UNION ALL Optimization
La concatenación de dos o más conjuntos de datos se expresa más comúnmente en T-SQL utilizando la cláusula UNION ALL. Dado que el optimizador de SQL Server a menudo puede reordenar cosas como uniones y agregados para mejorar el rendimiento, es bastante razonable esperar que SQL Server también considere reordenar las entradas de concatenación, donde esto proporcionaría una ventaja. Por ejemplo, el optimizador podría considerar los beneficios de reescribir A UNION ALL B como B UNION ALL A.
De hecho, el optimizador de SQL Server no hace esto. Más precisamente, hubo un soporte limitado para el reordenamiento de entradas de concatenación en versiones de SQL Server hasta 2008 R2, pero esto se eliminó en SQL Server 2012 y no ha vuelto a aparecer desde entonces.
SQL Server 2008 R2
Intuitivamente, el orden de las entradas de concatenación solo importa si hay un objetivo de fila. De forma predeterminada, SQL Server optimiza los planes de ejecución sobre la base de que todas las filas calificadas se devolverán al cliente. Cuando un objetivo de fila está en efecto, el optimizador intenta encontrar un plan de ejecución que produzca las primeras filas rápidamente.
Los objetivos de fila se pueden establecer de varias maneras, por ejemplo, usando TOP, una sugerencia de consulta FAST n, o usando EXISTS (que por su naturaleza necesita encontrar como máximo una fila). Cuando no hay un objetivo de fila (es decir, el cliente requiere todas las filas), generalmente no importa en qué orden se leen las entradas de concatenación: Cada entrada se procesará completamente en cualquier caso.
El soporte limitado en versiones hasta SQL Server 2008 R2 se aplica cuando hay un objetivo de exactamente una fila. En esta circunstancia específica, SQL Server reordenará las entradas de concatenación en función del costo esperado.
Esto no se hace durante la optimización basada en costos (como cabría esperar), sino como una reescritura posterior a la optimización de última hora de la salida normal del optimizador. Esta disposición tiene la ventaja de no aumentar el espacio de búsqueda del plan basado en costos (potencialmente una alternativa para cada posible reordenamiento), al tiempo que produce un plan optimizado para devolver la primera fila rápidamente.
Ejemplos
Los siguientes ejemplos utilizan dos tablas con contenidos idénticos: Un millón de filas de enteros de uno a un millón. Una tabla es un montón sin índices no agrupados; la otra tiene un índice agrupado único:
CREATE TABLE dbo.Expensive( Val bigint NOT NULL); CREATE TABLE dbo.Cheap( Val bigint NOT NULL, CONSTRAINT UNIQUE CLUSTERED (Val));GOINSERT dbo.Cheap WITH (TABLOCKX) (Val)SELECT TOP (1000000) Val = ROW_NUMBER() OVER (ORDER BY SV1.number)FROM master.dbo.spt_values AS SV1CROSS JOIN master.dbo.spt_values AS SV2ORDER BY ValOPTION (MAXDOP 1);GOINSERT dbo.Expensive WITH (TABLOCKX) (Val)SELECT C.ValFROM dbo.Cheap AS COPTION (MAXDOP 1);
No hay ninguna Fila Objetivo
La siguiente consulta busca las mismas filas en cada tabla, y devuelve la concatenación de los dos conjuntos:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005;
El plan de ejecución producido por el optimizador de consultas:
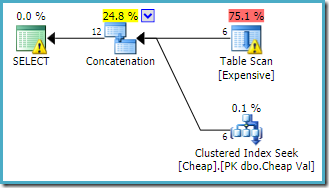
El operador de advertencia en la raíz SELECT nos avisa del obvio índice que falta en la tabla de montones. El explorador de planes Sentry One agrega la advertencia en el operador de exploración de tablas. Está llamando nuestra atención sobre el costo de E/S del predicado residual oculto dentro del escaneo.
El orden de las entradas a la Concatenación no importa aquí, porque no hemos establecido un objetivo de fila. Ambas entradas se leerán completamente para devolver todas las filas de resultados. De interés (aunque esto no está garantizado) observe que el orden de las entradas sigue el orden textual de la consulta original. Observe también que el orden de las filas de resultados finales tampoco se especifica, ya que no usamos una cláusula de nivel superior ORDER BY. Asumiremos que es deliberado y el orden final es intrascendente para la tarea en cuestión.
Si invertimos el orden escrita de las tablas en la consulta como:
SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 UNION ALL SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005;
El plan de ejecución sigue el cambio, accediendo primero a la tabla agrupada (de nuevo, esto no está garantizado):
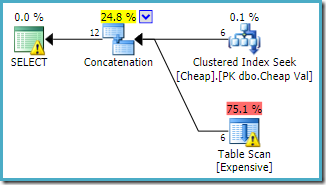
Se puede esperar que ambas consultas tengan las mismas características de rendimiento, ya que realizan las mismas operaciones, solo que en un orden diferente.
Con un objetivo de fila
Claramente, la falta de indexación en la tabla de montones normalmente hará que encontrar filas específicas sea más costoso, en comparación con la misma operación en la tabla agrupada. Si le pedimos al optimizador un plan que devuelva la primera fila rápidamente, esperaríamos que SQL Server reordenara las entradas de concatenación para que se consulte primero la tabla agrupada barata.
Usar la consulta que menciona primero la tabla de montones y usar una sugerencia de consulta RÁPIDA 1 para especificar el objetivo de fila:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005OPTION (FAST 1);
El plan de ejecución estimado producido en una instancia de SQL Server 2008 R2 es:
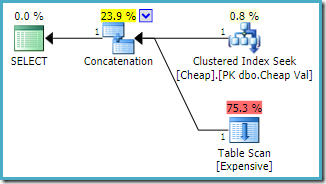
Observe que la concatenación de las entradas se han reorganizado para reducir el costo estimado de retorno de primera fila. Tenga en cuenta también que las advertencias de índice y de E/S residuales que faltan han desaparecido. Ninguno de los dos problemas tiene importancia con esta forma de plan cuando el objetivo es devolver una sola fila lo más rápido posible.
La misma consulta ejecutada en SQL Server 2016 (utilizando cualquiera de los modelos de estimación de cardinalidad) es:
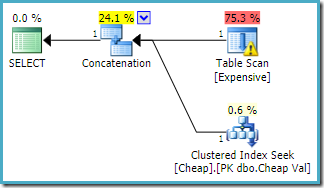
SQL Server 2016 no ha reordenado las entradas de concatenación. La advertencia de E/S del explorador de planes ha regresado, pero lamentablemente el optimizador no ha producido una advertencia de índice faltante esta vez (aunque es relevante).
Reordenamiento general
Como se mencionó, la reescritura posterior a la optimización que reordena las entradas de concatenación solo es efectiva para:
- SQL Server 2008 R2 y anterior
- Una fila objetivo de exactamente uno
Si realmente sólo quieren una fila devuelta, en lugar de un plan optimizado para volver a la primera fila rápidamente (pero que, en definitiva, devolver todas las filas), se puede usar un TOP cláusula con una tabla derivada o expresión de tabla común (CTE):
SELECT TOP (1) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UA;
En SQL Server 2008 R2 o anterior, esto produce la óptima a ordenar-entrada plan de:
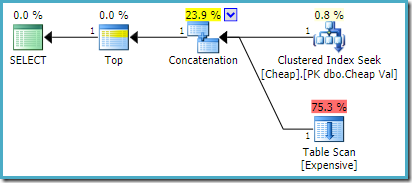
En SQL Server 2012, 2014 y 2016 no se produce ningún reordenamiento posterior a la optimización:
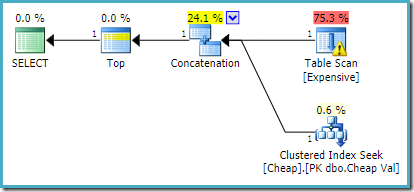
queremos que se devuelva más de una fila, por ejemplo, usando TOP (2), la reescritura deseada no se aplicará en SQL Server 2008 R2 incluso si también se usa una pista FAST 1. En esa situación, necesitamos recurrir a trucos como usar TOP con una variable y una pista OPTIMIZE FOR :
DECLARE @TopRows bigint = 2; -- Number of rows actually needed SELECT TOP (@TopRows) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UAOPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint
La sugerencia de consulta es suficiente para establecer una fila objetivo de uno, mientras que el valor de tiempo de ejecución de la variable asegura que el número de filas (2) se devuelve.
El plan de ejecución real en SQL Server 2008 R2 es:
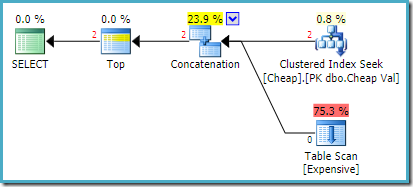
Ambas filas devueltas provienen de la entrada de búsqueda reordenada, y el análisis de tabla no se ejecuta en absoluto. El explorador de planos muestra los recuentos de filas en rojo porque la estimación era para una fila (debido a la sugerencia), mientras que se encontraron dos filas en tiempo de ejecución.
Sin UNION ALL
Este problema tampoco se limita a las consultas escritas explícitamente con UNION ALL. Otras construcciones como EXISTS y OR también pueden dar lugar a que el optimizador introduzca un operador de concatenación, que puede sufrir la falta de reordenación de la entrada. Hubo una pregunta reciente sobre los Administradores de bases de datos de Stack Exchange con exactamente este problema. La transformación de la consulta a partir de esa pregunta que utilizar nuestro tablas de ejemplo:
SELECT CASE WHEN EXISTS ( SELECT 1 FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 ) OR EXISTS ( SELECT 1 FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 ) THEN 1 ELSE 0 END;
El plan de ejecución en SQL Server 2016 tiene el montón de la mesa en la primera entrada:
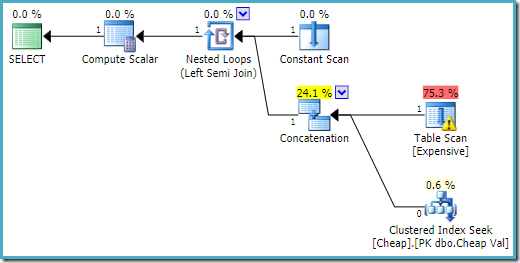
En SQL Server 2008 R2 el orden de las entradas está optimizado para reflejar la sola fila objetivo de la semi unirse:
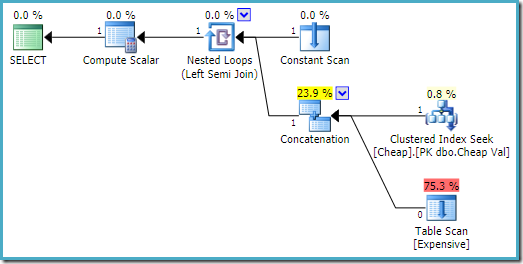
En el más óptimo plan, el montón de escaneo no se ejecuta nunca.
Soluciones alternativas
En algunos casos, será evidente para el escritor de consultas que una de las entradas de concatenación siempre será más barata de ejecutar que las otras. Si eso es cierto, es bastante válido reescribir la consulta para que las entradas de concatenación más baratas aparezcan primero en orden escrito. Por supuesto, esto significa que el escritor de consultas debe ser consciente de esta limitación del optimizador y estar preparado para confiar en el comportamiento indocumentado.
Un problema más difícil surge cuando el costo de las entradas de concatenación varía con las circunstancias, tal vez dependiendo de los valores de los parámetros. Usar OPTION (RECOMPILE) no ayudará en SQL Server 2012 o posterior. Esta opción puede ayudar en SQL Server 2008 R2 o versiones anteriores, pero solo si también se cumple el requisito de objetivo de fila única.
Si hay dudas acerca de confiar en el comportamiento observado (entradas de concatenación de plan de consulta que coinciden con el orden textual de la consulta), se puede usar una guía de plan para forzar la forma del plan. Cuando las diferentes órdenes de entrada son óptimas para diferentes circunstancias, se pueden usar varias guías de plan, donde las condiciones se pueden codificar con precisión por adelantado. Sin embargo, esto no es ideal.
Pensamientos finales
El optimizador de consultas de SQL Server de hecho contiene una regla de exploración basada en costos, UNIAReorderInputs, que es capaz de generar variaciones de orden de entrada de concatenación y explorar alternativas durante la optimización basada en costos (no como una reescritura posterior a la optimización de un solo disparo).
Esta regla no está habilitada actualmente para uso general. Por lo que puedo decir, solo se activa cuando una guía de plan o USE PLAN pista está presente. Esto permite al motor forzar con éxito un plan que se generó para una consulta que calificó para la reescritura de reordenamiento de entrada, incluso cuando la consulta actual no califica.
Mi opinión es que esta regla de exploración se limita deliberadamente a este uso, porque las consultas que se beneficiarían de la reordenación de entradas de concatenación como parte de la optimización basada en costos se consideran no lo suficientemente comunes, o quizás porque existe la preocupación de que el esfuerzo adicional no valdría la pena. Mi propia opinión es que el reordenamiento de entrada del operador de concatenación siempre debe explorarse cuando un objetivo de fila está en efecto.
También es una pena que la reescritura posterior a la optimización (más limitada) no sea efectiva en SQL Server 2012 o posterior. Esto podría haber sido debido a un error sutil, pero no pude encontrar nada sobre esto en la documentación, la base de conocimientos o en Connect. He agregado un nuevo elemento de conexión aquí.
Actualización del 9 de agosto de 2017: Ahora se soluciona bajo el indicador de seguimiento 4199 para SQL Server 2014 y 2016, consulte KB 4023419:
FIX: La consulta con UNION ALL y un objetivo de fila puede ejecutarse más lentamente en SQL Server 2014 o versiones posteriores cuando se compara con SQL Server 2008 R2
Leave a Reply