizierung einer positiven Klasse für Datenpunkte festlegen, werden die Sensitivität und Spezifität des Modells versehentlich geändert. Und einer dieser Schwellenwerte wird wahrscheinlich ein besseres Ergebnis liefern als die anderen, je nachdem, ob wir die Anzahl der falsch negativen oder falsch positiven Ergebnisse senken möchten.
Schauen Sie sich die folgende Tabelle an:
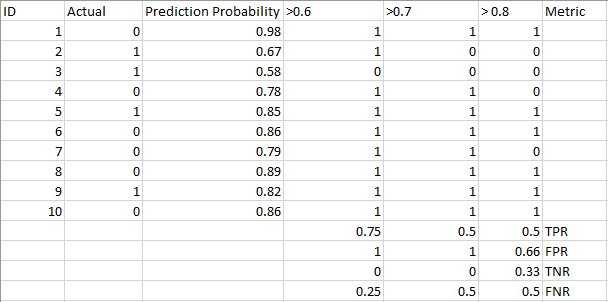
Die Metriken ändern sich mit den sich ändernden Schwellwerten. Wir können verschiedene Verwirrungsmatrizen generieren und die verschiedenen Metriken vergleichen, die wir im vorherigen Abschnitt besprochen haben. Aber das wäre nicht klug. Stattdessen können wir ein Diagramm zwischen einigen dieser Metriken erstellen, damit wir leicht visualisieren können, welcher Schwellenwert uns ein besseres Ergebnis liefert.
Die AUC-ROC-Kurve löst genau dieses Problem!
Was ist die AUC-ROC-Kurve?
Die ROC-Kurve (Receiver Operator Characteristic) ist eine Bewertungsmetrik für binäre Klassifizierungsprobleme. Es ist eine Wahrscheinlichkeitskurve, die den TPR gegen FPR bei verschiedenen Schwellwerten darstellt und im Wesentlichen das ‚Signal‘ vom ‚Rauschen‘ trennt. Die Fläche unter der Kurve (AUC) ist das Maß für die Fähigkeit eines Klassifikators, zwischen Klassen zu unterscheiden, und wird als Zusammenfassung der ROC-Kurve verwendet.
Je höher die AUC, desto besser ist die Leistung des Modells bei der Unterscheidung zwischen positiven und negativen Klassen.
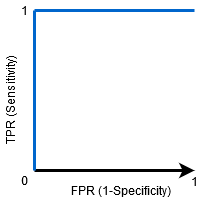
Wenn AUC = 1 ist, kann der Klassifikator alle positiven und negativen Klassenpunkte korrekt perfekt unterscheiden. Wenn die AUC jedoch 0 gewesen wäre, würde der Klassifikator alle Negativen als positiv und alle Positiven als negativ vorhersagen.
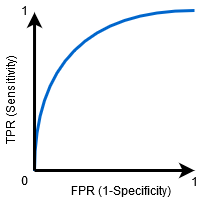
Wenn 0.5<AUC<1 besteht eine hohe Wahrscheinlichkeit, dass der Klassifikator die positiven Klassenwerte von den negativen Klassenwerten unterscheiden kann. Dies liegt daran, dass der Klassifikator in der Lage ist, mehr echte Positive und echte Negative als falsch negative und falsch Positive zu erkennen.
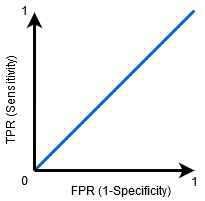
Wenn AUC=0,5 ist, kann der Klassifikator nicht zwischen positiven und negativen Klassenpunkten unterscheiden. Dies bedeutet, dass der Klassifikator entweder eine zufällige Klasse oder eine konstante Klasse für alle Datenpunkte vorhersagt.
Je höher also der AUC-Wert für einen Klassifikator ist, desto besser kann er zwischen positiven und negativen Klassen unterscheiden.
Wie funktioniert die AUC-ROC-Kurve?
In einer ROC-Kurve zeigt ein höherer Wert auf der X-Achse eine höhere Anzahl falsch positiver als wahr negativer Ergebnisse an. Während ein höherer Y-Achsenwert eine höhere Anzahl von echten Positiven als falsch Negativen anzeigt. Die Wahl des Schwellenwerts hängt also von der Fähigkeit ab, zwischen falsch positiven und falsch negativen Ergebnissen auszugleichen.
Lassen Sie uns etwas tiefer graben und verstehen, wie unsere ROC-Kurve für verschiedene Schwellenwerte aussehen würde und wie die Spezifität und Sensitivität variieren würden.
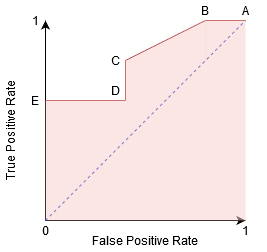
Wir können versuchen, dieses Diagramm zu verstehen, indem wir für jeden Punkt, der einem Schwellenwert entspricht, eine Verwirrungsmatrix generieren und über die Leistung unseres Klassifikators sprechen:
Punkt A ist dort, wo die Empfindlichkeit am höchsten und die Spezifität am niedrigsten ist. Dies bedeutet, dass alle positiven Klassenpunkte korrekt und alle negativen Klassenpunkte falsch klassifiziert werden.
Tatsächlich entspricht jeder Punkt auf der blauen Linie einer Situation, in der die wahre positive Rate der falsch positiven Rate entspricht.
Alle Punkte über dieser Linie entsprechen der Situation, in der der Anteil korrekt klassifizierter Punkte, die zur Positiven Klasse gehören, größer ist als der Anteil falsch klassifizierter Punkte, die zur negativen Klasse gehören.
Obwohl Punkt B die gleiche Sensitivität wie Punkt A hat, hat er eine höhere Spezifität. Dies bedeutet, dass die Anzahl der falsch negativen Klassenpunkte im Vergleich zum vorherigen Schwellenwert niedriger ist. Dies zeigt an, dass dieser Schwellenwert besser ist als der vorherige.
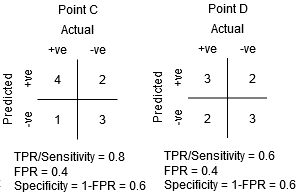
Zwischen den Punkten C und D ist die Sensitivität an Punkt C bei gleicher Spezifität höher als an Punkt D. Dies bedeutet, dass der Klassifikator für die gleiche Anzahl falsch klassifizierter negativer Klassenpunkte eine höhere Anzahl positiver Klassenpunkte vorhergesagt hat. Daher ist der Schwellenwert bei Punkt C besser als bei Punkt D.
Je nachdem, wie viele falsch klassifizierte Punkte wir für unseren Klassifikator tolerieren möchten, würden wir zwischen Punkt B oder C wählen, um vorherzusagen, ob Sie mich in PUBG besiegen können oder nicht.
„Falsche Hoffnungen sind gefährlicher als Ängste.“-J.R.R. Tolkein

Punkt E ist, wo die Spezifität am höchsten wird. Das heißt, es gibt keine vom Modell klassifizierten Fehlalarme. Das Modell kann alle negativen Klassenpunkte korrekt klassifizieren! Wir würden diesen Punkt wählen, wenn es unser Problem wäre, unseren Nutzern perfekte Songempfehlungen zu geben.
Können Sie anhand dieser Logik erraten, wo der Punkt, der einem perfekten Klassifikator entspricht, in der Grafik liegen würde?
Ja! Es würde sich in der oberen linken Ecke des ROC-Diagramms befinden, das der Koordinate (0, 1) in der kartesischen Ebene entspricht. Hier wären sowohl die Sensitivität als auch die Spezifität am höchsten und der Klassifikator würde alle positiven und negativen Klassenpunkte korrekt klassifizieren.
Die AUC-ROC-Kurve in Python verstehen
Jetzt können wir entweder die Sensitivität und Spezifität für jeden Schwellenwert manuell testen oder sklearn die Arbeit für uns erledigen lassen. Wir gehen definitiv mit letzterem!
Erstellen wir unsere beliebigen Daten mit der Methode sklearn make_classification:
Ich werde die Leistung von zwei Klassifikatoren auf diesem Datensatz testen:
Sklearn hat eine sehr potente Methode roc_curve(), die den ROC für Ihren Klassifikator in Sekundenschnelle berechnet! Es gibt die FPR-, TPR- und Schwellenwerte zurück:
Der AUC-Score kann mit der roc_auc_score() -Methode von sklearn berechnet werden:
0.9761029411764707 0.9233769727403157
Probieren Sie diesen Code im Live-Codierungsfenster unten aus:
Wir können die ROC-Kurven für die beiden Algorithmen auch mit matplotlib:
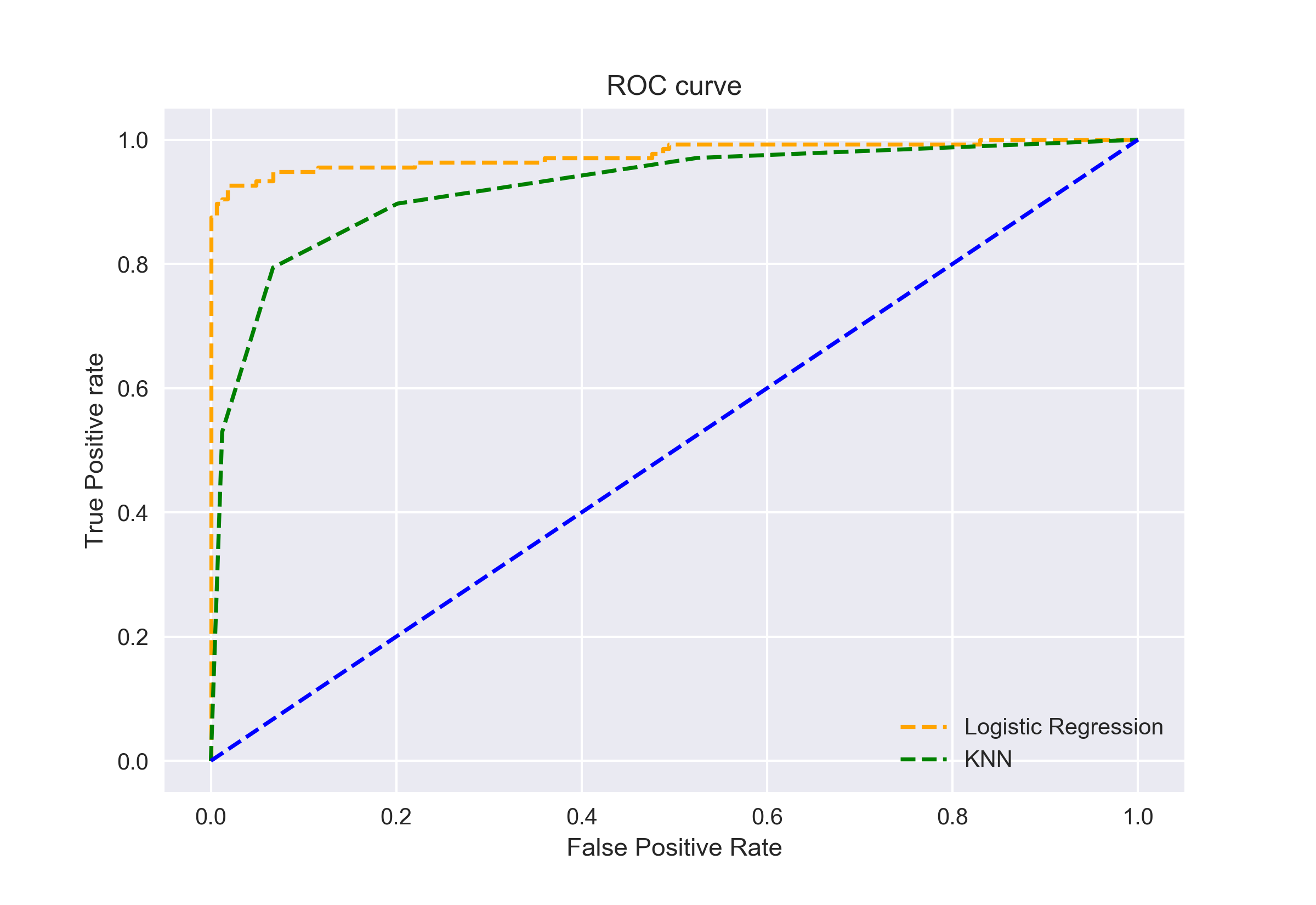
Aus dem Plot ist ersichtlich, dass die AUC für die Logistische Regression ROC curve höher ist als die für die KNN ROC curve. Daher können wir sagen, dass die logistische Regression die positive Klasse im Datensatz besser klassifiziert hat.
AUC-ROC für Mehrklassenklassifizierung
Wie ich bereits sagte, ist die AUC-ROC-Kurve nur für binäre Klassifizierungsprobleme. Aber wir können es auf Mehrklassenklassifizierungsprobleme erweitern, indem wir die One vs All-Technik verwenden.
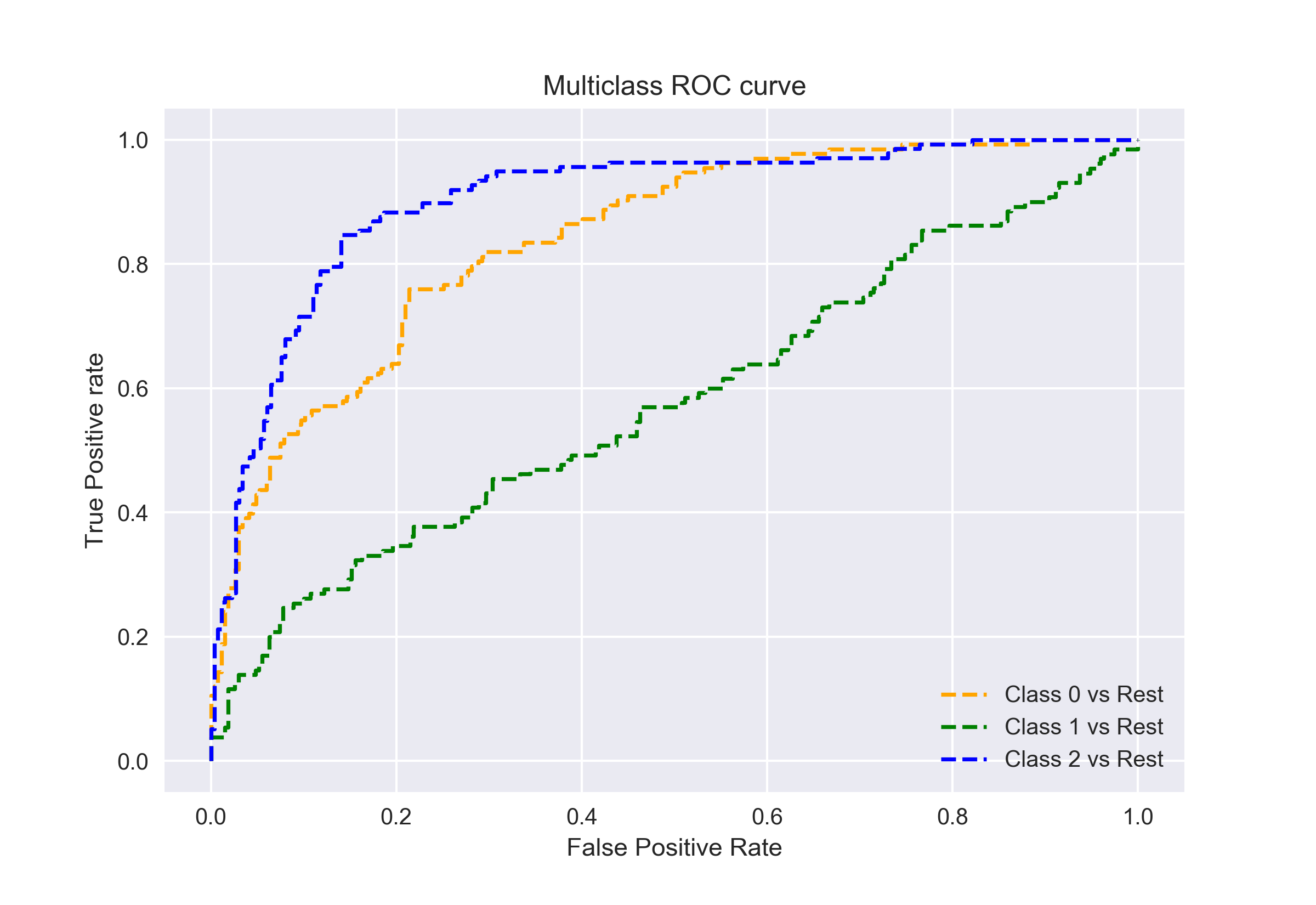
Wenn wir also drei Klassen 0, 1 und 2 haben, wird der ROC für Klasse 0 als Klassifizierung von 0 gegen nicht 0 , dh 1 und 2, generiert. Der ROC für Klasse 1 wird als Klassifizierung von 1 gegen nicht 1 usw. generiert.
Die ROC-Kurve für Mehrklassen-Klassifikationsmodelle kann wie folgt bestimmt werden:
Endnotizen
Ich hoffe, Sie fanden diesen Artikel nützlich, um zu verstehen, wie leistungsfähig die AUC-ROC-Kurvenmetrik bei der Messung der Leistung eines Klassifikators ist. Sie werden dies häufig in der Branche und sogar bei Data Science- oder Machine Learning-Hackathons verwenden. Machen Sie sich besser damit vertraut!
Wenn Sie weiter gehen, würde ich Ihnen die folgenden Kurse empfehlen, die Ihnen beim Aufbau Ihres Data Science-Scharfsinns hilfreich sein werden:
- Einführung in die Datenwissenschaft
- Angewandtes maschinelles Lernen
Sie können diesen Artikel auch in unserer mobilen APP lesen![]()

Leave a Reply