UNION All Optimization
sammenkoblingen av to eller flere datasett er oftest uttrykt I T-SQL ved hjelp avUNION ALL – klausulen. GITT AT SQL Server optimizer ofte kan omorganisere ting som sammenføyninger og aggregater for å forbedre ytelsen, er DET ganske rimelig å forvente AT SQL Server også vil vurdere å omorganisere sammenkoblingsinnganger, der dette vil gi en fordel. For eksempel kan optimalisatoren vurdere fordelene ved å skrive om A UNION ALL B som B UNION ALL A.
FAKTISK GJØR SQL Server optimizer ikke dette. Mer presist, det var noen begrenset støtte for sammenkjeding input omorganisering I SQL Server utgivelser opp til 2008 R2, men dette ble fjernet I SQL Server 2012, og har ikke dukket siden.
SQL Server 2008 R2
Intuitivt er rekkefølgen på sammenkoblingsinnganger bare viktig hvis det er et radmål. SOM standard OPTIMALISERER SQL Server utførelsesplaner på grunnlag av at alle kvalifiserende rader returneres til klienten. Når et radmål er i kraft, prøver optimizer å finne en utførelsesplan som vil produsere de første radene raskt.
Radmål kan settes på flere måter, for eksempel ved å bruke TOP, en FAST n spørringstips, eller ved å bruke EXISTS (som etter sin natur må finne maksimalt en rad). Hvor det ikke er radmål (dvs. klienten krever alle rader), spiller det ingen rolle i hvilken rekkefølge sammenkoblingsinngangene leses: Hver inngang vil bli fullstendig behandlet til slutt i alle fall.
begrenset støtte i versjoner opp TIL SQL Server 2008 R2 gjelder der det er et mål for nøyaktig en rad. I denne bestemte situasjonen vil SQL Server omorganisere sammenkoblingsinnganger på grunnlag av forventet kostnad.
Dette gjøres ikke under kostnadsbasert optimalisering (som man kunne forvente), men heller som en siste liten post-optimalisering omskrivning av normal optimizer utgang. Denne ordningen har fordelen av ikke å øke den kostnadsbaserte plan søk plass (potensielt ett alternativ for hver mulig omorganisering), samtidig produsere en plan som er optimalisert for å returnere den første raden raskt.
Eksempler
følgende eksempler bruker to tabeller med identisk innhold: en million rader med heltall fra en til en million. En tabell er en haug uten nonclustered indekser; den andre har en unik gruppert indeks:
CREATE TABLE dbo.Expensive( Val bigint NOT NULL); CREATE TABLE dbo.Cheap( Val bigint NOT NULL, CONSTRAINT UNIQUE CLUSTERED (Val));GOINSERT dbo.Cheap WITH (TABLOCKX) (Val)SELECT TOP (1000000) Val = ROW_NUMBER() OVER (ORDER BY SV1.number)FROM master.dbo.spt_values AS SV1CROSS JOIN master.dbo.spt_values AS SV2ORDER BY ValOPTION (MAXDOP 1);GOINSERT dbo.Expensive WITH (TABLOCKX) (Val)SELECT C.ValFROM dbo.Cheap AS COPTION (MAXDOP 1);
ingen Radmål
følgende spørring ser etter de samme radene i hver tabell, og returnerer sammenkobling av de to setter:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005;
:
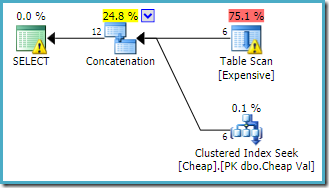
advarselen på roten SELECT operatøren varsler oss om den åpenbare manglende indeksen på heap-bordet. Advarselen På Tabellen Scan operatør er lagt Til Av Sentry One Plan Explorer. Det er å trekke vår oppmerksomhet til i / O kostnaden av rest predikat skjult i skanningen.
rekkefølgen på inngangene til Sammenkoblingen spiller ingen rolle her, fordi vi ikke har satt et radmål. Begge innganger vil bli fullt lese for å returnere alle resultat rader. Av interesse (selv om dette ikke er garantert) legg merke til at rekkefølgen på inngangene følger tekstens rekkefølge av den opprinnelige spørringen. Vær også oppmerksom på at rekkefølgen på de endelige resultatrader ikke er spesifisert heller, siden vi ikke brukte et toppnivåORDER BY – klausul. Vi vil anta at det er bevisst og endelig bestilling er ubetydelig for oppgaven ved hånden.
hvis vi reverserer den skriftlige rekkefølgen av tabellene i spørringen slik:
SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 UNION ALL SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005;
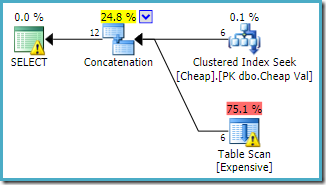 union alle med reverserte innganger
union alle med reverserte innganger
begge spørringene kan forventes å ha samme ytelsesegenskaper, da de utfører de samme operasjonene, bare i en annen rekkefølge.
Med Et Radmål
det Er klart at mangelen på indeksering på heap-bordet normalt vil gjøre det dyrere å finne bestemte rader sammenlignet med samme operasjon på gruppebordet. Hvis vi spør optimizer for en plan som returnerer den første raden raskt, forventer VI AT SQL Server skal omorganisere sammenkoblingsinngangene slik at den billige grupperte tabellen blir konsultert først.
Bruke spørringen som nevner heap-tabellen først, og bruke ET raskt 1-spørringstips til å angi radmålet:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005OPTION (FAST 1);
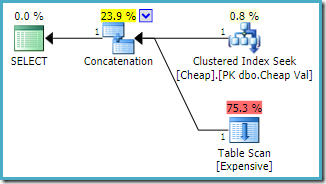 union alle med et radmål på 2008 r2
union alle med et radmål på 2008 r2
legg merke til at sammenkoblingsinngangene er omorganisert for å redusere de estimerte kostnadene ved å returnere den første raden. Merk også at manglende indeks og gjenværende i/O advarsler har forsvunnet. Verken problemet er av betydning med denne planen form når målet er å returnere en enkelt rad så raskt som mulig.
samme spørring utført PÅ SQL Server-2016 (ved hjelp av enten kardinalitet estimeringsmodell) er:
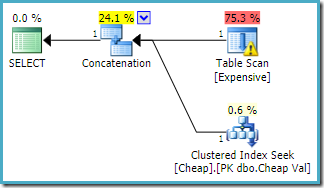
SQL Server-2016 HAR ikke omorganisert kjede sammen innganger. Plan Explorer i / O advarsel har returnert, men dessverre optimizer har ikke produsert en manglende indeks advarsel denne gangen (selv om det er relevant).
Generell omorganisering
som nevnt, er post-optimalisering omskrivning som omorganiserer sammenkoblingsinnganger bare effektiv for:
- SQL Server 2008 R2 og tidligere
- et radmål med nøyaktig en
Hvis vi virkelig bare vil ha en rad returnert, i stedet For en plan optimalisert for å returnere den første raden raskt (men som til slutt vil returnere alle rader), kan vi bruke enTOP klausul med et avledet bord eller felles tabelluttrykk (CTE):
SELECT TOP (1) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UA;
på sql server 2008 r2 eller tidligere, gir dette den optimale omordnede inndataplanen:
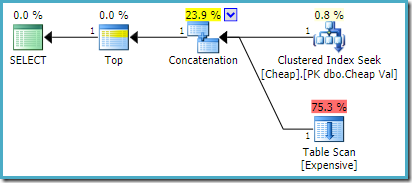
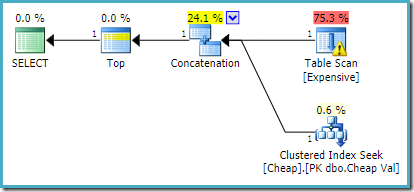
PÅ SQL Server 2012, 2014 og 2016 ingen etter optimalisering omorganisering skjer:
Hvis vi vil ha mer enn en rad returnert, for eksempel ved hjelp av TOP (2), Vil Ønsket omskrivning ikke bli brukt på sql server 2008 R2 selv om en FAST 1 hint brukes også. I den situasjonen må vi ty til triks som å bruke TOPmed en variabel og en OPTIMIZE FOR hint:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed SELECT TOP (@TopRows) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UAOPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint
den faktiske utførelsesplanen på SQL Server 2008 R2 er:
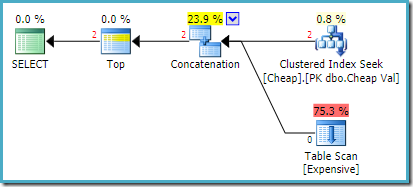
begge radene som returneres kommer fra den omordnede søkeinngangen, Og Tabellskanningen utføres ikke i det hele tatt. Plan Explorer viser rad teller i rødt fordi estimatet var for en rad (på grunn av hint) mens to rader ble støtt på kjøretid.
Uten UNION ALLE
dette problemet er heller ikke begrenset til spørsmål skrevet eksplisitt med UNION ALL. Andre konstruksjoner som EXISTS og OR kan også resultere i at optimalisereren introduserer en sammenkoblingsoperatør, som kan lide av mangel på input-omorganisering. Det var et nylig spørsmål Om Databaseadministratorer Stack Exchange med akkurat dette problemet. Endre spørringen fra at spørsmålet å bruke vårt eksempel tabeller:
– >
SELECT CASE WHEN EXISTS ( SELECT 1 FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 ) OR EXISTS ( SELECT 1 FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 ) THEN 1 ELSE 0 END;
gjennomføringsplan på SQL Server 2016 har haugen bord på den første innspill:
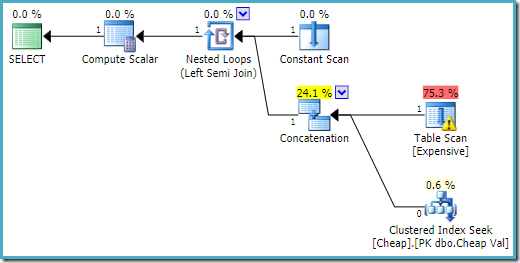
På SQL Server 2008 R2 rekkefølgen av inngangene er optimalisert for å reflektere enkelt rad mål i semi bli med:
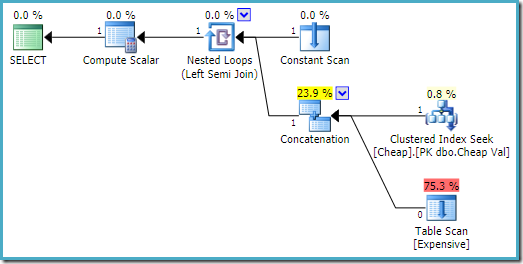
I en mer optimal plan, haugen scan er aldri utført.
Løsninger
i noen tilfeller vil det være tydelig for spørringsskriveren at en av sammenkoblingsinngangene alltid vil være billigere å kjøre enn de andre. Hvis det er sant, er det ganske gyldig å omskrive spørringen slik at de billigere sammenkoblingsinngangene vises først i skriftlig rekkefølge. Selvfølgelig betyr dette at spørringsforfatteren må være oppmerksom på denne optimaliseringsbegrensningen, og forberedt på å stole på udokumentert oppførsel.
et vanskeligere problem oppstår når kostnaden for sammenkoblingsinngangene varierer med omstendighetene, kanskje avhengig av parameterverdier. Bruk av OPTION (RECOMPILE) hjelper ikke PÅ SQL Server 2012 eller senere. Dette alternativet kan hjelpe PÅ SQL Server 2008 R2 eller tidligere, men bare hvis målkravet for enkelt rad også er oppfylt.
hvis det er bekymringer om å stole på observert atferd (sammenkoblingsinnganger for spørringsplan som samsvarer med tekstordren for spørringen), kan en planveiledning brukes til å tvinge planfiguren. Der ulike innsatsordrer er optimale for ulike forhold, kan flere planguider brukes, der forholdene kan kodes nøyaktig på forhånd. Dette er neppe ideelt skjønt.
Final Thoughts
SQL Server query optimizer inneholder faktisk en kostnadsbasert utforskningsregel, UNIAReorderInputs, som er i stand til å generere sammenkoblingsinngangsrekkefølge variasjoner og utforske alternativer under kostnadsbasert optimalisering (ikke som en single-shot post-optimalisering omskrivning).
denne regelen er for øyeblikket ikke aktivert for generell bruk. Så vidt jeg kan fortelle, aktiveres den bare når en planguide ellerUSE PLAN hint er til stede. Dette gjør at motoren kan fremtvinge en plan som ble generert for en spørring som er kvalifisert for inndatareordrer omskriving, selv når den gjeldende spørringen ikke kvalifiserer.min mening er at denne utforskningsregelen er bevisst begrenset til denne bruken, fordi spørringer som vil ha nytte av sammenkoblingsinngangsreordre som en del av kostnadsbasert optimalisering, anses ikke tilstrekkelig vanlig, eller kanskje fordi det er en bekymring for at den ekstra innsatsen ikke vil lønne seg. Min egen oppfatning er At Sammenkoblingsoperatørens inndataregistrering alltid skal utforskes når et radmål er i kraft.
det er også en skam at (mer begrenset) post-optimalisering omskrive ikke er effektiv I SQL Server 2012 eller senere. Dette kan ha vært på grunn av en subtil feil, men jeg kunne ikke finne noe om dette i dokumentasjonen, kunnskapsbasen eller På Connect. Jeg har lagt til et Nytt Connect-element her.
Oppdatering 9. August 2017: dette er nå løst under sporingsflagg 4199 FOR SQL Server-2014 og 2016, se KB 4023419:
LØS: Spørring MED UNION ALLE og en rad mål kan kjøre tregere I SQL Server 2014 eller senere versjoner når DET er sammenlignet MED SQL Server 2008 R2
Leave a Reply