Explainer:L1vs.L2vs.L3Cache
安価なラップトップから100万ドルのサーバーまで、あらゆるコンピュータで見つかったすべてのCPUには、cacheと呼ばれるものがあります。 そうでない可能性が高い、それはあまりにも、それのいくつかのレベルを所有しています。それは重要でなければならない、そうでなければなぜそこにあるのでしょうか?
それは重要でなければならないのですか? しかし、キャッシュは何をし、なぜさまざまなレベルのものが必要なのでしょうか? 12-way set associativeは一体何を意味しているのでしょうか?
キャッシュとは正確には何ですか?TL;DR:小さいですが、CPUのロジックユニットのすぐ隣にある非常に高速なメモリです。
もちろんキャッシュについてはもっと学ぶことができます。..
想像上の魔法のストレージシステムから始めましょう:それは無限に高速で、一度に無限の数のデータトランザクションを処理でき、常にデータを安全 これに遠隔的にも何も存在しないということはありませんが、そうすれば、プロセッサの設計ははるかに簡単になります。
Cpuは、加算、乗算などのための論理ユニットを持つ必要があります。 そして、データ転送を処理するシステム。 これは、私たちの理論的なストレージシステムが必要なすべての番号を即座に送受信できるためです; 論理ユニットのいずれも、データトランザクションを待機することはありません。しかし、我々はすべて知っているように、任意の魔法のストレージ技術はありません。
代わりに、我々はハードまたはソリッドステートドライブを持っており、これらの中でも最高のものでさえ、典型的なCPUに必要なすべてのデータ転送をリモートで処理することさえできません。
データストレージの偉大なT’Phon
現代のCpuは信じられないほど高速である理由は、二つの64ビット整数値を一緒に追加するた00000000025秒またはナノ秒の四分の一。
一方、回転するハードドライブは、内部のディスク上のデータを見つけるためだけに数千ナノ秒かかり、それを転送することはおろか、ソリッドステート
このようなドライブは明らかにプロセッサに組み込むことができないので、両者の間に物理的な分離があることを意味します。 これにより、データの移動に時間が追加され、事態がさらに悪化します。

データストレージの偉大なA’Tuin、悲しいことに
私たちが必要とするのは、プロセッサとメインストレージの間に座っている別のデータ ドライブよりも高速で、大量のデータ転送を同時に処理できるようにし、プロセッサにはるかに近いものにする必要があります。
まあ、私たちはすでにそのようなことを持っていて、それはRAMと呼ばれ、すべてのコンピュータシステムにはこの目的のためのものがあります。この種のストレージのほとんどはDRAM(dynamic random access memory)であり、どのドライブよりもはるかに高速にデータを渡すことができます。しかし、DRAMは非常に高速ですが、それほど多くのデータを保存することはできません。
Dramの数少ないメーカーの一つであるMicron製の最大のDDR4メモリチップの中には、32Gbitsまたは4GBのデータを保持しているものがあり、最大のハードドライブは4,000倍以上のデータを保持しているものもある。
データネットワークの速度は向上しましたが、限られた量のDRAMにどのようなデータを保持し、CPUに対応できるようにするためには、ハードウェアとソフ
少なくともDRAMはチップパッケージ(組み込みDRAMとして知られている)になるように製造することができます。 しかし、CPUはかなり小さいので、それほど固執することはできません。

Xbox360のグラフィックスプロセッサの左側に10MBのDRAMがあります。 ソース:CPU Grave Yard
DRAMの大部分は、マザーボードに接続されたプロセッサのすぐ隣に位置しており、コンピュータシステムでは常にCPUに最も近いコンポーネントです。 そして、まだ、それはまだ十分に高速ではありません。..DRAMはまだデータを見つけるのに約100ナノ秒かかりますが、少なくとも毎秒数十億ビットを転送することができます。
プロセッサのユニットとDRAMの間を移動するには、別の段階のメモリが必要になるようです。左のステージに入ります:SRAM(static random access memory)。 DRAMが電荷の形でデータを格納するために微視的なコンデンサを使用する場合、SRAMは同じことを行うためにトランジスタを使用し、これらはプロセッサ内のもちろん、SRAMには欠点がありますが、もう一度、それはスペースに関するものです。同じサイズの4GB DDR4チップでは、100MB未満のSRAMが得られます。 しかし、それはCPUを作成するのと同じプロセスによって作られているので、SRAMは、できるだけロジックユニットの近くに、右のプロセッサ内部に構築す同じサイズの4GB DDR4チップでは、100MB未満のSRAMが得られます。
追加のステージごとに、データの移動速度を、保存できる量のコストに引き上げました。 私たちはより多くのセクションを追加し続けることができ、それぞれが速くても小さくな
そして、私たちは、キャッシュが何であるかのより技術的な定義に到着します:それはSRAMの複数のブロックであり、すべてがプロセッサ内にあります。 それに満足していますか? 良い-それはここからより多くの複雑になるだろうので!
キャッシュ: マルチレベルの駐車場
説明したように、プロセッサ内の論理ユニットのデータ要求に追いつくことができる魔法のストレージシステムがない 最新のCpuおよびグラフィックスプロセッサには、内部的に階層に編成された多数のSRAMブロックが含まれています。

上の画像では、CPUは黒の破線 Alu(算術論理ユニット)は左端にあります; これらは、チップが行う数学を処理し、プロセッサに電力を供給する構造です。 技術的にはキャッシュされていませんが、Aluに最も近いメモリレベルはレジスタです(レジスタファイルにグループ化されています)。値自体は、何かに関するデータの一部、特定の命令のコード、または他のデータのメモリアドレスである可能性があります。
これらの各数値は、64ビット整数
デスクトップCPUのレジスタファイルは非常に小さいです-例えば、IntelのCore i9-9900Kでは、各コアに二つのバンクがあり、整数用のものは180個の64ビット 他のレジスタファイルは、ベクトル(数値の小さな配列)のために、168の256ビットエントリを持っています。 したがって、各コアの合計レジスタファイルは7kB未満です。 これと比較して、Nvidia GeForce RTX2080Tiのストリーミングマルチプロセッサ(GPUのCPUコアに相当)のレジスタファイルのサイズは256kBです。
レジスタはキャッシュと同じようにSRAMですが、それらは提供するAluと同じくらい高速で、単一のクロックサイクルでデータを出入りさせます。 しかし、それらは非常に多くのデータ(その1つだけ)を保持するように設計されていないため、近くには常に大きなメモリブロックがいくつかあります。/p>
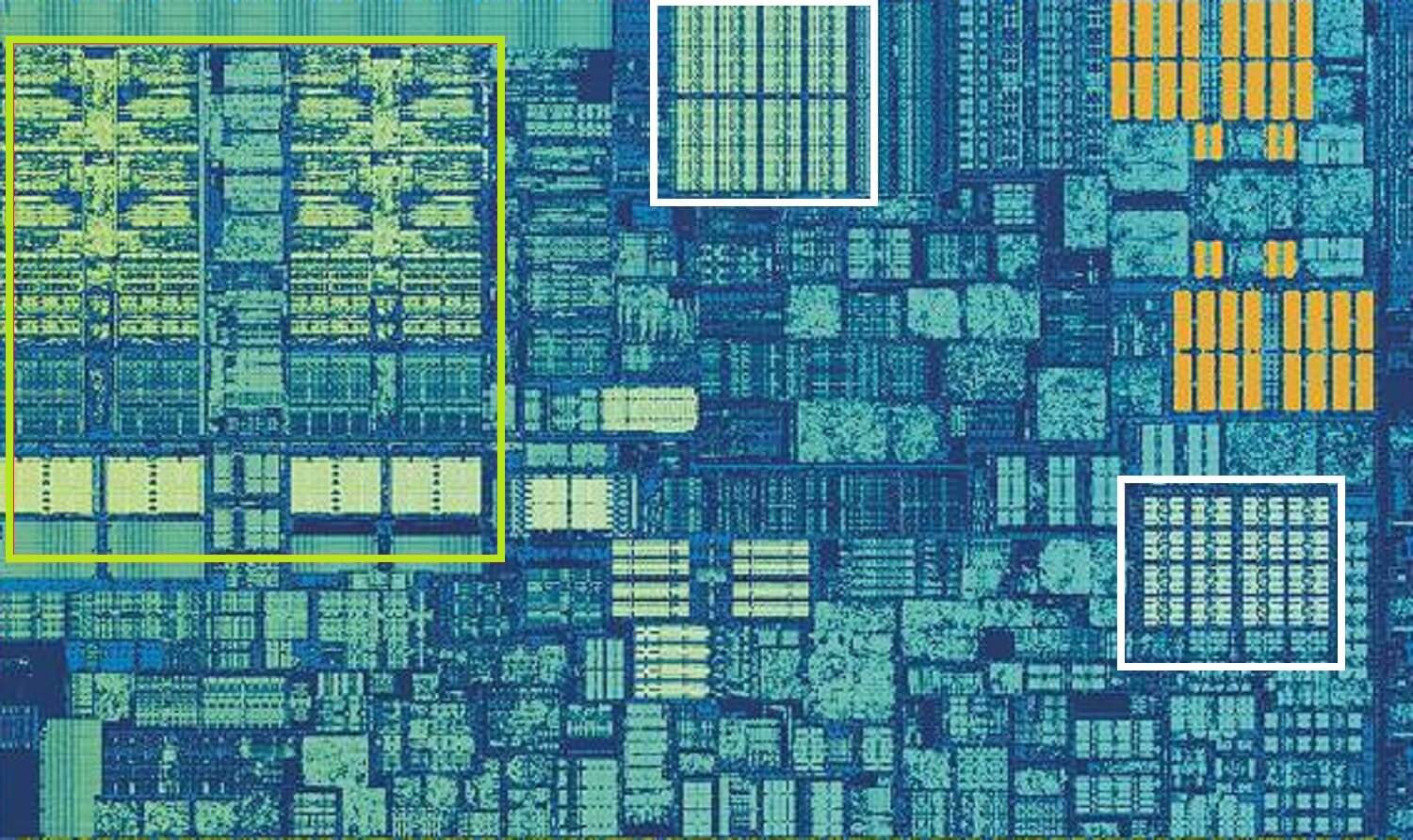
インテルSkylake CPU、シングルコアのショットでズームイン。 ソース:Wikichip
上記の画像は、IntelのSkylakeデスクトッププロセッサの設計からシングルコアのズームインショットです。
Aluとレジスタファイルは左端に表示され、緑色で強調表示されます。 画像の上部中央には、白で、レベル1のデータキャッシュがあります。 これは多くの情報、わずか32kBを保持していませんが、レジスタのように、それはロジックユニットに非常に近く、それらと同じ速度で実行されます。
他の白い四角形は、レベル1命令キャッシュを示し、サイズも32kBです。 その名前が示すように、これはAluが実行するために、より小さな、いわゆるマイクロ操作(通常はμ opsとラベルされている)に分割する準備ができて様々なコ それらのためのキャッシュもあり、L1キャッシュよりも小さく(1,500回の操作しか保持しない)、レベル0としてクラス化することができます。
なぜこれらのSRAMブロックが非常に小さいのか疑問に思うかもしれません。 データキャッシュと命令キャッシュは、メインロジックユニットとほぼ同じ量のスペースをチップ内で占有するため、それらを大きくするとダイの全体しかし、数kBしか保持していない主な理由は、メモリ容量が大きくなるにつれてデータの検索と取得に必要な時間が長くなることです。
L1キャッシュは本当に迅速である必要があるので、サイズと速度の間で妥協に達する必要があります-せいぜい、このキャッシュからデータを取得し、使
SkylakeのL2キャッシュ:256kBのSRAMの良さ
しかし、これがプロセッサ内の唯一のキャッシュであれば、そのパフォーマンスは突然の壁にぶつか これが、それらすべてがコアに組み込まれた別のレベルのメモリ、レベル2キャッシュを持っている理由です。 これは、命令とデータを保持する一般的なストレージブロックです。それは常にレベル1よりもかなり大きいです:AMD Zen2プロセッサは512kBまでパックするので、低レベルのキャッシュは十分に供給され続けることがで ただし、この余分なサイズにはコストがかかり、レベル1と比較して、このキャッシュからデータを検索して転送するのに約2倍の時間がかかります。
元のIntel Pentiumの時代に戻って、レベル2キャッシュは、小さなプラグイン回路基板(RAM DIMMのような)上に、またはメインマザーボードに組み込まれた別のチップ 最終的にはCPUパッケージ自体に機能し、最終的にはPENTIUM IIIやAMD K6-IIIプロセッサなどのCPUダイに統合されました。
この開発はすぐに他の下位レベルをサポートするためにそこに、キャッシュの別のレベルが続き、それが原因でマルチコアチップの上昇に約来

Intel Kaby Lakeチップ。 ソース:Wikichip
この画像は、Intel Kaby Lakeチップの、左中央に4つのコアを示しています(統合されたGPUは、右側にダイのほぼ半分を占めています)。 各コアには、レベル1と2のキャッシュ(白と黄色のハイライト)の独自の”プライベート”セットがありますが、SRAMブロックの第三のセットも付属しています。
レベル3キャッシュは、単一のコアの周りに直接あるにもかかわらず、完全に他の人と共有されています-それぞれが自由に別のL3キャッシュの それははるかに大きい(2と32MBの間)が、特にコアがある距離のキャッシュブロック内のデータを使用する必要がある場合は、30サイクル以上の平均
以下では、AMDのZen2アーキテクチャのシングルコアを見ることができます: 32kBレベル1のデータと命令キャッシュは白で、512KBレベル2は黄色で、4MBの巨大なL3キャッシュのブロックは赤である。
AMD Zen2CPU、シングルコアのショットをズームイン。

ソース:Fritzchensフリッツ
ちょっと待ってください。 どのように32kBは512kBよりも多くの物理スペースを取ることができますか? レベル1が保持するデータが非常に少ない場合、L2またはL3キャッシュよりも比例的に大きいのはなぜですか?
単なる数字よりも
キャッシュは、ロジックユニットへのデータ転送を高速化し、頻繁に使用される命令とデータのコピーを近くに保持することに キャッシュに格納されている情報は、データ自体と、システムメモリ/ストレージ内の最初の場所の場所の2つの部分に分割されます-このアドレスはキャッ
CPUがメモリとの間でデータを読み書きする操作を実行すると、レベル1キャッシュ内のタグをチェックすることから開始します。 必要なものが存在する場合(キャッシュヒット)、そのデータにはほぼすぐにアクセスできます。 キャッシュミスは、必要なタグが最も低いキャッシュレベルにない場合に発生します。
そのため、L1キャッシュに新しいタグが作成され、残りのプロセッサアーキテクチャが引き継がれ、他のキャッシュレベル(必要に応じてメインストレージド しかし、この新しいタグのためにL1キャッシュにスペースを入れるには、常に他の何かをL2に起動する必要があります。
これにより、ほぼ一定のデータのシャッフルが行われ、すべてがほんの一握りのクロックサイクルで達成されます。 これを達成する唯一の方法は、データの管理を処理するためにSRAMの周りに複雑な構造を持つことです。 別の言い方をすれば: CPUコアが1つのALUだけで構成されている場合、L1キャッシュははるかに簡単になりますが、それらの数十があるため(その多くは2つの命令のスP>
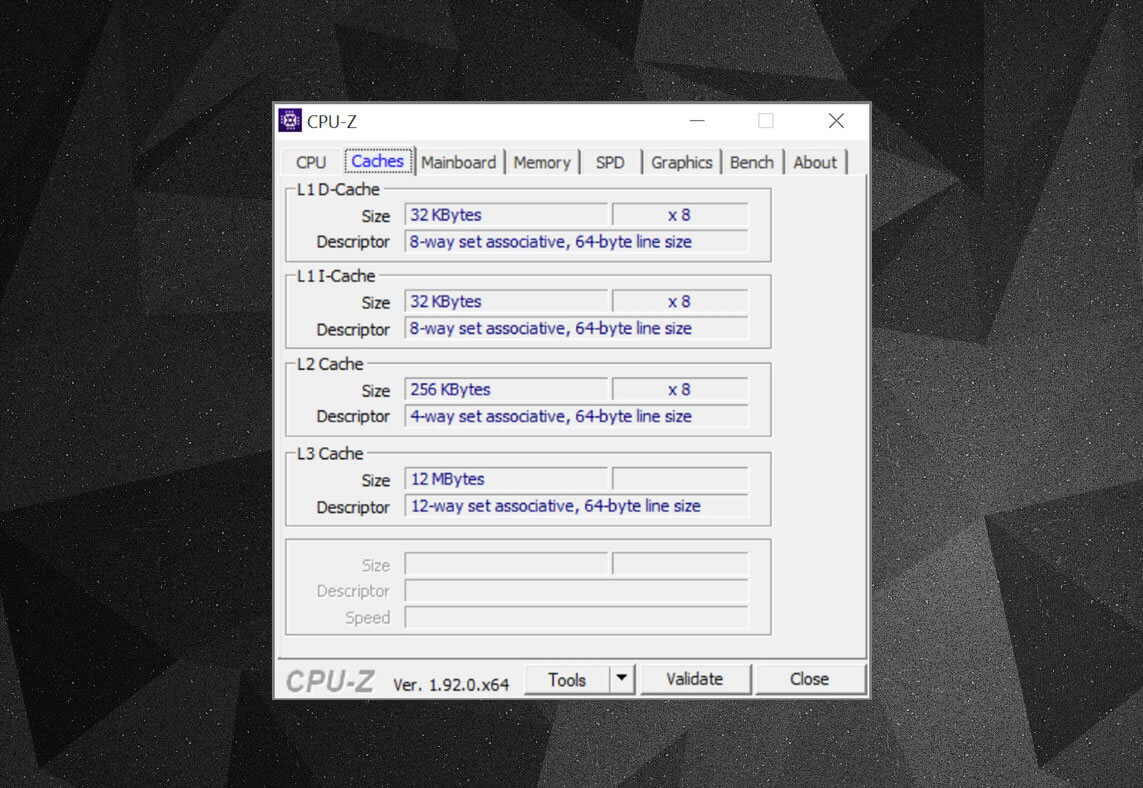
CPU-Zなどの無料のプログラムを使用して、自分のコンピュータに電力を供給するプロセッサのキャッシュ情報を確認できます。 しかし、その情報のすべてはどういう意味ですか? これは、システムメモリからのデータのブロックがキャッシュにどのようにコピーされるかによって強制されるルールに関するものです。
上記のキャッシュ情報は、Intel Core i7-9700Kのためのものであり、そのレベル1キャッシュはそれぞれ64個の小さなブロックに分割され、セットと呼ばれ、これらのそれぞれはさらにキャッシュライン(64バイトのサイズ)に分割されている。 Set associativeとは、システムメモリからのデータのブロックが、どこにでもマップできるのではなく、ある特定のセットのキャッシュラインにマップされるこ
8ウェイの部分は、1つのブロックがセット内の8つのキャッシュラインに関連付けることができることを示しています。 結合性のレベルが高いほど(つまり、より多くの”方法”)、CPUがデータを探しに行くときにキャッシュヒットを得る可能性が高くなり、キャッシュミスによ 欠点は、データのブロックに対して処理するキャッシュラインが多くなるため、複雑さが増し、消費電力が増加し、パフォーマンスが低下する可能性があ

L1+L2包括的なキャッシュ、L3犠牲者キャッシュ、書き込みバックポリシー、さらにはECC。 ソース: Fritzchens Fritz
キャッシュの複雑さに対するもう一つの側面は、さまざまなレベルでデータがどのように保持されるかを中心に展開します。 ルールは、包含ポリシーと呼ばれるものに設定されています。 たとえば、Intel Coreプロセッサには完全に包括的なL1+L3キャッシュがあります。 これは、たとえばレベル1の同じデータがレベル3のデータでもあることを意味します。 これは貴重なキャッシュスペースを無駄にしているように見えるかもしれませんが、利点は、プロセッサがミスを取得した場合、下位レベルのタグを検
同じプロセッサでは、L2キャッシュは非包括的であり、そこに格納されているデータは他のレベルにコピーされません。 これによりスペースが節約されますが、チップのメモリシステムはl3(常にはるかに大きい)を検索して欠落したタグを見つける必要があります。 被害者キャッシュはこれに似ていますが、下位レベルから押し出される情報を格納するために使用されます-たとえば、AMDのZen2プロセッサは、L2からのデータを格納するL3被害者キャッシュを使用しています。
データがキャッシュやメインシステムメモリに書き込まれるときなど、キャッシュには他のポリシーがあります。 これは、データがキャッシュレベルに書き込まれると、システムメモリがそのコピーで更新されるまでに遅延があることを意味します。 ほとんどの場合、この一時停止は、データがキャッシュに残っている限り実行されます-一度起動しただけで、RAMは情報を取得します。

NvidiaのGA100グラフィックスプロセッサは、合計20MBのL1と40MBのL2キャッシュを搭載しています
プロセッサ設計者のために、キャッシュの量、タイプ、およびポリシーを選択することは、複雑さの増加と必要なダイスペースに対するプロセッサ能力の向上に対する欲求のバランスをとることです。 チップがマンハッタンの大きさになることなく(そして同じ種類の電力を消費することなく)20MB、1000ウェイの完全連想レベル1キャッシュを持つことが可能であれば、私たちはすべてそのようなチップをスポーツするコンピュータを持っているでしょう!
今日のCpuのキャッシュの最低レベルは、過去十年間でそれほど変更されていません。 しかし、レベル3キャッシュのサイズは増加し続けています。 10年前、999ドルのIntel i7-980Xを所有するのに十分な運が良ければ、12MBを手に入れることができました。
キャッシュ、一言で言えば:技術の絶対に必要な、絶対に素晴らしい作品。 CpuやGpuの他のキャッシュタイプ(translation lookup buffersやtexture cachesなど)については見ていませんが、ここで説明したように、すべてが単純な構造とレベルのパターンに従っているため、それほど複雑には聞こえません。
マザーボードにL2キャッシュを持っていたコンピュータを所有していましたか? どのようにそれらのスロットベースのPentium IIとCeleron Cpu(例えば300a)は、daughterboardに入って来ましたか? あなたはL3を共有していたあなたの最初のCPUを覚えていますか? 私たちはコメント欄で知らせてください。
ショッピングのショートカット:
- AMD Ryzen9 3900X on Amazon
- AMD Ryzen9 3950X on Amazon
- Intel Core i9-10900K On Amazon
- AMD Ryzen7 3700X On Amazon
- Intel Core i7-10700K On Amazon
- AMD Ryzen5 3600On Amazon
- Intel Core i5-amazonで10600k
読み続けます。 TechSpot
- Wi-Fi6の説明者は説明しました:次世代のWi-Fi
- テンソルコアとは何ですか?
- チップビニングとは何ですか?
Leave a Reply