Explainer: L1 vs. L2 vs. L3 Cache
Jede einzelne CPU in jedem Computer, von einem billigen Laptop bis zu einem Millionen-Dollar-Server, wird etwas namens Cache haben. Höchstwahrscheinlich wird es auch mehrere Ebenen davon besitzen.
Es muss wichtig sein, warum sollte es sonst da sein? Aber was macht Cache und warum die Notwendigkeit verschiedener Ebenen des Materials? Was um alles in der Welt bedeutet 12-Wege-Set-Assoziativ überhaupt?
Was genau ist Cache?
TL; DR: Es ist ein kleiner, aber sehr schneller Speicher, der direkt neben den Logikeinheiten der CPU sitzt.
Aber natürlich können wir noch viel mehr über Cache lernen…Beginnen wir mit einem imaginären, magischen Speichersystem: Es ist unendlich schnell, kann unendlich viele Datentransaktionen gleichzeitig verarbeiten und hält Daten immer sicher. Nicht, dass irgendetwas auch nur entfernt davon existiert, aber wenn es so wäre, wäre das Prozessordesign viel einfacher.
CPUs müssten nur Logikeinheiten zum Addieren, Multiplizieren usw. haben. und ein System, um die Datenübertragung zu handhaben. Dies liegt daran, dass unser theoretisches Speichersystem sofort alle erforderlichen Nummern senden und empfangen kann; keine der Logikeinheiten würde auf eine Datentransaktion warten.
Aber wie wir alle wissen, gibt es keine magische Speichertechnologie. Stattdessen haben wir Festplatten oder Solid-State-Laufwerke, und selbst die besten davon sind nicht einmal im Entferntesten in der Lage, alle für eine typische CPU erforderlichen Datenübertragungen zu verarbeiten.
Das große Ding der Datenspeicherung
Der Grund dafür ist, dass moderne CPUs unglaublich schnell sind – sie brauchen nur einen Taktzyklus, um zwei 64-Bit-Integer-Werte zusammenzufügen, und für eine CPU mit 4 GHz wäre dies nur 0.00000000025 Sekunden oder eine Viertel Nanosekunde.
In der Zwischenzeit benötigen sich drehende Festplatten Tausende von Nanosekunden, um Daten auf den Discs im Inneren zu finden, geschweige denn zu übertragen, und Solid-State-Laufwerke benötigen immer noch Dutzende oder Hunderte von Nanosekunden.
Solche Laufwerke können offensichtlich nicht in Prozessoren eingebaut werden, was bedeutet, dass es eine physische Trennung zwischen den beiden gibt. Dies erhöht nur die Zeit für das Verschieben von Daten und macht die Dinge noch schlimmer.

Das große A’Tuin der Datenspeicherung, leider
Was wir also brauchen, ist ein weiteres Datenspeichersystem, das zwischen dem Prozessor und dem Hauptspeicher sitzt. Es muss schneller als ein Laufwerk sein, viele Datenübertragungen gleichzeitig verarbeiten können und viel näher am Prozessor sein.
Nun, wir haben bereits so etwas, und es heißt RAM, und jedes Computersystem hat einige für diesen Zweck.
Fast alle diese Arten von Speicher sind DRAM (Dynamic Random Access Memory) und können Daten viel schneller weitergeben als jedes Laufwerk.
DRAM ist zwar superschnell, kann aber nicht annähernd so viele Daten speichern.
Einige der größten DDR4-Speicherchips von Micron, einem der wenigen Hersteller von DRAM, halten 32 Gbits oder 4 GB Daten; die größten Festplatten halten 4.000 mal mehr als das.Obwohl wir die Geschwindigkeit unseres Datennetzwerks verbessert haben, werden zusätzliche Systeme – Hardware und Software – erforderlich sein, um herauszufinden, welche Daten in der begrenzten Menge an DRAM für die CPU bereitgehalten werden sollen.
Mindestens DRAM kann im Chippaket sein (bekannt als eingebettetes DRAM). CPUs sind jedoch ziemlich klein, sodass Sie nicht so viel hineinstecken können.

10 MB DRAM direkt links vom Grafikprozessor der Xbox 360. Quelle: CPU Grave Yard
Die überwiegende Mehrheit des DRAM befindet sich direkt neben dem Prozessor, der an das Motherboard angeschlossen ist, und ist in einem Computersystem immer die Komponente, die der CPU am nächsten liegt. Und doch ist es immer noch nicht schnell genug…
DRAM benötigt immer noch etwa 100 Nanosekunden, um Daten zu finden, aber zumindest kann es Milliarden von Bits pro Sekunde übertragen. Sieht so aus, als würden wir eine weitere Speicherstufe benötigen, um zwischen die Prozessoreinheiten und das DRAM zu gelangen.
Geben Sie Stufe links: SRAM (static Random Access Memory). Wo DRAM mikroskopische Kondensatoren verwendet, um Daten in Form von elektrischer Ladung zu speichern, verwendet SRAM Transistoren, um dasselbe zu tun, und diese können fast so schnell arbeiten wie die Logikeinheiten in einem Prozessor (ungefähr 10 mal schneller als DRAM).
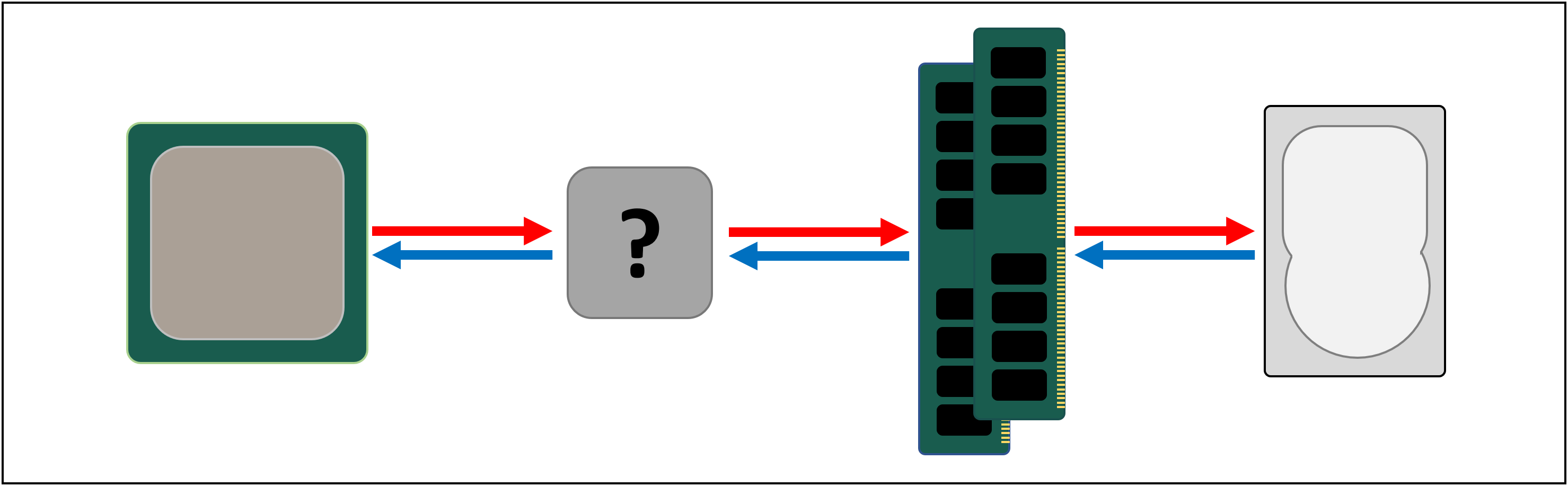
SRAM hat natürlich einen Nachteil, und wieder geht es um Platz.Transistor-basierter Speicher nimmt viel mehr Platz als DRAM: für die gleiche Größe 4 GB DDR4-Chip, würden Sie weniger als 100 MB im Wert von SRAM bekommen. Aber da es durch den gleichen Prozess wie das Erstellen einer CPU gemacht wird, kann SRAM direkt im Prozessor gebaut werden, so nah wie möglich an den Logikeinheiten.Transistor-basierter Speicher nimmt viel mehr Platz als DRAM: für die gleiche Größe 4 GB DDR4-Chip, würden Sie weniger als 100 MB im Wert von SRAM bekommen.
Mit jeder zusätzlichen Stufe haben wir die Geschwindigkeit des Verschiebens von Daten auf die Kosten für die Menge, die wir speichern können, erhöht. Wir könnten weitere Abschnitte hinzufügen, wobei jeder schneller, aber kleiner ist.Und so kommen wir zu einer technischeren Definition dessen, was Cache ist: Es sind mehrere Blöcke von SRAM, die sich alle im Prozessor befinden; Sie werden verwendet, um sicherzustellen, dass die Logikeinheiten so beschäftigt wie möglich gehalten werden, indem Daten mit superschnellen Geschwindigkeiten gesendet und gespeichert werden. Glücklich damit? Gut – weil es von nun an viel komplizierter wird!
Zwischenspeicher: ein mehrstufiger Parkplatz
Wie bereits erwähnt, wird ein Cache benötigt, da es kein magisches Speichersystem gibt, das mit den Datenanforderungen der Logikeinheiten in einem Prozessor Schritt halten kann. Moderne CPUs und Grafikprozessoren enthalten eine Reihe von SRAM-Blöcken, die intern in einer Hierarchie organisiert sind – eine Folge von Caches, die wie folgt geordnet sind:

Im obigen Bild wird die CPU durch das schwarz gestrichelte Rechteck dargestellt. Die ALUs (Arithmetic Logic Units) befinden sich ganz links; dies sind die Strukturen, die den Prozessor mit Strom versorgen und die Mathematik des Chips handhaben. Obwohl es technisch gesehen kein Cache ist, sind die Register die nächste Speicherebene zu den ALUs (sie sind in einer Registerdatei zusammengefasst).
Jeder dieser Werte enthält eine einzelne Zahl, z. B. eine 64-Bit-Ganzzahl; Der Wert selbst kann ein Datenelement über etwas, ein Code für eine bestimmte Anweisung oder die Speicheradresse einiger anderer Daten sein.
Die Registerdatei in einer Desktop-CPU ist ziemlich klein – zum Beispiel gibt es in Intels Core i9-9900K zwei Bänke in jedem Kern, und die für Ganzzahlen enthält nur 180 64-Bit-Register. Die andere Registerdatei für Vektoren (kleine Zahlenfelder) enthält 168 256-Bit-Einträge. Die gesamte Registerdatei für jeden Kern beträgt also etwas weniger als 7 kB. Im Vergleich dazu ist die Registerdatei in den Streaming-Multiprozessoren (das GPU-Äquivalent eines CPU-Kerns) einer Nvidia GeForce RTX 2080 Ti 256 kB groß.Register sind SRAM, genau wie Cache, aber sie sind genauso schnell wie die ALUs, die sie bedienen, und schieben Daten in einem einzigen Taktzyklus ein und aus. Aber sie sind nicht dafür ausgelegt, sehr viele Daten zu speichern (nur ein einziges Stück davon), weshalb sich immer einige größere Speicherblöcke in der Nähe befinden: Dies ist der Level-1-Cache.
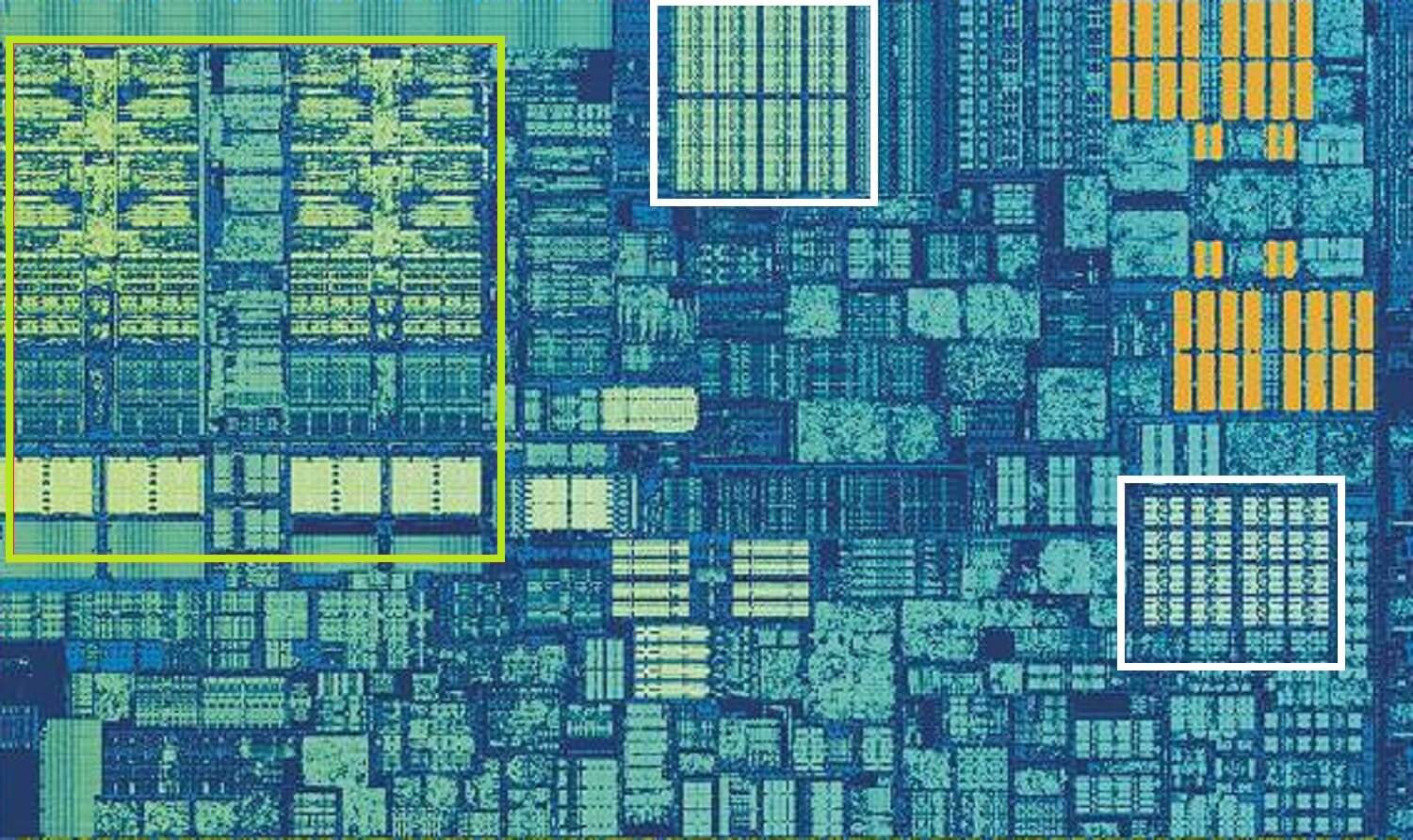
Intel Skylake CPU, vergrößerte Aufnahme eines einzelnen Kerns. Quelle: Wikichip
Das obige Bild ist eine vergrößerte Aufnahme eines einzelnen Kerns aus Intels Skylake-Desktop-Prozessor-Design.
Die ALUs und die Registerdateien sind ganz links grün hervorgehoben zu sehen. In der oberen Mitte des Bildes, in Weiß, befindet sich der Datencache der Ebene 1. Dies enthält nicht viele Informationen, nur 32 kB, aber wie Register ist es sehr nah an den Logikeinheiten und läuft mit der gleichen Geschwindigkeit wie sie.
Das andere weiße Rechteck zeigt den Befehlscache der Ebene 1 an, der ebenfalls 32 kB groß ist. Wie der Name schon sagt, speichert dieser verschiedene Befehle, die bereit sind, in kleinere, sogenannte Mikrooperationen (normalerweise als µops bezeichnet) aufgeteilt zu werden, damit die ALUs sie ausführen können. Es gibt auch einen Cache für sie, und Sie könnten ihn als Level 0 einstufen, da er kleiner (nur 1.500 Operationen) und näher als die L1-Caches ist.
Sie fragen sich vielleicht, warum diese Blöcke von SRAM so klein sind; Warum sind sie nicht ein Megabyte groß? Zusammen nehmen die Daten- und Befehls-Caches fast den gleichen Platz im Chip ein wie die Hauptlogikeinheiten, so dass ihre Vergrößerung die Gesamtgröße des Würfels erhöhen würde.
Aber der Hauptgrund, warum sie nur ein paar kB halten, ist, dass die Zeit, die benötigt wird, um Daten zu finden und abzurufen, zunimmt, wenn die Speicherkapazität größer wird. Der L1-Cache muss sehr schnell sein, und daher muss ein Kompromiss zwischen Größe und Geschwindigkeit erzielt werden – bestenfalls dauert es etwa 5 Taktzyklen (länger für Gleitkommawerte), um die Daten aus diesem Cache einsatzbereit zu machen.
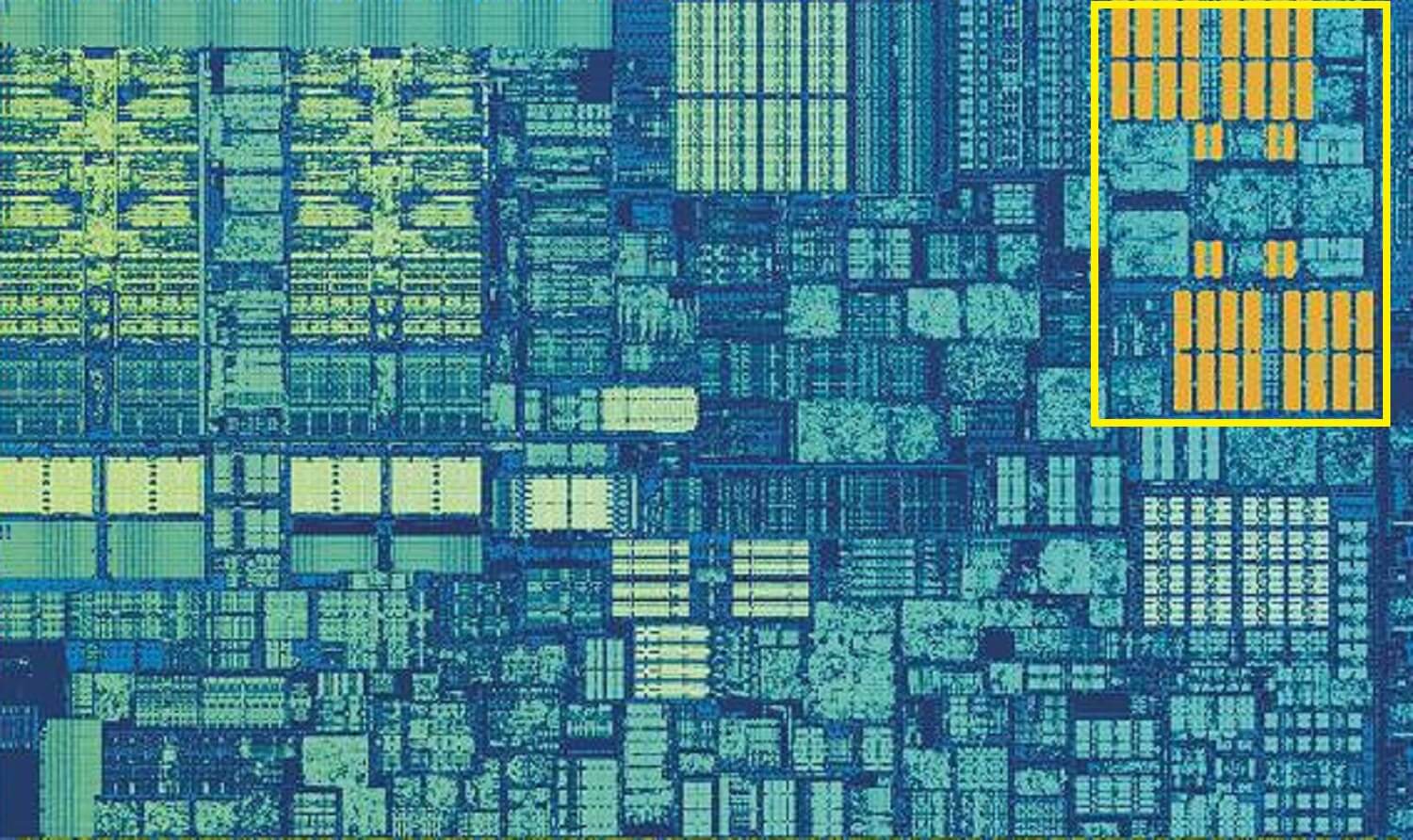
Skylakes L2-Cache: 256 kB SRAM-Güte
Aber wenn dies der einzige Cache in einem Prozessor wäre, würde seine Leistung plötzlich an eine Wand stoßen. Aus diesem Grund haben sie alle eine andere Speicherebene in den Kernen integriert: den Level-2-Cache. Dies ist ein allgemeiner Speicherblock, der Anweisungen und Daten festhält.
Es ist immer ein bisschen größer als Level 1: AMD Zen 2 Prozessoren packen bis zu 512 kB, so dass die unteren Level-Caches gut versorgt gehalten werden können. Diese zusätzliche Größe ist jedoch mit Kosten verbunden, und es dauert ungefähr doppelt so lange, um die Daten aus diesem Cache zu finden und zu übertragen, verglichen mit Level 1.
Zurück in die Zeit des ursprünglichen Intel Pentium war Level 2 Cache ein separater Chip, entweder auf einer kleinen Steckplatine (wie einem RAM-DIMM) oder in das Hauptplatine eingebaut. Es arbeitete sich schließlich in das CPU-Paket selbst ein, bis es schließlich in die CPU integriert wurde sterben, in den Pentium III- und AMD K6-III-Prozessoren.
Dieser Entwicklung folgte bald eine weitere Cache-Ebene, um die anderen unteren Ebenen zu unterstützen, und sie entstand aufgrund des Aufstiegs von Multicore-Chips.

Intel Kaby See chip. Quelle: Wikichip
Dieses Bild eines Intel Kaby Lake-Chips zeigt 4 Kerne in der linken Mitte (eine integrierte GPU nimmt rechts fast die Hälfte des Würfels ein). Jeder Kern hat seinen eigenen ‚privaten‘ Satz von Level 1 und 2 Caches (weiße und gelbe Highlights), aber sie kommen auch mit einem dritten Satz von SRAM-Blöcken.
Level-3-Cache, obwohl er sich direkt um einen einzelnen Kern befindet, wird vollständig mit den anderen geteilt – jeder kann frei auf den Inhalt des L3-Caches eines anderen zugreifen. Es ist viel größer (zwischen 2 und 32 MB), aber auch viel langsamer und beträgt durchschnittlich über 30 Zyklen, insbesondere wenn ein Kern Daten verwenden muss, die sich in einem Cache-Block in einiger Entfernung befinden.
Unten sehen wir einen einzelnen Kern in AMDs Zen 2-Architektur: die 32 kB Level 1 Daten- und Anweisungscaches in Weiß, die 512 KB Level 2 in Gelb und ein enormer 4 MB Block L3 Cache in Rot.

AMD Zen 2 CPU, vergrößerte Aufnahme eines einzelnen Kerns. Quelle: Fritzchens Fritz
Moment mal. Wie können 32 kB mehr physischen Speicherplatz beanspruchen als 512 kB? Wenn Level 1 so wenig Daten enthält, warum ist es proportional so viel größer als der L2- oder L3-Cache?
Mehr als nur eine Zahl
Der Cache steigert die Leistung, indem er die Datenübertragung zu den Logikeinheiten beschleunigt und eine Kopie häufig verwendeter Anweisungen und Daten in der Nähe hält. Die im Cache gespeicherten Informationen sind in zwei Teile unterteilt: die Daten selbst und den Ort, an dem sie sich ursprünglich im Systemspeicher / -speicher befanden – diese Adresse wird als Cache-Tag bezeichnet.
Wenn die CPU eine Operation ausführt, die Daten aus / in den Speicher lesen oder schreiben möchte, überprüft sie zunächst die Tags im Cache der Ebene 1. Wenn der erforderliche vorhanden ist (ein Cache-Treffer), kann auf diese Daten fast sofort zugegriffen werden. Ein Cache-Fehler tritt auf, wenn sich das erforderliche Tag nicht in der niedrigsten Cache-Ebene befindet.
Im L1-Cache wird also ein neues Tag erstellt, und der Rest der Prozessorarchitektur übernimmt die Jagd durch die anderen Cache-Ebenen (ggf. bis zum Hauptspeicherlaufwerk), um die Daten für dieses Tag zu finden. Aber um Platz im L1-Cache für dieses neue Tag zu schaffen, muss immer etwas anderes in den L2 gebootet werden.
Dies führt zu einem nahezu konstanten Mischen von Daten, die alle in nur wenigen Taktzyklen erreicht werden. Der einzige Weg, dies zu erreichen, besteht darin, eine komplexe Struktur um den SRAM herum zu haben, um die Verwaltung der Daten zu übernehmen. Setzen Sie einen anderen Weg: wenn ein CPU-Kern nur aus einer ALU bestehen würde, wäre der L1-Cache viel einfacher, aber da es Dutzende von ihnen gibt (von denen viele zwei Befehlsthreads jonglieren), erfordert der Cache mehrere Verbindungen, um alles in Bewegung zu halten.
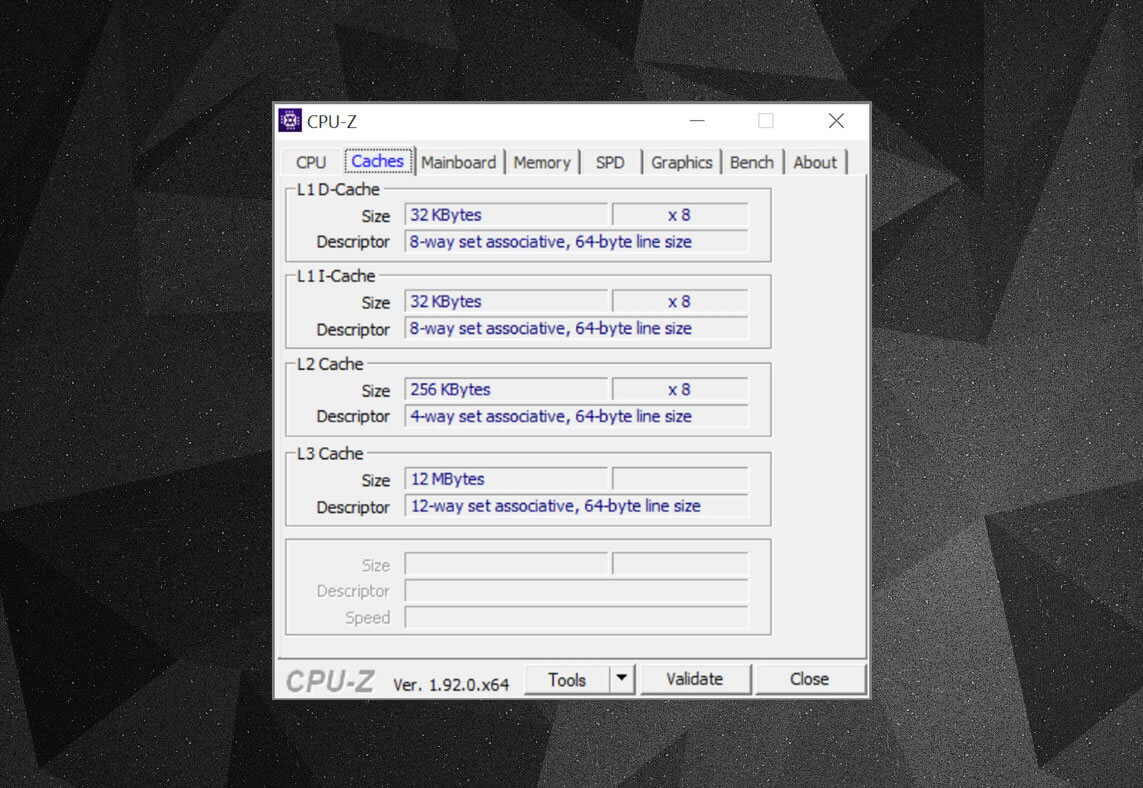
Sie können kostenlose Programme wie CPU-Z verwenden, um die Cache-Informationen für den Prozessor zu überprüfen, der Ihren eigenen Computer mit Strom versorgt. Aber was bedeuten all diese Informationen? Ein wichtiges Element ist das assoziative Label-Set – hier geht es um die Regeln, die durchgesetzt werden, wie Datenblöcke aus dem Systemspeicher in den Cache kopiert werden.
Die obigen Cache-Informationen beziehen sich auf einen Intel Core i7-9700K. Seine Level-1-Caches sind jeweils in 64 kleine Blöcke, sogenannte Sets, unterteilt, von denen jeder weiter in Cache-Zeilen (64 Byte groß) unterteilt ist. Set assoziativ bedeutet, dass ein Block von Daten aus dem Systemspeicher auf die Cache-Zeilen in einem bestimmten Satz abgebildet wird, anstatt frei zu sein, überall zuzuordnen.
Der 8-Wege-Teil sagt uns, dass ein Block 8 Cache-Zeilen in einem Satz zugeordnet werden kann. Je höher die Assoziativität (dh mehr ‚Wege‘), desto besser sind die Chancen, einen Cache-Treffer zu erhalten, wenn die CPU nach Daten sucht, und desto geringer sind die Strafen, die durch Cache-Fehler verursacht werden. Die Nachteile sind, dass es mehr Komplexität hinzufügt, den Stromverbrauch erhöht und auch die Leistung verringern kann, da mehr Cache-Zeilen für einen Datenblock verarbeitet werden müssen.

L1+L2 inklusive Cache, L3 Opfer-Cache, Rückschreibrichtlinien, sogar ECC. Quelle: Fritzchens Fritz
Ein weiterer Aspekt der Komplexität von Cache dreht sich darum, wie Daten über die verschiedenen Ebenen hinweg aufbewahrt werden. Die Regeln sind in der sogenannten Inklusionspolitik festgelegt. Beispielsweise verfügen Intel Core-Prozessoren über einen vollständig integrierten L1 + L3-Cache. Dies bedeutet, dass die gleichen Daten in Ebene 1 beispielsweise auch in Ebene 3 sein können. Dies mag so aussehen, als würde wertvoller Cache-Speicherplatz verschwendet, aber der Vorteil ist, dass der Prozessor bei der Suche nach einem Tag in einer niedrigeren Ebene nicht durch die höhere Ebene jagen muss, um ihn zu finden, wenn er einen Fehler erhält.
In denselben Prozessoren ist der L2-Cache nicht inklusive: Dort gespeicherte Daten werden nicht auf eine andere Ebene kopiert. Dies spart Platz, führt jedoch dazu, dass das Speichersystem des Chips L3 (das immer viel größer ist) durchsuchen muss, um ein fehlendes Tag zu finden. Opfer-Caches sind ähnlich, aber sie werden für gespeicherte Informationen verwendet, die aus einer niedrigeren Ebene verdrängt werden – zum Beispiel verwenden AMDs Zen 2-Prozessoren den L3-Opfer-Cache, der nur Daten von L2 speichert.
Es gibt andere Richtlinien für den Cache, z. B. wenn Daten in den Cache und den Hauptsystemspeicher geschrieben werden. Dies bedeutet, dass beim Schreiben von Daten in eine Cache-Ebene eine Verzögerung auftritt, bevor der Systemspeicher mit einer Kopie davon aktualisiert wird. In den meisten Fällen läuft diese Pause so lange, wie die Daten im Cache verbleiben – erst nach dem Booten erhält der RAM die Informationen.

Nvidias GA100-Grafikprozessor mit insgesamt 20 MB L1- und 40 MB L2-Cache
Bei der Auswahl der Menge, des Typs und der Cache-Richtlinie geht es für Prozessordesigner darum, den Wunsch nach größerer Prozessorkapazität gegen die erhöhte Komplexität und den erforderlichen Die-Platz auszugleichen. Wenn es möglich wäre, 20 MB, 1000-Wege-assoziative Level-1-Caches zu haben, ohne dass die Chips die Größe von Manhattan hätten (und die gleiche Art von Strom verbrauchen), dann hätten wir alle Computer mit solchen Chips!
Die niedrigste Ebene von Caches in heutigen CPUs hat sich in den letzten zehn Jahren nicht so sehr verändert. Der Cache der Stufe 3 ist jedoch weiter gewachsen. Vor einem Jahrzehnt konnten Sie 12 MB davon erhalten, wenn Sie das Glück hatten, einen intel i7-980X für 999 US-Dollar zu besitzen. Für die Hälfte dieses Betrags erhalten Sie heute 64 MB.
Cache, kurz gesagt: absolut benötigte, absolut großartige Technologie. Wir haben uns keine anderen Caches in CPUs und GPUs angesehen (z. B. Übersetzungs-Lookup-Puffer oder Textur-Caches), aber da sie alle einer einfachen Struktur und einem einfachen Muster von Ebenen folgen, wie wir es hier behandelt haben, klingen sie vielleicht nicht so kompliziert.
Hatten Sie einen Computer mit L2-Cache auf dem Motherboard? Wie wäre es mit den Slot-basierten Pentium II- und Celeron-CPUs (z. B. 300a), die in einem Daughterboard enthalten waren? Können Sie sich an Ihre erste CPU erinnern, die L3 geteilt hatte? Lassen Sie es uns in den Kommentaren wissen.
Einkaufsverknüpfungen:
- AMD Ryzen 9 3900X bei Amazon
- AMD Ryzen 9 3950X bei Amazon
- Intel Core i9-10900K bei Amazon
- AMD Ryzen 7 3700X bei Amazon
- Intel Core i7-10700K bei Amazon
- AMD Ryzen 5 3600 bei Amazon
- Intel Core i5 -10600K bei Amazon
Lesen Sie weiter. Erklärer bei TechSpot
- Wi-Fi 6 erklärt: Die nächste Generation von Wi-Fi
- Was sind Tensorkerne?
- Was ist Chip-Binning?
Leave a Reply