krzywa AUC-ROC w uczeniu maszynowym jasno wyjaśniona
krzywa AUC-ROC – Gwiazda!
zbudowałeś swój model uczenia maszynowego – co dalej? Musisz go ocenić i zweryfikować, jak dobry (lub zły) jest, więc możesz zdecydować, czy go zaimplementować. Tutaj pojawia się krzywa AUC-ROC.
nazwa może być ustna, ale to tylko stwierdzenie, że obliczamy „pole pod krzywą” (AUC) „operatora charakterystycznego odbiornika” (ROC). Zdezorientowany? Rozumiem cię! Byłem na Twoim miejscu. Ale nie martw się, zobaczymy, co te terminy oznaczają w szczegółach i wszystko będzie bułką z masłem!

na razie wiedz, że krzywa AUC-ROC pomaga nam zwizualizować skuteczność naszego klasyfikatora uczenia maszynowego. Chociaż działa tylko dla binarnych problemów klasyfikacyjnych, zobaczymy pod koniec, w jaki sposób możemy go rozszerzyć, aby również ocenić wieloklasowe problemy klasyfikacyjne.
omówimy również takie tematy jak czułość i specyficzność, ponieważ są to kluczowe tematy leżące u podstaw krzywej AUC-ROC.
proponuję przejrzeć artykuł o macierzy zamieszania, ponieważ wprowadzi on kilka ważnych terminów, których będziemy używać w tym artykule.
spis treści
- czym jest czułość i swoistość?
- prawdopodobieństwo przewidywań
- czym jest krzywa AUC-ROC?
- jak działa Krzywa AUC-ROC?
- AUC-ROC w Pythonie
- AUC-ROC dla klasyfikacji Wieloklasowej
czym jest czułość i swoistość?
tak wygląda macierz zamieszania:
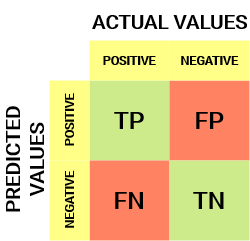
z macierzy splątania możemy uzyskać kilka ważnych wskaźników, które nie zostały omówione w poprzednim artykule. Porozmawiajmy o nich tutaj.
czułość / True Positive Rate/Recall
![]()
czułość mówi nam, jaka część klasy dodatniej została prawidłowo sklasyfikowana.
prostym przykładem byłoby określenie, jaki odsetek faktycznie chorych został prawidłowo wykryty przez model.
Współczynnik fałszywie ujemny
![]()
Współczynnik fałszywie ujemny (FNR) mówi nam, jaka część klasy dodatniej została błędnie sklasyfikowana przez klasyfikatora.
wyższy TPR i niższy FNR jest pożądany, ponieważ chcemy poprawnie zaklasyfikować klasę dodatnią.
swoistość/prawdziwa liczba ujemna
![]()
swoistość mówi nam, jaka część klasy ujemnej została prawidłowo zaklasyfikowana.
biorąc ten sam przykład co w przypadku czułości, swoistość oznaczałaby określenie odsetka zdrowych osób, które zostały prawidłowo zidentyfikowane przez model.
Współczynnik fałszywie dodatni
![]()
FPR mówi nam, jaka część ujemnej klasy została błędnie sklasyfikowana przez klasyfikatora.
wyższy TNR i niższy FPR jest pożądany, ponieważ chcemy poprawnie zaklasyfikować klasę ujemną.
spośród tych wskaźników czułość i specyficzność są chyba najważniejsze i zobaczymy później, jak są one wykorzystywane do budowy metryki oceny. Ale zanim to nastąpi, zrozumiemy, dlaczego prawdopodobieństwo przewidywania jest lepsze niż przewidywanie klasy docelowej bezpośrednio.
prawdopodobieństwo przewidywań
model klasyfikacji uczenia maszynowego może być użyty do bezpośredniego przewidywania rzeczywistej klasy punktu danych lub przewidywania jego prawdopodobieństwa przynależności do różnych klas. To ostatnie daje nam większą kontrolę nad wynikiem. Możemy określić własny próg, aby zinterpretować wynik klasyfikatora. Jest to czasami bardziej rozważne niż tylko budowanie zupełnie nowego modelu!
ustawienie różnych progów klasyfikacji klasy dodatniej dla punktów danych spowoduje niezamierzoną zmianę czułości i specyficzności modelu. A jeden z tych progów prawdopodobnie da lepszy wynik niż pozostałe, w zależności od tego, czy zamierzamy obniżyć liczbę fałszywych negatywów, czy fałszywych alarmów.
zapoznaj się z poniższą tabelą:
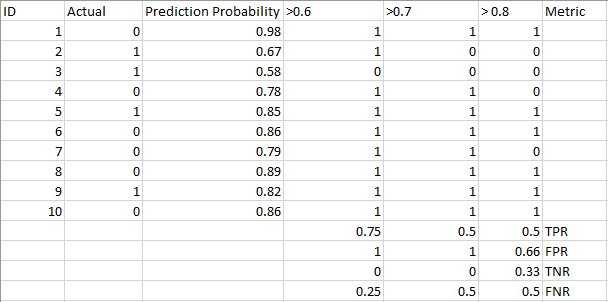
metryki zmieniają się wraz ze zmieniającymi się wartościami progowymi. Możemy generować różne macierze zamieszania i porównywać różne metryki, które omówiliśmy w poprzedniej sekcji. Ale to nie byłoby rozsądne. Zamiast tego możemy wygenerować wykres między niektórymi z tych wskaźników, abyśmy mogli łatwo zwizualizować, który próg daje nam lepszy wynik.
krzywa AUC-ROC rozwiązuje właśnie ten problem!
co to jest krzywa AUC-ROC?
krzywa charakterystyki operatora odbiornika (Roc) jest metryką oceny problemów z klasyfikacją binarną. Jest to krzywa prawdopodobieństwa, która wykreśla TPR przeciwko FPR przy różnych wartościach progowych i zasadniczo oddziela „sygnał” od „szumu”. Pole pod krzywą (AUC) jest miarą zdolności klasyfikatora do rozróżniania klas i jest używane jako podsumowanie krzywej ROC.
im wyższa wartość AUC, tym lepsza wydajność modelu przy rozróżnianiu klas dodatnich i ujemnych.
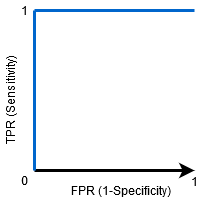
gdy AUC = 1, klasyfikator jest w stanie prawidłowo rozróżnić wszystkie pozytywne i negatywne punkty klasy. Gdyby jednak AUC było równe 0, klasyfikator przewidywałby wszystkie negatywy jako pozytywy, a wszystkie pozytywy jako negatywy.
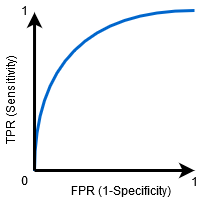
Gdy 0.5<AUC<1, Istnieje duża szansa, że klasyfikator będzie w stanie odróżnić wartości klasy dodatniej od wartości klasy ujemnej. Dzieje się tak, ponieważ klasyfikator jest w stanie wykryć więcej liczb prawdziwych pozytywów i prawdziwych negatywów niż fałszywych negatywów i fałszywych pozytywów.
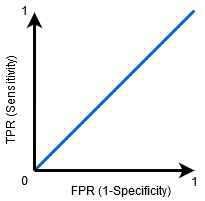
gdy AUC=0,5, klasyfikator nie jest w stanie rozróżnić dodatnich i ujemnych punktów klasy. Oznacza to, że albo klasyfikator przewiduje klasę losową, albo klasę stałą dla wszystkich punktów danych.
Tak więc im wyższa wartość AUC dla klasyfikatora, tym lepsza jest jego zdolność do rozróżniania klas dodatnich i ujemnych.
jak działa Krzywa AUC-ROC?
w krzywej ROC wyższa wartość osi X oznacza większą liczbę fałszywych alarmów niż Prawdziwych negatywów. Podczas gdy wyższa wartość osi Y oznacza większą liczbę prawdziwych pozytywów niż fałszywych negatywów. Tak więc wybór progu zależy od zdolności do równowagi między fałszywymi alarmami i fałszywymi negatywami.
zagłębimy się nieco głębiej i zrozumiemy, jak wyglądałaby nasza krzywa ROC dla różnych wartości progowych oraz jak różniłaby się swoistość i czułość.
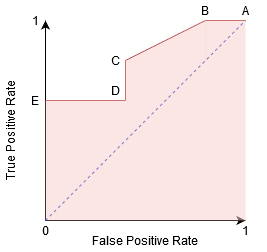
możemy spróbować zrozumieć ten wykres, generując macierz pomieszania dla każdego punktu odpowiadającego progowi i mówić o wydajności naszego klasyfikatora:
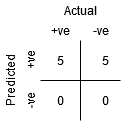
punkt A jest tam, gdzie czułość jest najwyższa, a swoistość najniższa. Oznacza to, że wszystkie pozytywne punkty klasy są klasyfikowane poprawnie, a wszystkie negatywne punkty klasy są klasyfikowane nieprawidłowo.
w rzeczywistości każdy punkt na niebieskiej linii odpowiada sytuacji, w której rzeczywista wartość dodatnia jest równa wartości fałszywie dodatniej.
wszystkie punkty powyżej tej linii odpowiadają sytuacji, w której odsetek prawidłowo sklasyfikowanych punktów należących do klasy dodatniej jest większy niż odsetek nieprawidłowo sklasyfikowanych punktów należących do klasy ujemnej.
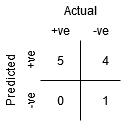
chociaż punkt B ma taką samą czułość jak punkt A, ma wyższą swoistość. Oznacza to, że liczba nieprawidłowo ujemnych punktów klasy jest niższa w porównaniu do poprzedniego progu. Oznacza to, że próg ten jest lepszy niż poprzedni.
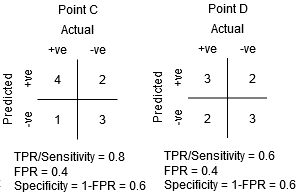
teraz, w zależności od tego, ile nieprawidłowo sklasyfikowanych punktów chcemy tolerować dla naszego klasyfikatora, wybieramy między punktem B lub C, aby przewidzieć, czy możesz pokonać mnie w PUBG, czy nie.
„fałszywe nadzieje są bardziej niebezpieczne niż lęki.”- J. R. R. Tolkiena

punkt E to miejsce, w którym specyficzność staje się najwyższa. Oznacza to, że nie ma fałszywych alarmów sklasyfikowanych przez model. Model może poprawnie zaklasyfikować wszystkie ujemne punkty klasy! Wybralibyśmy ten punkt, gdyby naszym problemem było podanie doskonałych rekomendacji piosenek naszym użytkownikom.
idąc tą logiką, możesz zgadnąć, gdzie punkt odpowiadający klasyfikatorowi doskonałemu leżałby na wykresie?
tak! Znajdowałby się w lewym górnym rogu grafu ROC odpowiadającego współrzędnej (0, 1) na płaszczyźnie kartezjańskiej. To tutaj zarówno czułość, jak i swoistość byłyby najwyższe, a klasyfikator prawidłowo zaklasyfikowałby wszystkie pozytywne i negatywne punkty klasy.
zrozumienie krzywej AUC-ROC w Pythonie
teraz możemy ręcznie przetestować czułość i swoistość dla każdego progu lub pozwolić sklearn wykonać zadanie za nas. Zdecydowanie wybieramy to drugie!
stwórzmy dowolne dane używając metody skleparn make_classification:
przetestuję wydajność dwóch klasyfikatorów na tym zbiorze danych:
Skleparn ma bardzo silną metodę roc_curve (), która oblicza ROC dla Twojego klasyfikatora w ciągu kilku sekund! Zwraca wartości FPR, TPR i wartości progowe:
wynik AUC można obliczyć za pomocą metody roc_auc_score() w sklepie:
0.9761029411764707 0.9233769727403157
wypróbuj ten kod w oknie live coding poniżej:
możemy również narysować krzywe ROC dla dwóch algorytmów za pomocą matplotlib:
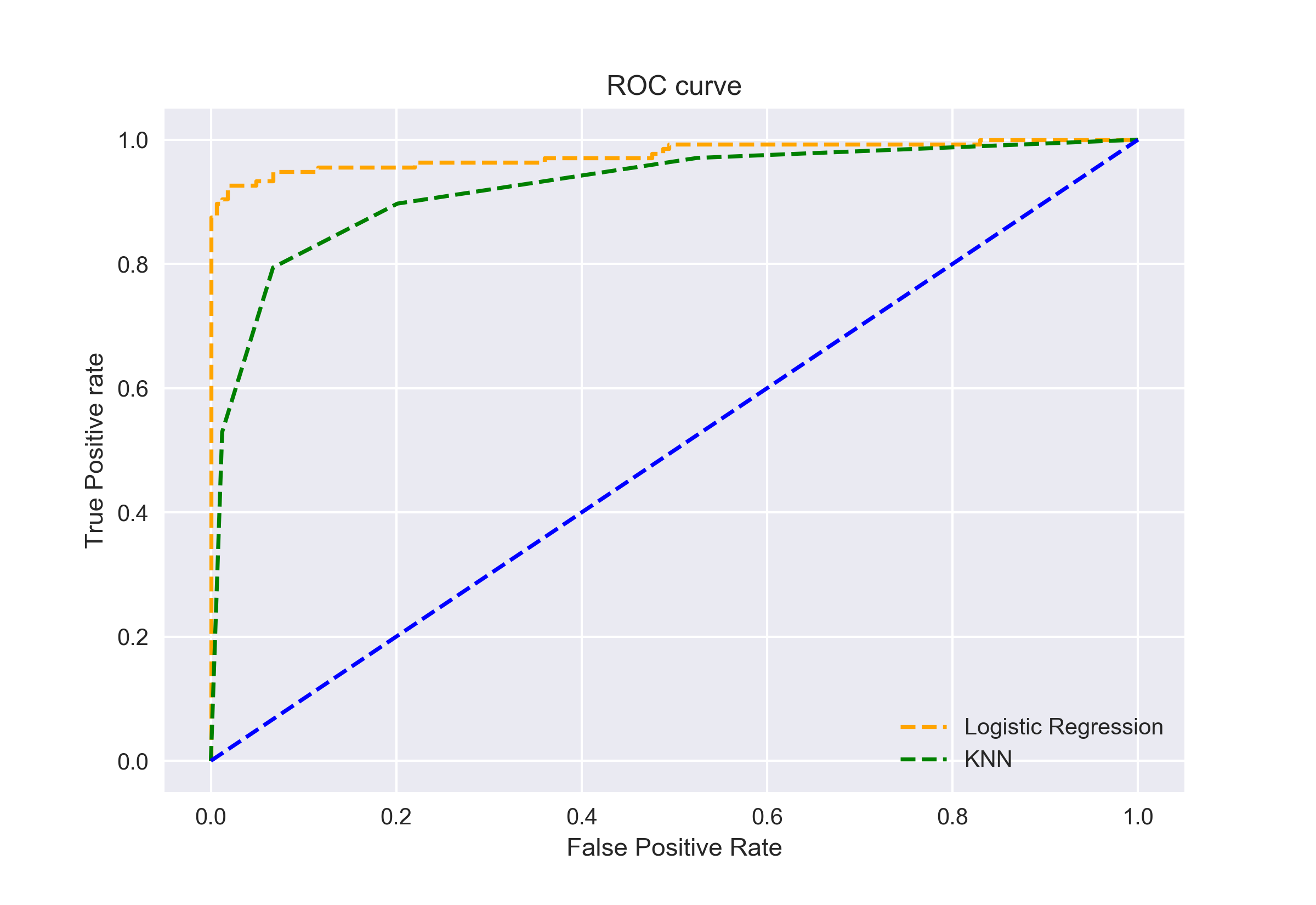
z wykresu wynika, że AUC dla krzywej Roc regresji logistycznej jest wyższe niż dla krzywej ROC KNN. Dlatego możemy powiedzieć, że regresja logistyczna lepiej sklasyfikowała klasę pozytywną w zbiorze danych.
AUC-ROC dla klasyfikacji Wieloklasowej
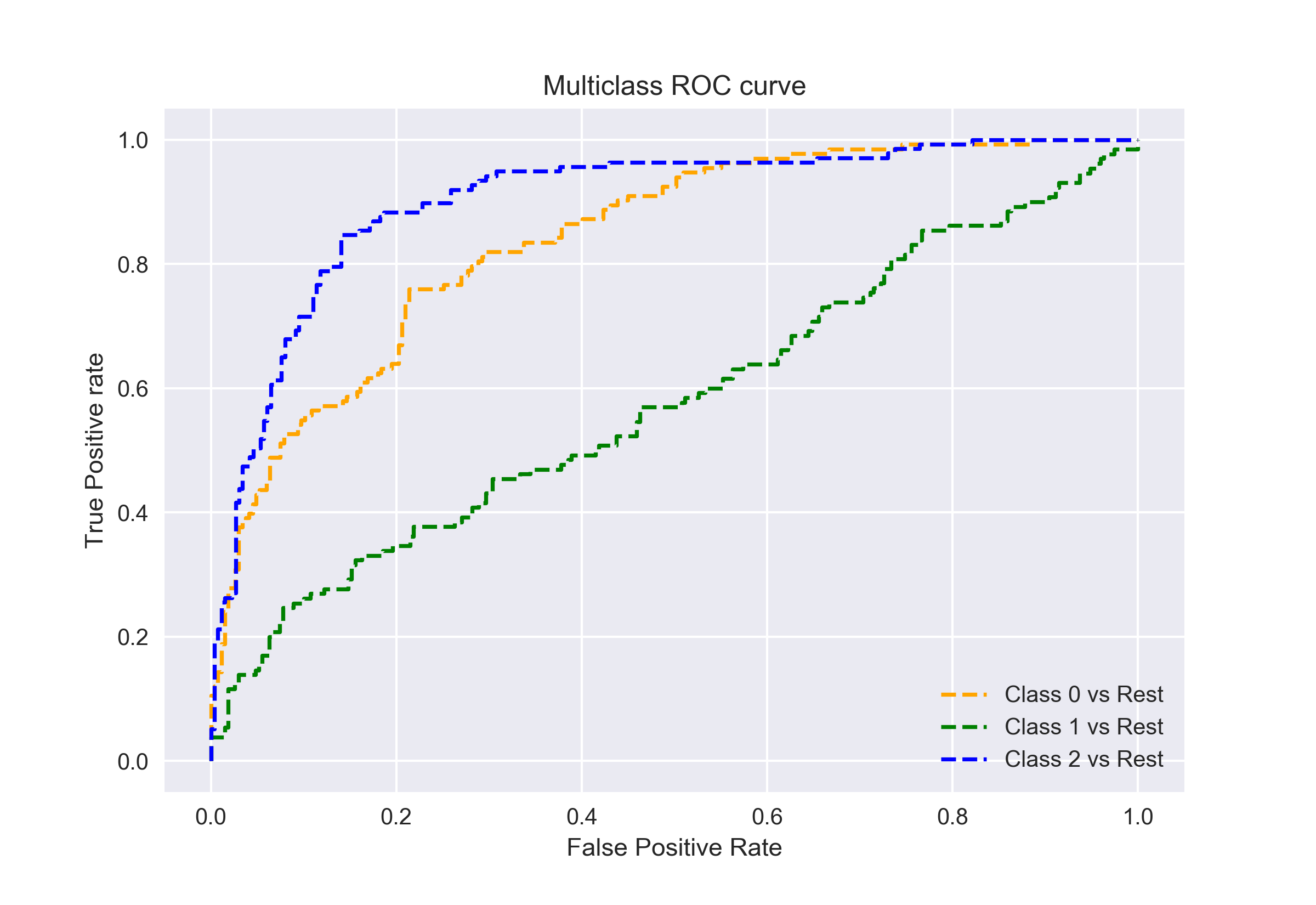
jak już mówiłem, krzywa AUC-ROC jest tylko dla problemów z klasyfikacją binarną. Ale możemy rozszerzyć go na problemy klasyfikacji multiclass przy użyciu techniki One vs All.
więc, jeśli mamy trzy klasy 0, 1 i 2, ROC dla klasy 0 zostanie wygenerowany jako klasyfikujący 0 przeciwko Nie 0, czyli 1 i 2. ROC dla klasy 1 zostanie wygenerowany jako klasyfikowanie 1 przeciwko nie 1, i tak dalej.
krzywą ROC dla modeli klasyfikacji wielu klas można określić jak poniżej:
Uwagi końcowe
mam nadzieję, że ten artykuł okazał się przydatny w zrozumieniu, jak potężna jest metryka krzywej AUC-ROC w pomiarze wydajności klasyfikatora. Wykorzystasz to często w branży, a nawet w hackatonach data science lub machine learning. Lepiej się z tym zapoznaj!
idąc dalej polecam Ci następujące kursy, które będą przydatne w budowaniu wiedzy o danych:
- Wprowadzenie do nauki o danych
- Applied Machine Learning
możesz również przeczytać ten artykuł w naszej aplikacji mobilnej![]()

Leave a Reply