curva AUC-ROC na aprendizagem de máquinas claramente explicada
curva AUC-ROC – the Star Performer!você construiu seu modelo de aprendizagem de máquina – então, o que vem a seguir? Você precisa avaliá-lo e validar o quão bom (ou ruim) ele é, para que você possa então decidir se implementá-lo. É aí que entra a curva AUC-ROC.
o nome pode ser mouthful, mas é só dizer que estamos calculando a “área sob a curva” (AUC) de “operador característico do receptor” (ROC). Confuso? Eu entendo-te! Já estive no teu lugar. Mas não se preocupe, veremos o que esses termos significam em detalhes e tudo será canja!

por enquanto, saiba apenas que a curva AUC-ROC nos ajuda a visualizar o bom desempenho do nosso classificador de aprendizagem por máquina. Embora funcione apenas para problemas de classificação binária, veremos no final como podemos estendê-lo para avaliar problemas de classificação multi-classes também.
vamos cobrir tópicos como sensibilidade e especificidade, uma vez que estes são tópicos chave por trás da curva AUC-ROC.
eu sugiro passar pelo artigo sobre matriz de confusão, pois ele irá introduzir alguns termos importantes que nós estaremos usando neste artigo.
Índice
- Quais são a sensibilidade e especificidade?Qual é a curva AUC-ROC?como funciona a curva AUC-ROC?
- AUC-ROC em Python
- AUC-ROC para classificação Multi-classes
O que são sensibilidade e especificidade?
Esta é a aparência de uma matriz de confusão:
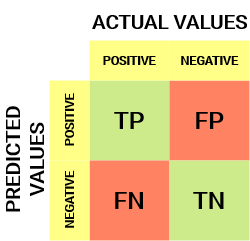
da matriz de confusão, podemos derivar algumas métricas importantes que não foram discutidas no artigo anterior. Vamos falar sobre eles aqui.
sensibilidade / taxa positiva verdadeira / Recall
![]()
sensibilidade nos diz que proporção da classe positiva ficou corretamente classificada.
um exemplo simples seria determinar que proporção dos doentes reais foram corretamente detectados pelo modelo.
taxa Falsa negativa
![]()
taxa Falsa negativa (FNR) diz-nos que proporção da classe positiva ficou incorrectamente classificada pelo classificador.
uma TPR mais elevada e uma FNR mais baixa é desejável uma vez que queremos classificar corretamente a classe positiva.
especificidade / taxa negativa verdadeira
![]()
a especificidade diz-nos que proporção da classe negativa ficou correctamente classificada.considerando o mesmo exemplo de sensibilidade, especificidade significaria determinar a proporção de pessoas saudáveis que foram corretamente identificadas pelo modelo.
taxa falso positivo
![]()
FPR nos diz que proporção da classe negativa ficou incorretamente classificada pelo classificador.
uma TNR superior e uma FPR inferior é desejável uma vez que queremos classificar corretamente a classe negativa.
destas métricas, sensibilidade e especificidade são talvez as mais importantes e veremos mais tarde como estas são usadas para construir uma métrica de avaliação. Mas antes disso, vamos entender por que a probabilidade de previsão é melhor do que prever a classe alvo diretamente.
probabilidade de previsões
um modelo de classificação de aprendizagem de máquina pode ser usado para prever a classe real do ponto de dados directamente ou prever a sua probabilidade de pertencer a diferentes classes. Este último dá-nos mais controlo sobre o resultado. Podemos determinar o nosso próprio limiar para interpretar o resultado do Classificador. Isto é às vezes mais prudente do que apenas construir um modelo completamente novo!a fixação de limiares diferentes para a classificação da classe positiva para os pontos de dados alterará inadvertidamente a sensibilidade e a especificidade do modelo. E um desses limiares provavelmente dará um melhor resultado do que os outros, dependendo se estamos buscando diminuir o número de falsos negativos ou falsos positivos.veja a tabela abaixo.:
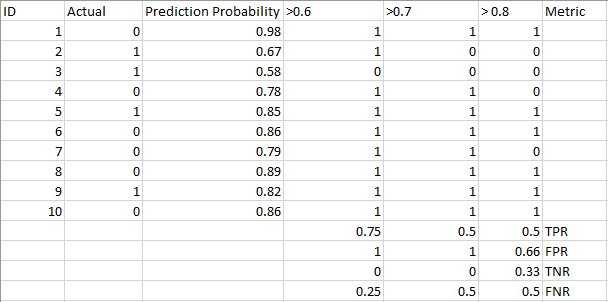
as métricas mudam com os valores limiar em mudança. Podemos gerar matrizes de confusão diferentes e comparar as várias métricas que discutimos na seção anterior. Mas isso não seria prudente. Em vez disso, o que podemos fazer é gerar um enredo entre algumas dessas métricas para que possamos facilmente visualizar qual limiar está nos dando um resultado melhor.a curva AUC-ROC resolve precisamente esse problema!qual é a curva AUC-ROC?
a curva característica do operador receptor (ROC) é uma métrica de avaliação para problemas de classificação binária. É uma curva de probabilidade que traça o TPR contra o FPR em vários valores-limite e separa essencialmente o “sinal” do “ruído”. A área sob a curva (AUC) é a medida da capacidade de um classificador distinguir entre classes e é usado como um resumo da curva ROC.
quanto maior a AUC, melhor o desempenho do modelo na distinção entre as classes positiva e negativa.
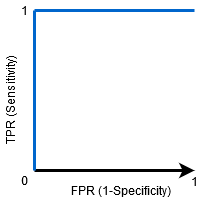
quando AUC = 1, Então o classificador é capaz de distinguir perfeitamente entre todos os pontos de classe positivos e negativos correctamente. Se, no entanto, a AUC tivesse sido 0, então o classificador estaria prevendo todos os negativos como positivos, e todos os positivos como negativos.
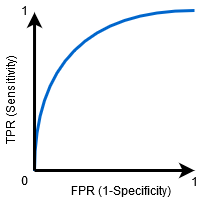
Quando 0.5 <AUC<1, Existe uma grande probabilidade de o classificador ser capaz de distinguir os valores de classe positivos dos valores de classe negativos. Isto é assim porque o classificador é capaz de detectar mais números de positivos verdadeiros e negativos verdadeiros do que falsos negativos e falsos positivos.
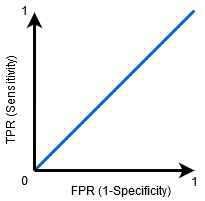
quando AUC=0, 5, então o classificador não é capaz de distinguir entre pontos de classe positivos e negativos. Ou seja, o classificador está prevendo classe aleatória ou classe constante para todos os pontos de dados.
assim, quanto maior o valor da AUC para um classificador, melhor a sua capacidade de distinguir entre classes positivas e negativas.como funciona a curva AUC-ROC?
numa curva ROC, um valor maior do eixo X indica um número maior de falsos positivos do que negativos verdadeiros. Enquanto um maior valor do eixo Y indica um maior número de positivos verdadeiros do que falsos negativos. Assim, a escolha do limiar depende da capacidade de equilíbrio entre falsos positivos e falsos negativos.
vamos cavar um pouco mais fundo e entender como a nossa curva ROC seria para diferentes valores limiar e como a especificidade e sensibilidade variaria.
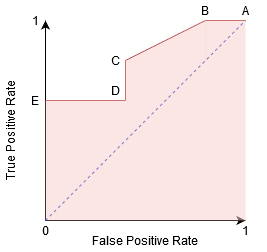
podemos tentar entender esse gráfico com a geração de uma matriz de confusão para cada ponto correspondente a um limite e falar sobre o desempenho do nosso classificador:
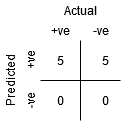
o Ponto A é onde a Sensibilidade é a maior e a Especificidade mais baixa. Isto significa que todos os pontos de classe positivos são classificados corretamente e todos os pontos de classe negativos são classificados incorretamente.
de facto, qualquer ponto da linha azul corresponde a uma situação em que a taxa verdadeira positiva é igual a taxa falsa positiva.
todos os pontos acima desta linha correspondem à situação em que a proporção de pontos correctamente classificados pertencentes à classe positiva é superior à proporção de pontos incorrectamente classificados pertencentes à classe negativa.
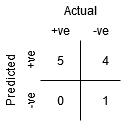
Embora o Ponto B tem a mesma Sensibilidade que o Ponto A, ele tem uma maior Especificidade. O que significa que o número de pontos de classe incorretamente negativos é menor em comparação com o limiar anterior. Isto indica que este limiar é melhor do que o anterior.
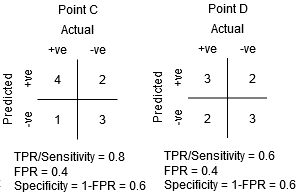
entre os pontos C E D, A sensibilidade no ponto C é superior ao ponto D para a mesma especificidade. Isto significa que, para o mesmo número de pontos de classe negativos incorretamente classificados, O classificador previu um maior número de pontos de classe positivos. Portanto, o limite no ponto C é melhor do que o ponto D.
Agora, dependendo de quantas incorretamente classificados pontos queremos tolerar por nosso classificador, que iria escolher entre o ponto B ou C para prever se você pode me derrotar em PUBG ou não.
“falsas esperanças são mais perigosas do que medos.”- J. R. R. Tolkein

ponto E é onde a especificidade se torna mais elevada. Significa que não há falsos positivos classificados pelo modelo. O modelo pode classificar corretamente todos os pontos de classe negativos! Nós escolheríamos este ponto se nosso problema fosse dar recomendações perfeitas da música aos nossos usuários.
seguindo esta lógica, você pode adivinhar onde o ponto correspondente a um classificador perfeito estaria no grafo?Sim! Seria no canto superior esquerdo do grafo de ROC correspondente à coordenada (0, 1) no plano cartesiano. É aqui que ambos, a sensibilidade e especificidade, seriam os mais altos e o classificador classificaria corretamente todos os pontos de classe positivos e negativos.
compreender a curva AUC-ROC em Python
agora, ou podemos testar manualmente a sensibilidade e especificidade para cada limiar ou deixar o sklearn fazer o trabalho por nós. Definitivamente vamos com o último!
vamos criar os nossos dados arbitrários usando o método sklearn make_classification:
I will test the performance of two classifiers on this dataset:
Sklearn has a very potent method roc_curve() which computes the ROC for your classifier in a matter of seconds! Ele retorna a FPR, TPR, e os valores limite:
A AUC pontuação pode ser calculada usando a roc_auc_score() método de sklearn:
0.9761029411764707 0.9233769727403157
Tente este código no live coding janela abaixo:
também podemos plotar as curvas ROC para os dois algoritmos utilizando matplotlib:
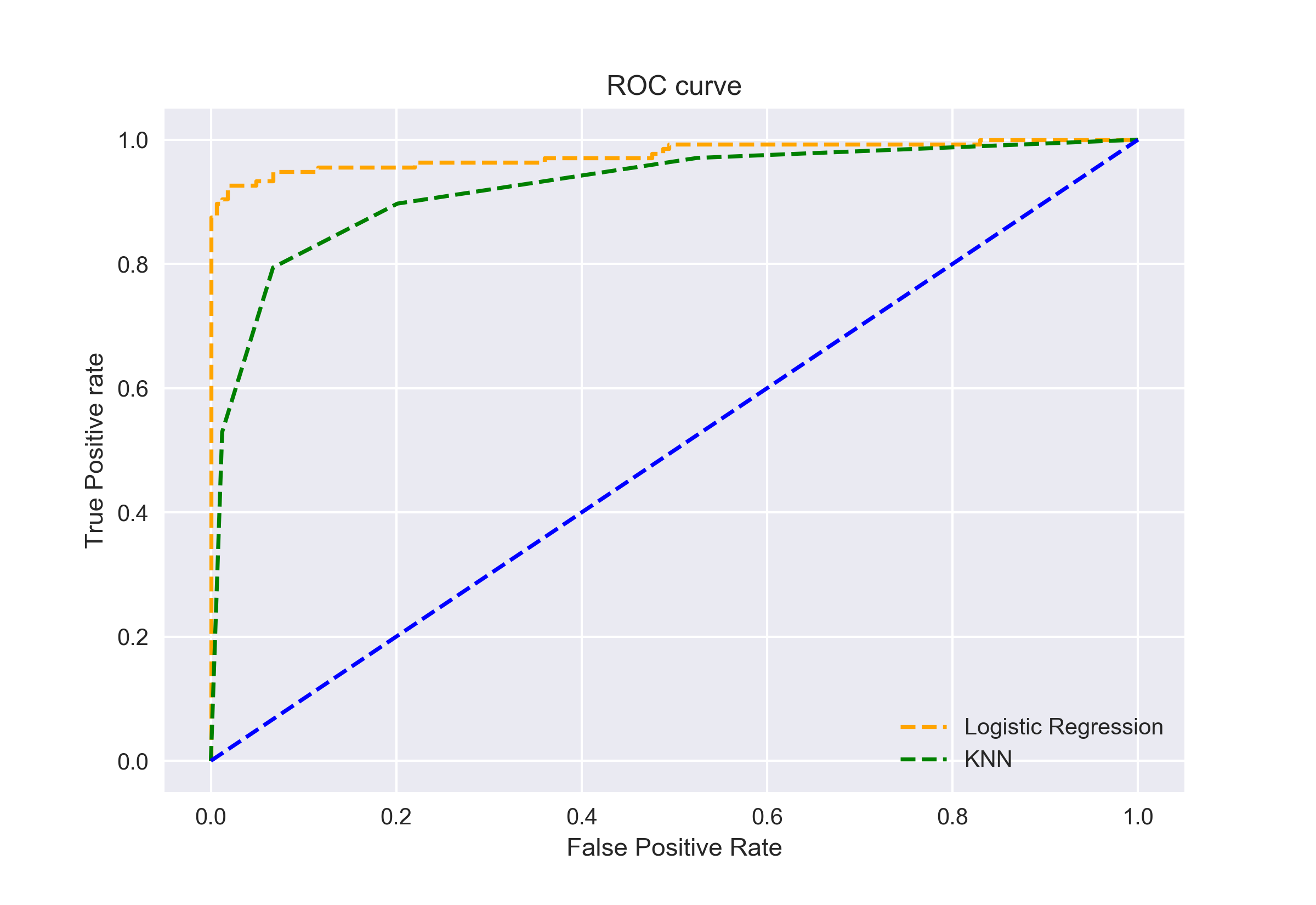
é evidente a partir do gráfico que a AUC para a curva de Roc de regressão logística é superior à da curva de Roc de KNN. Portanto, podemos dizer que a regressão logística fez um melhor trabalho de classificar a classe positiva no conjunto de dados.
AUC-ROC para classificação multi-Classe
como eu disse antes, a curva AUC-ROC é apenas para problemas de classificação binária. Mas podemos estendê-lo a problemas de classificação multiclass usando a técnica One vs All.
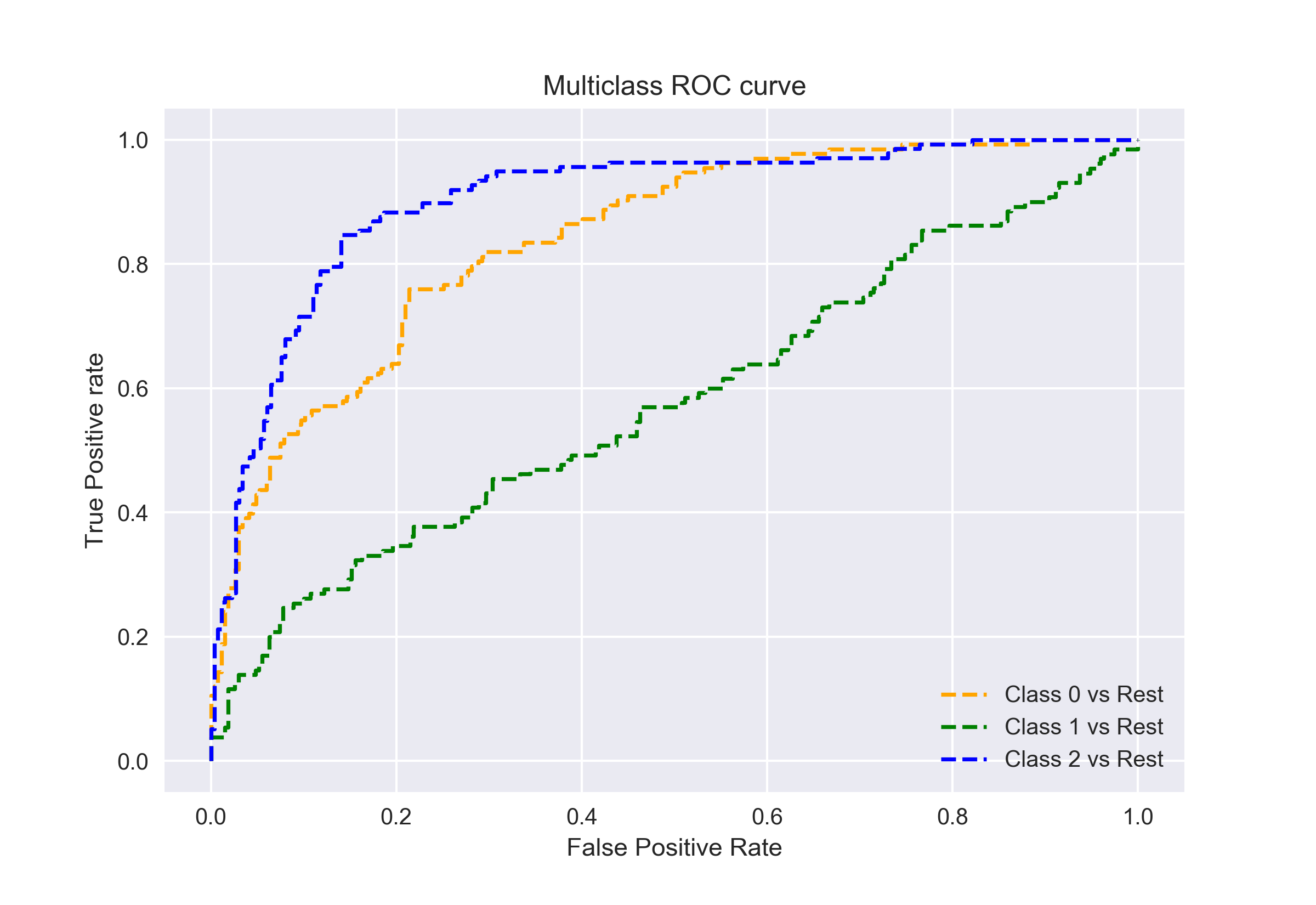
assim, se tivermos três classes 0, 1 e 2, o ROC para a classe 0 será gerado como Classificando 0 contra Não 0, ou seja, 1 e 2. O ROC para a classe 1 será gerado como classificando 1 contra não 1, e assim por diante.
A curva ROC para multi-classe de modelos de classificação pode ser determinada como a seguir:
Notas Finais
espero que você encontrou este artigo útil na compreensão de como poderoso IEA-curva ROC métrica está em medir o desempenho de um classificador. Você vai usar isso muito na indústria e até mesmo em ciência de dados ou hackathons de aprendizagem de máquinas. É melhor familiarizares-te com isso!
Indo mais longe do que eu gostaria de recomendar a você cursos que serão úteis na construção de seus dados de ciências perspicácia:
- Introdução à Ciência de Dados
- Aplicada Máquina de Aprendizagem
Você também pode ler este artigo em nosso APLICATIVO Móvel![]()

Leave a Reply