UNION ALL Optimization
La concaténation de deux ensembles de données ou plus est le plus souvent exprimée en T-SQL en utilisant la clause UNION ALL. Étant donné que l’optimiseur SQL Server peut souvent réorganiser des éléments tels que les jointures et les agrégats pour améliorer les performances, il est tout à fait raisonnable de s’attendre à ce que SQL Server envisage également de réorganiser les entrées de concaténation, là où cela fournirait un avantage. Par exemple, l’optimiseur pourrait considérer les avantages de la réécriture de A UNION ALL B en tant que B UNION ALL A.
En fait, l’optimiseur SQL Server ne le fait pas. Plus précisément, il y avait un support limité pour la réorganisation des entrées de concaténation dans les versions de SQL Server jusqu’à 2008 R2, mais cela a été supprimé dans SQL Server 2012 et n’a pas refait surface depuis.
SQL Server 2008 R2
Intuitivement, l’ordre des entrées de concaténation n’a d’importance que s’il existe un objectif de ligne. Par défaut, SQL Server optimise les plans d’exécution sur la base que toutes les lignes éligibles seront renvoyées au client. Lorsqu’un objectif de ligne est en vigueur, l’optimiseur essaie de trouver un plan d’exécution qui produira rapidement les premières lignes.
Les objectifs de ligne peuvent être définis de plusieurs manières, par exemple en utilisant TOP, un indice de requête FAST n, ou en utilisant EXISTS (qui, de par sa nature, doit trouver au plus une ligne). Lorsqu’il n’y a pas d’objectif de ligne (c’est-à-dire que le client a besoin de toutes les lignes), peu importe généralement dans quel ordre les entrées de concaténation sont lues: Chaque entrée sera entièrement traitée dans tous les cas.
La prise en charge limitée dans les versions jusqu’à SQL Server 2008 R2 s’applique lorsqu’il y a un objectif d’exactement une ligne. Dans cette circonstance spécifique, SQL Server réorganisera les entrées de concaténation sur la base du coût attendu.
Cela n’est pas fait lors d’une optimisation basée sur les coûts (comme on pouvait s’y attendre), mais plutôt comme une réécriture post-optimisation de dernière minute de la sortie normale de l’optimiseur. Cette disposition présente l’avantage de ne pas augmenter l’espace de recherche de plan basé sur les coûts (potentiellement une alternative pour chaque réorganisation possible), tout en produisant un plan optimisé pour retourner rapidement la première ligne.
Exemples
Les exemples suivants utilisent deux tables de contenu identique : Un million de lignes d’entiers de un à un million. Une table est un tas sans index non groupés ; l’autre a un index groupé unique:
CREATE TABLE dbo.Expensive( Val bigint NOT NULL); CREATE TABLE dbo.Cheap( Val bigint NOT NULL, CONSTRAINT UNIQUE CLUSTERED (Val));GOINSERT dbo.Cheap WITH (TABLOCKX) (Val)SELECT TOP (1000000) Val = ROW_NUMBER() OVER (ORDER BY SV1.number)FROM master.dbo.spt_values AS SV1CROSS JOIN master.dbo.spt_values AS SV2ORDER BY ValOPTION (MAXDOP 1);GOINSERT dbo.Expensive WITH (TABLOCKX) (Val)SELECT C.ValFROM dbo.Cheap AS COPTION (MAXDOP 1);
Aucun objectif de ligne
La requête suivante recherche les mêmes lignes dans chaque table et renvoie la concaténation des deux set :
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005;
Le plan d’exécution produit par l’optimiseur de requête est:
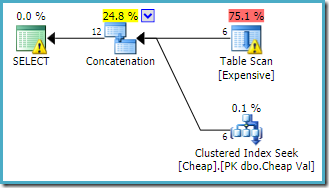
L’avertissement sur l’opérateur racine SELECT nous alerte sur l’index manquant évident sur la table de tas. L’avertissement sur l’opérateur d’analyse de table est ajouté par l’explorateur de plans Sentry One. Il attire notre attention sur le coût des E / S du prédicat résiduel caché dans l’analyse.
L’ordre des entrées à la concaténation n’a pas d’importance ici, car nous n’avons pas fixé d’objectif de ligne. Les deux entrées seront entièrement lues pour renvoyer toutes les lignes de résultat. D’intérêt (bien que cela ne soit pas garanti) notez que l’ordre des entrées suit l’ordre textuel de la requête d’origine. Notez également que l’ordre des lignes de résultat final n’est pas non plus spécifié, car nous n’avons pas utilisé de clause ORDER BY de niveau supérieur. Nous supposerons que l’ordre délibéré et final est sans conséquence sur la tâche à accomplir.
Si nous inversons l’ordre écrit des tables dans la requête comme ceci:
SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 UNION ALL SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005;
Le plan d’exécution suit le changement, accédant d’abord à la table en cluster (encore une fois, ce n’est pas garanti) :
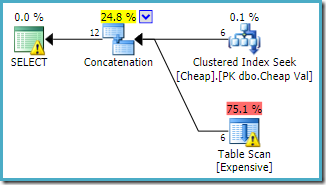
On peut s’attendre à ce que les deux requêtes aient les mêmes caractéristiques de performance, car elles effectuent les mêmes opérations, juste dans un ordre différent.
Avec un objectif de ligne
Clairement, l’absence d’indexation sur la table de tas rendra normalement la recherche de lignes spécifiques plus coûteuse, par rapport à la même opération sur la table en cluster. Si nous demandons à l’optimiseur un plan qui renvoie rapidement la première ligne, nous nous attendons à ce que SQL Server réordonne les entrées de concaténation afin que la table en cluster bon marché soit consultée en premier.
En utilisant la requête qui mentionne la table de tas en premier, et en utilisant un indice de requête RAPIDE 1 pour spécifier l’objectif de ligne:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005OPTION (FAST 1);
Le plan d’exécution estimé produit sur une instance de SQL Server 2008 R2 est :
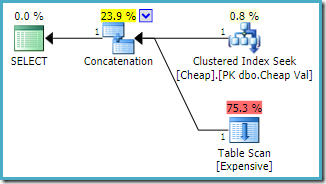
Notez que les entrées de concaténation ont été réorganisées pour réduire le coût estimé de retour de la première ligne. Notez également que l’index manquant et les avertissements d’E/S résiduels ont disparu. Aucun problème n’a de conséquence avec cette forme de plan lorsque l’objectif est de renvoyer une seule ligne le plus rapidement possible.
La même requête exécutée sur SQL Server 2016 (en utilisant l’un ou l’autre modèle d’estimation de cardinalité) est la suivante :
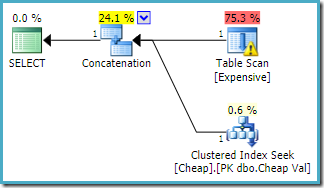
SQL Server 2016 n’a pas réorganisé les entrées de concaténation. L’avertissement d’E / S de l’explorateur de plans est revenu, mais malheureusement, l’optimiseur n’a pas produit d’avertissement d’index manquant cette fois (bien qu’il soit pertinent).
Réorganisation générale
Comme mentionné, la réécriture post-optimisation qui réordonne les entrées de concaténation n’est efficace que pour:
- SQL Server 2008 R2 et versions antérieures
- Un objectif de ligne d’exactement un
Si nous voulons vraiment qu’une seule ligne soit renvoyée, plutôt qu’un plan optimisé pour renvoyer rapidement la première ligne (mais qui retournera finalement toutes les lignes), nous pouvons utiliser une clause TOP avec une table dérivée ou une expression de table commune (CTE) :
SELECT TOP (1) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UA;
Sur SQL Server 2008 R2 ou une version antérieure, cela produit le plan d’entrée réorganisée optimal:
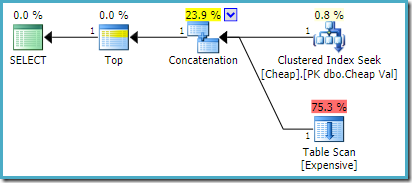
Sur SQL Server 2012, 2014 et 2016 aucune réorganisation post-optimisation ne se produit :
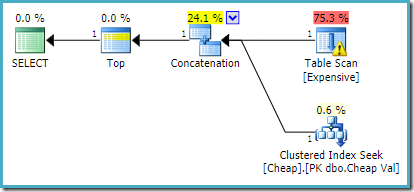
Si nous voulons que plus d’une ligne soit renvoyée, par exemple en utilisant TOP (2), la réécriture souhaitée ne sera pas appliquée sur SQL Server 2008 R2 même si un indice FAST 1 est également utilisé. Dans cette situation, nous devons recourir à des astuces comme utiliser TOP avec une variable et un indice OPTIMIZE FOR:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed SELECT TOP (@TopRows) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UAOPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint
L’indice de requête est suffisant pour définir un objectif de ligne de un, tandis que la valeur d’exécution de la variable garantit que le nombre de lignes souhaité (2) est renvoyé.
Le plan d’exécution réel sur SQL Server 2008 R2 est le suivant :
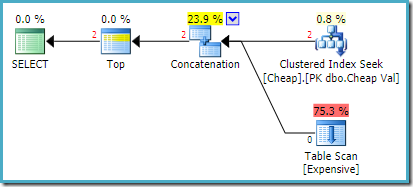
Les deux lignes renvoyées proviennent de l’entrée de recherche réorganisée, et l’analyse de la table n’est pas exécutée du tout. L’explorateur de plans affiche le nombre de lignes en rouge car l’estimation portait sur une ligne (en raison de l’indice) alors que deux lignes ont été rencontrées au moment de l’exécution.
Sans UNION ALL
Ce problème n’est pas non plus limité aux requêtes écrites explicitement avec UNION ALL. D’autres constructions telles que EXISTS et OR peuvent également entraîner l’introduction par l’optimiseur d’un opérateur de concaténation, qui peut souffrir du manque de réorganisation des entrées. Il y avait une question récente sur l’échange de piles des administrateurs de base de données avec exactement ce problème. Transformer la requête de cette question pour utiliser nos tables d’exemple :
SELECT CASE WHEN EXISTS ( SELECT 1 FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 ) OR EXISTS ( SELECT 1 FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 ) THEN 1 ELSE 0 END;
Le plan d’exécution sur SQL Server 2016 a la table de tas sur la première entrée : p>
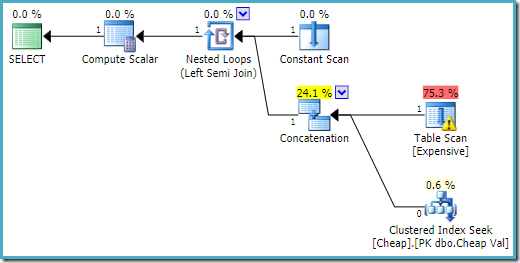
Sur SQL Server 2008 R2 l’ordre des entrées est optimisé pour refléter l’objectif d’une seule ligne de la semi-jointure :
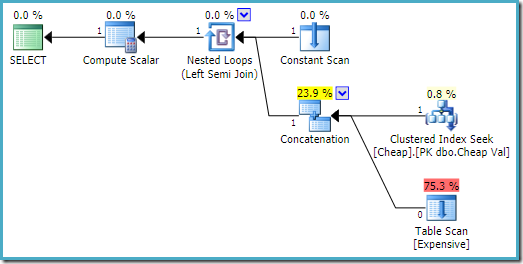
Dans le plan le plus optimal, l’analyse de tas n’est jamais exécuté.
Solutions de contournement
Dans certains cas, il sera évident pour l’auteur de la requête que l’une des entrées de concaténation sera toujours moins chère à exécuter que les autres. Si cela est vrai, il est tout à fait valable de réécrire la requête afin que les entrées de concaténation moins chères apparaissent en premier dans l’ordre écrit. Bien sûr, cela signifie que l’auteur de la requête doit être conscient de cette limitation de l’optimiseur et prêt à s’appuyer sur un comportement non documenté.
Un problème plus difficile se pose lorsque le coût des entrées de concaténation varie selon les circonstances, peut-être en fonction des valeurs des paramètres. L’utilisation de OPTION (RECOMPILE) n’aidera pas sur SQL Server 2012 ou une version ultérieure. Cette option peut aider sur SQL Server 2008 R2 ou une version antérieure, mais uniquement si l’exigence d’objectif à une seule ligne est également remplie.
S’il y a des préoccupations concernant le fait de s’appuyer sur le comportement observé (entrées de concaténation de plan de requête correspondant à l’ordre textuel de la requête), un guide de plan peut être utilisé pour forcer la forme du plan. Lorsque différents ordres d’entrée sont optimaux pour différentes circonstances, plusieurs guides de plan peuvent être utilisés, où les conditions peuvent être codées avec précision à l’avance. Ce n’est cependant pas idéal.
Réflexions finales
L’optimiseur de requêtes SQL Server contient en fait une règle d’exploration basée sur les coûts, UNIAReorderInputs, qui est capable de générer des variations d’ordre d’entrée de concaténation et d’explorer des alternatives lors de l’optimisation basée sur les coûts (pas comme une réécriture post-optimisation en un seul coup).
Cette règle n’est actuellement pas activée pour une utilisation générale. Pour autant que je sache, il n’est activé que lorsqu’un guide de plan ou un indice USE PLAN est présent. Cela permet au moteur de forcer avec succès un plan généré pour une requête qualifiée pour la réécriture de réorganisation des entrées, même lorsque la requête en cours n’est pas qualifiée.
Mon sentiment est que cette règle d’exploration est délibérément limitée à cette utilisation, car les requêtes qui bénéficieraient de la réorganisation des entrées de concaténation dans le cadre de l’optimisation basée sur les coûts sont considérées comme pas suffisamment courantes, ou peut-être parce que l’effort supplémentaire ne serait pas rentable. Mon propre point de vue est que la réorganisation des entrées de l’opérateur de concaténation doit toujours être explorée lorsqu’un objectif de ligne est en vigueur.
Il est également dommage que la réécriture post-optimisation (plus limitée) ne soit pas efficace dans SQL Server 2012 ou une version ultérieure. Cela aurait pu être dû à un bug subtil, mais je n’ai rien trouvé à ce sujet dans la documentation, la base de connaissances ou sur Connect. J’ai ajouté un nouvel élément de connexion ici.
Mise à jour du 9 août 2017 : Ceci est maintenant corrigé sous l’indicateur de trace 4199 pour SQL Server 2014 et 2016, voir KB 4023419 :
CORRECTION: La requête avec UNION ALL et un objectif de ligne peut s’exécuter plus lentement dans SQL Server 2014 ou les versions ultérieures lorsqu’elle est comparée à SQL Server 2008 R2
Leave a Reply