SQL COUNT()with GROUP by
last update on February26 2020 08:07:42(UTC/GMT+8時間)
COUNT()WITH GROUP by
COUNT()関数をGROUP BYとともに使用することは、さまざまなグループ化の下でデータを特性化するのに便利です。 (列上の)同じ値の組み合わせは、個々のグループとして扱われます。
例:
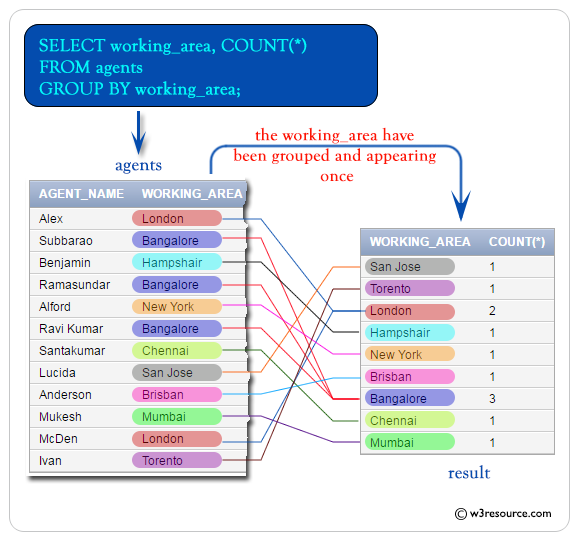
次の条件で’agents’テーブルから’working_area’のデータとこの’working_area’のエージェント数を取得するには-
1. ‘working_area’は一意に来る必要があります、
次のSQLステートメントを使用することができます。
SELECT working_area, COUNT(*) FROM agents GROUP BY working_area;サンプルテーブル:エージェント
出力
WORKING_AREA COUNT(*)----------------------------------- ----------San Jose 1Torento 1London 2Hampshair 1New York 1Brisban 1Bangalore 3Chennai 1Mumbai 1
絵のプレゼンテーション:
sql count()with group by and order by
このページでは、sql count()関数とともにgroup byとorder byの使用法について説明します。GROUP BYは、1つ以上の列の値によって集計行に結果セットを作成します。 特定の列のそれぞれの同じ値は、個々のグループとして扱われます。ORDER BY句の有用性は、列の値を昇順または降順に配置すること、列の型が数値または文字であることが何であれ、です。 Selectステートメントの列リスト内の列のシリアル番号を使用して、昇順または降順に配置する必要がある列を示すことができます。
キーワードやメンションASCEが指定されていない場合、デフォルトの順序は昇順です。 DESCは降順に設定するために言及されています。
例:
サンプルテーブル: エージェント
次の条件で’agent’テーブルから’working_area’のデータとこの’working_area’のエージェント数を取得するには-
1. ‘working_area’は一意に来る必要があります
2。 各グループのカウントは昇順で来る必要があります,
次のSQLステートメントを使用することができます:
SELECT working_area, COUNT(*) FROM agents GROUP BY working_area ORDER BY 2 ;出力:
WORKING_AREA COUNT(*)----------------------------------- ----------San Jose 1Torento 1New York 1Chennai 1Hampshair 1Mumbai 1Brisban 1London 2Bangalore 3
SQL COUNT()group by and order by in descending
‘working_area’のデータとこの’working_area’のエージェント数を取得するには以下の条件を持つ’agents’テーブルから-
1. ‘working_area’は一意に来る必要があります
2。 各グループのカウントは降順で来る必要があります、
次のSQL文を使用することができます。
SELECT working_area, COUNT(*) FROM agents GROUP BY working_area ORDER BY 2 DESC;出力:
WORKING_AREA COUNT(*)----------------------------------- ----------Bangalore 3London 2Hampshair 1Mumbai 1Brisban 1Chennai 1Torento 1San Jose 1New York 1
前:Distinctを持つカウント
次:
Leave a Reply