Explicateur: Cache L1 vs. L2 vs. L3
Chaque CPU trouvé dans n’importe quel ordinateur, d’un ordinateur portable bon marché à un serveur d’un million de dollars, aura quelque chose appelé cache. Plus probablement qu’autrement, il en possédera également plusieurs niveaux.
Cela doit être important, sinon pourquoi serait-il là? Mais qu’est-ce que cache fait, et pourquoi le besoin de différents niveaux de choses? Que signifie même associatif à 12 voies?
Qu’est-ce que le cache exactement ?
TL; DR: C’est une mémoire petite mais très rapide qui se trouve juste à côté des unités logiques du processeur.
Mais bien sûr, nous pouvons en apprendre beaucoup plus sur le cache…
Commençons par un système de stockage imaginaire et magique: il est infiniment rapide, peut gérer un nombre infini de transactions de données à la fois et garde toujours les données en sécurité. Ce n’est pas que rien, même à distance, existe, mais si c’était le cas, la conception du processeur serait beaucoup plus simple.
Les PROCESSEURS n’auraient besoin que d’unités logiques pour l’ajout, la multiplication, etc. et un système pour gérer les transferts de données. En effet, notre système de stockage théorique peut instantanément envoyer et recevoir tous les numéros requis; aucune des unités logiques ne serait maintenue en attente d’une transaction de données.
Mais, comme nous le savons tous, il n’y a pas de technologie de stockage magique. Au lieu de cela, nous avons des disques durs ou à semi-conducteurs, et même les meilleurs d’entre eux ne sont même pas capables de gérer à distance tous les transferts de données requis pour un processeur typique.
Le Grand T’Phon du stockage de données
La raison en est que les PROCESSEURS modernes sont incroyablement rapides – ils ne prennent qu’un cycle d’horloge pour ajouter deux valeurs entières de 64 bits ensemble, et pour un PROCESSEUR fonctionnant à 4 GHz, ce serait juste 0.00000000025 secondes ou un quart de nanoseconde.
Pendant ce temps, la rotation des disques durs prend des milliers de nanosecondes juste pour trouver des données sur les disques à l’intérieur, sans parler de les transférer, et les disques ssd prennent encore des dizaines ou des centaines de nanosecondes.
De tels disques ne peuvent évidemment pas être intégrés dans des processeurs, ce qui signifie qu’il y aura une séparation physique entre les deux. Cela ne fait qu’ajouter plus de temps au déplacement des données, ce qui aggrave encore les choses.

Le grand A’Tuin du stockage de données, malheureusement
Donc ce dont nous avons besoin, c’est d’un autre système de stockage de données, qui se trouve entre le processeur et le stockage principal. Il doit être plus rapide qu’un lecteur, être capable de gérer de nombreux transferts de données simultanément et être beaucoup plus proche du processeur.
Eh bien, nous avons déjà une telle chose, et cela s’appelle de la RAM, et chaque système informatique en a pour cela.
Presque tout ce type de stockage est une DRAM (mémoire vive dynamique) et il est capable de transmettre des données beaucoup plus rapidement que n’importe quel lecteur.
Cependant, bien que la DRAM soit super rapide, elle ne peut pas stocker autant de données.
Certaines des plus grandes puces de mémoire DDR4 fabriquées par Micron, l’un des rares fabricants de DRAM, contiennent 32 Go ou 4 Go de données; les plus grands disques durs en contiennent 4 000 fois plus.
Ainsi, bien que nous ayons amélioré la vitesse de notre réseau de données, des systèmes supplémentaires – matériels et logiciels – seront nécessaires pour déterminer quelles données doivent être conservées dans la quantité limitée de DRAM, prêtes pour le processeur.
Au moins une DRAM peut être fabriquée pour être dans le boîtier de la puce (appelée DRAM intégrée). Les processeurs sont cependant assez petits, vous ne pouvez donc pas y coller autant.

10 Mo de DRAM juste à gauche du processeur graphique de la Xbox 360. Source: CPU Grave Yard
La grande majorité de la DRAM est située juste à côté du processeur, branchée sur la carte mère, et c’est toujours le composant le plus proche du processeur, dans un système informatique. Et pourtant, ce n’est toujours pas assez rapide…
La DRAM prend encore environ 100 nanosecondes pour trouver des données, mais au moins elle peut transférer des milliards de bits chaque seconde. On dirait que nous aurons besoin d’une autre étape de mémoire, pour passer entre les unités du processeur et la DRAM.
Entrez l’étape à gauche : SRAM (mémoire vive statique). Là où la DRAM utilise des condensateurs microscopiques pour stocker des données sous forme de charge électrique, la SRAM utilise des transistors pour faire la même chose et ceux-ci peuvent fonctionner presque aussi vite que les unités logiques d’un processeur (environ 10 fois plus vite que la DRAM).
Il y a bien sûr un inconvénient à SRAM et encore une fois, il s’agit d’espace.
La mémoire à base de transistors prend beaucoup plus de place que la DRAM: pour une puce DDR4 de 4 Go de même taille, vous obtiendrez moins de 100 Mo de SRAM. Mais comme il est fait par le même processus que la création d’un processeur, SRAM peut être construit directement à l’intérieur du processeur, aussi près que possible des unités logiques.
La mémoire à base de transistors prend beaucoup plus de place que la DRAM: pour une puce DDR4 de 4 Go de même taille, vous obtiendrez moins de 100 Mo de SRAM.
Avec chaque étape supplémentaire, nous avons augmenté la vitesse de déplacement des données, au coût de combien nous pouvons stocker. Nous pourrions continuer à ajouter plus de sections, chacune étant plus rapide mais plus petite.
Et nous arrivons donc à une définition plus technique de ce qu’est le cache: il s’agit de plusieurs blocs de SRAM, tous situés à l’intérieur du processeur; ils sont utilisés pour s’assurer que les unités logiques sont maintenues aussi occupées que possible, en envoyant et en stockant des données à des vitesses super rapides. Content de ça ? Tant mieux because parce que ça va devenir beaucoup plus compliqué à partir d’ici !
Cache: un parking à plusieurs niveaux
Comme nous l’avons discuté, le cache est nécessaire car il n’y a pas de système de stockage magique capable de répondre aux demandes de données des unités logiques d’un processeur. Les processeurs et processeurs graphiques modernes contiennent un certain nombre de blocs SRAM, qui sont organisés en interne dans une hiérarchie – une séquence de caches qui sont ordonnés comme suit :

Dans l’image ci-dessus, le processeur est représenté par le rectangle en pointillés noirs. Les ALU (unités logiques arithmétiques) sont à l’extrême gauche; ce sont les structures qui alimentent le processeur, gérant les calculs de la puce. Bien que ce ne soit techniquement pas un cache, le niveau de mémoire le plus proche des ALU sont les registres (ils sont regroupés dans un fichier de registre).
Chacun d’eux contient un seul nombre, tel qu’un entier de 64 bits; la valeur elle-même peut être une donnée sur quelque chose, un code pour une instruction spécifique ou l’adresse mémoire de certaines autres données.
Le fichier de registre dans un processeur de bureau est assez petit – par exemple, dans le Core i9-9900K d’Intel, il y en a deux banques dans chaque cœur, et celle pour les entiers ne contient que 180 registres 64 bits. L’autre fichier de registre, pour les vecteurs (petits tableaux de nombres), contient 168 entrées de 256 bits. Ainsi, le fichier de registre total pour chaque cœur est un peu inférieur à 7 Ko. En comparaison, le fichier de registre dans les multiprocesseurs de streaming (l’équivalent du processeur graphique du cœur d’un processeur) d’une Nvidia GeForce RTX 2080 Ti a une taille de 256 Ko.
Les registres sont des SRAM, tout comme le cache, mais ils sont aussi rapides que les ALU qu’ils servent, poussant les données dans et hors en un seul cycle d’horloge. Mais ils ne sont pas conçus pour contenir beaucoup de données (juste un seul morceau), c’est pourquoi il y a toujours des blocs de mémoire plus importants à proximité: c’est le cache de niveau 1.
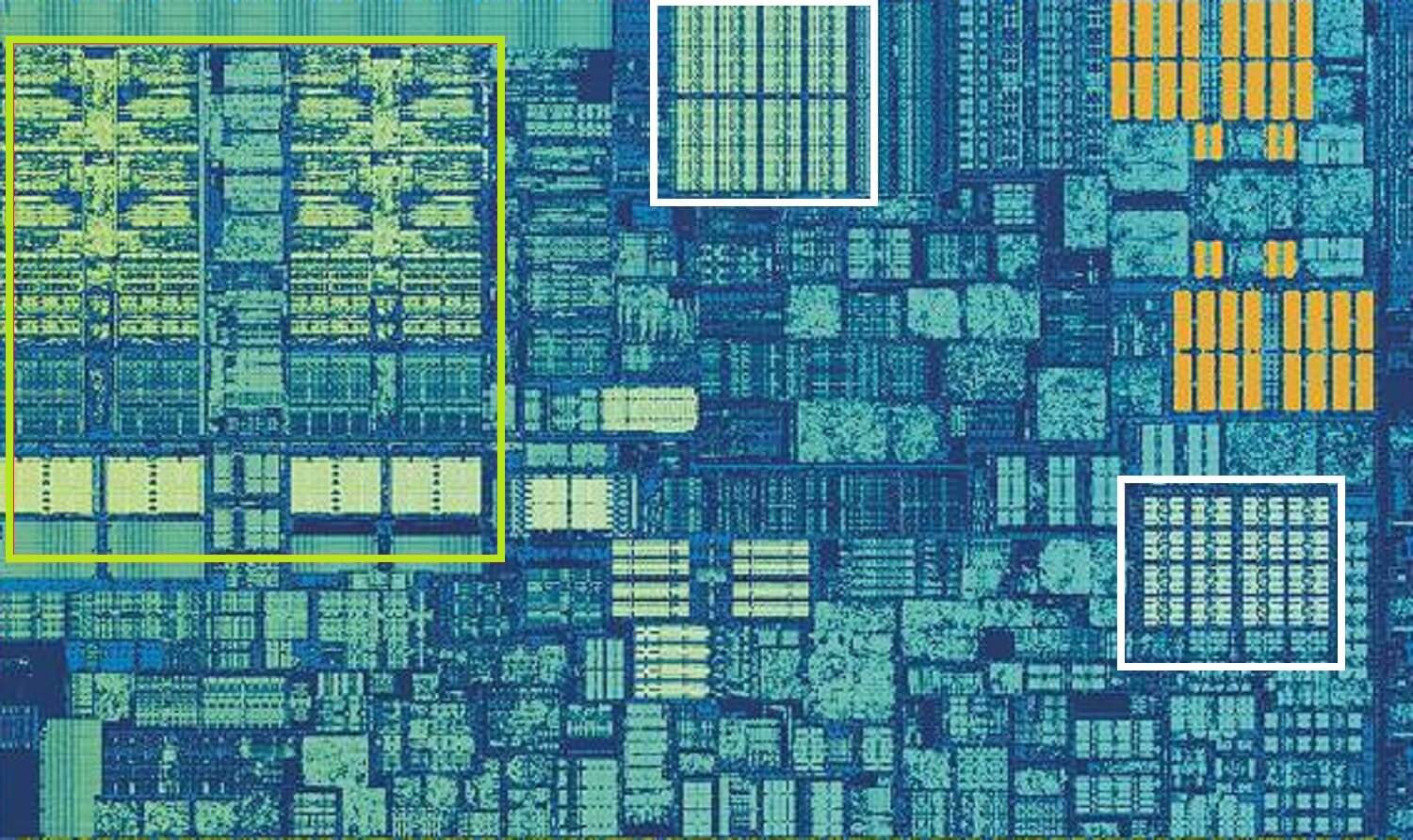
Processeur Intel Skylake, plan zoomé sur un seul cœur. Source:Wikichip
L’image ci-dessus est un plan zoomé d’un cœur unique issu de la conception du processeur de bureau Skylake d’Intel.
Les fichiers ALUs et les fichiers de registre sont visibles à l’extrême gauche, surlignés en vert. En haut au milieu de l’image, en blanc, se trouve le cache de données de niveau 1. Cela ne contient pas beaucoup d’informations, seulement 32 Ko, mais comme les registres, il est très proche des unités logiques et fonctionne à la même vitesse qu’eux.
L’autre rectangle blanc indique le cache d’instructions de niveau 1, également d’une taille de 32 Ko. Comme son nom l’indique, cela stocke diverses commandes prêtes à être divisées en petites opérations dites micro (généralement étiquetées µops), pour que les ALU puissent effectuer. Il y a aussi un cache pour eux, et vous pouvez le classer au niveau 0, car il est plus petit (ne contenant que 1 500 opérations) et plus proche que les caches L1.
Vous vous demandez peut-être pourquoi ces blocs de SRAM sont si petits ; pourquoi ne mesurent-ils pas un mégaoctet ? Ensemble, les caches de données et d’instructions occupent presque la même quantité d’espace dans la puce que les unités logiques principales, de sorte que les agrandir augmenterait la taille globale de la puce.
Mais la principale raison pour laquelle ils ne contiennent que quelques Ko, est que le temps nécessaire pour trouver et récupérer des données augmente à mesure que la capacité de mémoire augmente. Le cache L1 doit être très rapide, et donc un compromis doit être atteint, entre la taille et la vitesse — au mieux, il faut environ 5 cycles d’horloge (plus longs pour les valeurs à virgule flottante) pour extraire les données de ce cache, prêtes à l’emploi.
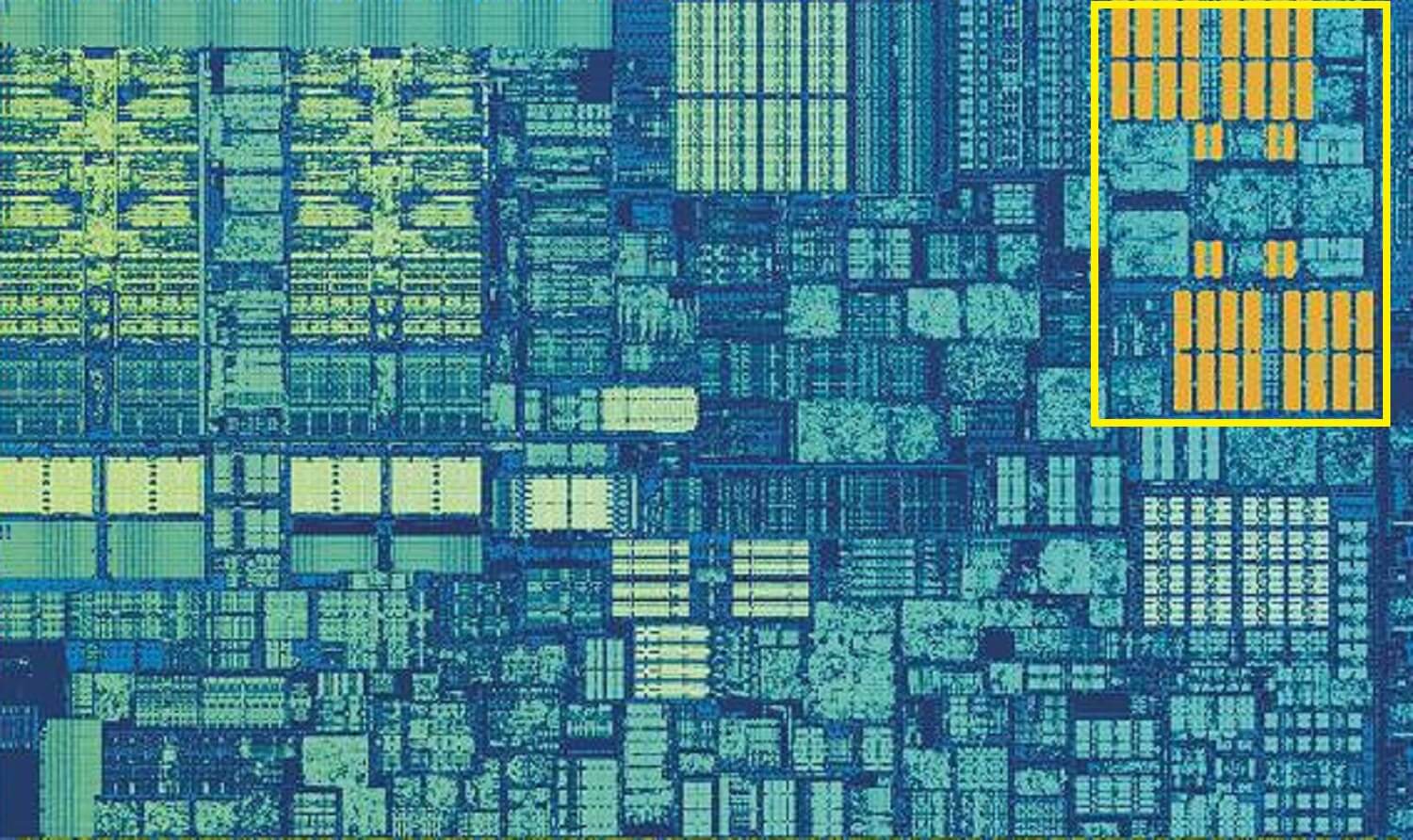
Cache L2 de Skylake: 256 Ko de qualité SRAM
Mais si c’était le seul cache à l’intérieur d’un processeur, ses performances heurteraient un mur soudain. C’est pourquoi ils ont tous un autre niveau de mémoire intégré dans les cœurs: le cache de niveau 2. Il s’agit d’un bloc de stockage général, contenant des instructions et des données.
Il est toujours un peu plus grand que le niveau 1 : les processeurs AMD Zen 2 contiennent jusqu’à 512 Ko, de sorte que les caches de niveau inférieur peuvent être bien fournis. Cette taille supplémentaire a cependant un coût, et il faut environ deux fois plus de temps pour trouver et transférer les données de ce cache, par rapport au niveau 1.
En remontant dans le temps, à l’époque de l’Intel Pentium d’origine, le cache de niveau 2 était une puce distincte, soit sur une petite carte de circuit imprimé enfichable (comme un DIMM RAM), soit intégrée à la carte mère principale. Il a finalement fait son chemin sur le package CPU lui-même, jusqu’à être finalement intégré dans la matrice CPU, dans les processeurs Pentium III et AMD K6-III.
Ce développement a rapidement été suivi d’un autre niveau de cache, là pour supporter les autres niveaux inférieurs, et cela est dû à l’essor des puces multicœurs.

Puce Intel Kaby Lake. Source :Wikichip
Cette image, d’une puce Intel Kaby Lake, montre 4 cœurs au milieu à gauche (un GPU intégré occupe près de la moitié du dé, à droite). Chaque cœur possède son propre ensemble « privé » de caches de niveau 1 et 2 (reflets blancs et jaunes), mais ils sont également livrés avec un troisième ensemble de blocs SRAM.
Le cache de niveau 3, même s’il est directement autour d’un seul cœur, est entièrement partagé avec les autres – chacun peut accéder librement au contenu du cache L3 d’un autre. C’est beaucoup plus grand (entre 2 et 32 Mo) mais aussi beaucoup plus lent, avec une moyenne de plus de 30 cycles, surtout si un cœur doit utiliser des données qui se trouvent dans un bloc de cache à une certaine distance.
Ci-dessous, nous pouvons voir un seul cœur dans l’architecture Zen 2 d’AMD: les caches de données et d’instructions de niveau 1 de 32 Ko en blanc, les caches de niveau 2 de 512 Ko en jaune et un énorme bloc de cache L3 de 4 Mo en rouge.

PROCESSEUR AMD Zen 2, zoom avant sur un seul cœur. Source: Fritzchens Fritz
Attendez une seconde. Comment 32 Ko peuvent-ils prendre plus d’espace physique que 512 Ko? Si le niveau 1 contient si peu de données, pourquoi est-il proportionnellement tellement plus grand que le cache L2 ou L3?
Plus qu’un simple nombre
Le cache améliore les performances en accélérant le transfert de données vers les unités logiques et en conservant une copie des instructions et des données fréquemment utilisées à proximité. Les informations stockées dans le cache sont divisées en deux parties: les données elles-mêmes et l’emplacement où elles se trouvaient à l’origine dans la mémoire / stockage système this cette adresse est appelée balise de cache.
Lorsque le PROCESSEUR exécute une opération qui veut lire ou écrire des données depuis/vers la mémoire, il commence par vérifier les balises dans le cache de niveau 1. Si celui requis est présent (un accès au cache), ces données sont alors accessibles presque immédiatement. Un manque de cache se produit lorsque la balise requise n’est pas au niveau de cache le plus bas.
Ainsi, une nouvelle balise est créée dans le cache L1, et le reste de l’architecture du processeur prend le relais, parcourant les autres niveaux de cache (jusqu’au disque de stockage principal, si nécessaire) pour trouver les données de cette balise. Mais pour faire de la place dans le cache L1 pour cette nouvelle balise, quelque chose d’autre doit invariablement être démarré dans le L2.
Cela se traduit par un brassage quasi constant des données, le tout réalisé en seulement une poignée de cycles d’horloge. La seule façon d’y parvenir est d’avoir une structure complexe autour de la SRAM, pour gérer la gestion des données. Autrement dit: si un cœur de processeur ne comprenait qu’une seule ALU, le cache L1 serait beaucoup plus simple, mais comme il en existe des dizaines (dont beaucoup jongleront avec deux threads d’instructions), le cache nécessite plusieurs connexions pour tout garder en mouvement.
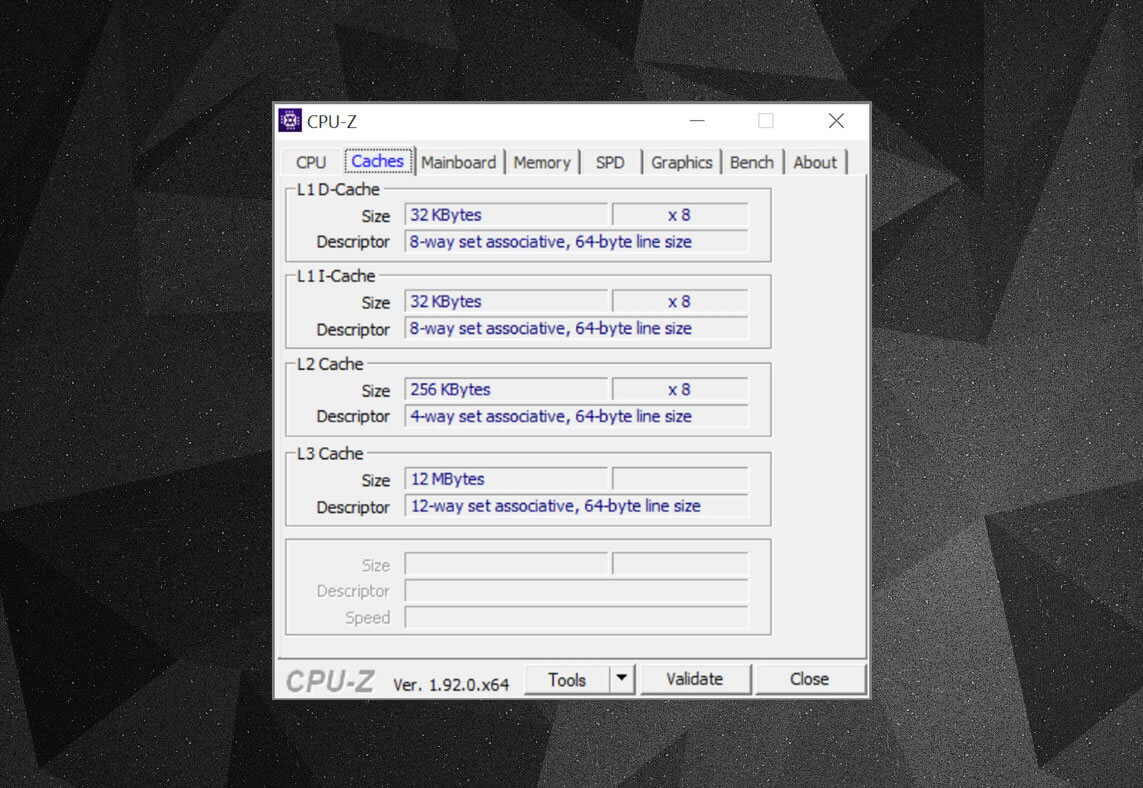
Vous pouvez utiliser des programmes gratuits, tels que CPU-Z, pour vérifier les informations de cache du processeur alimentant votre propre ordinateur. Mais que signifie toutes ces informations? Un élément important est l’ensemble d’étiquettes associatives – il s’agit des règles appliquées par la façon dont les blocs de données de la mémoire système sont copiés dans le cache.
Les informations de cache ci-dessus concernent un Intel Core i7-9700K. Ses caches de niveau 1 sont chacun divisés en 64 petits blocs, appelés ensembles, et chacun d’entre eux est divisé en lignes de cache (taille de 64 octets). Définir associatif signifie qu’un bloc de données de la mémoire système est mappé sur les lignes de cache dans un ensemble particulier, plutôt que d’être libre de mapper n’importe où.
La partie à 8 voies nous indique qu’un bloc peut être associé à 8 lignes de cache dans un ensemble. Plus le niveau d’associativité est élevé (c’est-à-dire plus de « moyens »), meilleures sont les chances d’obtenir un coup de cache lorsque le processeur part à la recherche de données et une réduction des pénalités causées par les manques de cache. Les inconvénients sont qu’il ajoute plus de complexité, augmente la consommation d’énergie et peut également diminuer les performances car il y a plus de lignes de cache à traiter pour un bloc de données.

Cache inclus L1 +L2, cache victime L3, polices de réécriture, même ECC. Source: Fritzchens Fritz
Un autre aspect de la complexité du cache tourne autour de la façon dont les données sont conservées à travers les différents niveaux. Les règles sont définies dans quelque chose appelé la politique d’inclusion. Par exemple, les processeurs Intel Core ont un cache L1 + L3 entièrement inclus. Cela signifie que les mêmes données au niveau 1, par exemple, peuvent également être au niveau 3. Cela peut sembler gaspiller un espace de cache précieux, mais l’avantage est que si le processeur obtient un échec, lors de la recherche d’une balise dans un niveau inférieur, il n’a pas besoin de parcourir le niveau supérieur pour le trouver.
Dans les mêmes processeurs, le cache L2 n’est pas inclus : les données qui y sont stockées ne sont copiées à aucun autre niveau. Cela économise de l’espace, mais le système de mémoire de la puce doit rechercher dans L3 (qui est toujours beaucoup plus grand) pour trouver une balise manquée. Les caches de victimes sont similaires à cela, mais ils sont habitués aux informations stockées qui sont expulsées d’un niveau inférieur – par exemple, les processeurs Zen 2 d’AMD utilisent le cache de victime L3 qui stocke uniquement les données de L2.
Il existe d’autres stratégies pour le cache, par exemple lorsque les données sont écrites dans le cache et la mémoire système principale. Celles-ci sont appelées stratégies d’écriture et la plupart des PROCESSEURS actuels utilisent des caches de réécriture; cela signifie que lorsque des données sont écrites dans un niveau de cache, il y a un délai avant que la mémoire système ne soit mise à jour avec une copie de celle-ci. Pour la plupart, cette pause s’exécute aussi longtemps que les données restent dans le cache – ce n’est qu’une fois qu’elles sont démarrées que la RAM obtient les informations.

Le processeur graphique GA100 de Nvidia, avec un total de 20 Mo de cache L1 et 40 Mo de cache L2
Pour les concepteurs de processeurs, le choix de la quantité, du type et de la politique de cache consiste à équilibrer le désir d’une plus grande capacité du processeur contre une complexité accrue et l’espace de matrice requis. S’il était possible d’avoir des caches de niveau 1 entièrement associatifs de 20 Mo à 1000 voies sans que les puces deviennent de la taille de Manhattan (et consomment le même type de puissance), alors nous aurions tous des ordinateurs dotés de telles puces!
Le niveau de caches le plus bas dans les PROCESSEURS actuels n’a pas beaucoup changé au cours de la dernière décennie. Cependant, la taille du cache de niveau 3 a continué de croître. Il y a dix ans, vous pouviez en obtenir 12 Mo, si vous aviez la chance de posséder un Intel i7-980X à 999 $. Pour la moitié de ce montant aujourd’hui, vous obtenez 64 Mo.
Cache, en un mot: des technologies absolument nécessaires et absolument géniales. Nous n’avons pas examiné d’autres types de caches dans les processeurs et les GPU (tels que les tampons de recherche de traduction ou les caches de texture), mais comme ils suivent tous une structure et un modèle de niveaux simples comme nous l’avons couvert ici, ils ne sembleront peut-être pas si compliqués.
Possédez-vous un ordinateur avec un cache L2 sur la carte mère? Que diriez-vous de ces processeurs Pentium II et Celeron basés sur des emplacements (par exemple 300a) qui sont entrés dans une carte fille? Pouvez-vous vous souvenir de votre premier processeur qui avait partagé L3? Faites-le nous savoir dans la section commentaires.
Raccourcis d’achat:
- AMD Ryzen 9 3900X sur Amazon
- AMD Ryzen 9 3950X sur Amazon
- INTEL Core i9-10900K sur Amazon
- AMD Ryzen 7 3700X sur Amazon
- Intel Core i7-10700K sur Amazon
- AMD Ryzen 5 3600 sur Amazon
- Intel Core i5 – 10600K sur Amazon
Continuez à lire. Les explicateurs de TechSpot
- Wi-Fi 6 Expliqués: La Prochaine génération de Wi-Fi
- Que sont les cœurs Tensoriels?
- Qu’Est-Ce Que Le Binning De Puces ?
Leave a Reply