křivka AUC-ROC ve strojovém učení jasně vysvětlena
křivka AUC-ROC – hvězdný umělec!
vytvořili jste svůj model strojového učení – tak co bude dál? Musíte to vyhodnotit a ověřit, jak dobrý (nebo špatný) je, abyste se pak mohli rozhodnout, zda jej implementovat. To je místo, kde křivka AUC-ROC přichází.
název může být sousto, ale to jen říká, že jsme výpočet „plocha pod křivkou“ (AUC) „přijímač charakteristický operátor“ (ROC). Zmatený? Cítím tě! Byl jsem na tvém místě. Ale nebojte se, uvidíme, co tyto pojmy znamenají podrobně a všechno bude hračka!

prozatím víme, že křivka AUC-ROC nám pomáhá vizualizovat, jak dobře funguje náš klasifikátor strojového učení. I když to funguje pouze pro binární klasifikaci problémů, uvidíme na konci, jak můžeme rozšířit na vyhodnocení multi-třídy klasifikace problémy.
budeme se zabývat tématy, jako je citlivost a specificita, protože se jedná o klíčová témata za křivkou AUC-ROC.
navrhuji projít článek o matici zmatku, protože představí některé důležité pojmy, které budeme používat v tomto článku.
obsah
- co jsou citlivost a specificita?
- Pravděpodobnost předpovědí
- jaká je křivka AUC-ROC?
- jak křivka AUC-ROC funguje?
- AUC – ROC v Pythonu
- AUC – ROC pro klasifikaci více tříd
co jsou citlivost a specificita?
takto vypadá matrice zmatku:
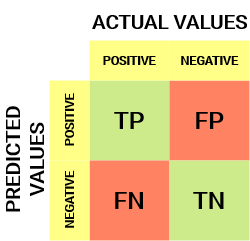
z matrice zmatku můžeme odvodit některé důležité metriky, které nebyly diskutovány v předchozím článku. Promluvme si o nich zde.
Citlivost / True Positive Rate / Recall
![]()
Citlivost nám říká, jaký podíl pozitivních třída má správně klasifikovány.
jednoduchým příkladem by bylo zjistit, jaký podíl skutečných nemocných byl model správně detekován.
Míra Falešné negativity
![]()
Falešně Negativní Sazby (FNR) nám říká, jaký podíl pozitivních třídy dostal nesprávně klasifikovány podle číselníku.
vyšší TPR a nižší FNR je žádoucí, protože chceme správně klasifikovat pozitivní třídu.
specificita / True negativní míra
![]()
specificita nám říká, jaký podíl negativní třídy dostal správně klasifikovány.
při stejném příkladu jako v citlivosti by specificita znamenala určení podílu zdravých lidí, kteří byli správně identifikováni modelem.
Falešné pozitivity
![]()
FPR nám říká, jaký podíl negativních třídy dostal nesprávně klasifikovány podle číselníku.
vyšší TNR a nižší FPR je žádoucí, protože chceme správně klasifikovat zápornou třídu.
z těchto metrik je možná nejdůležitější citlivost a specificita a později uvidíme, jak se tyto metriky používají k vytvoření hodnotící metriky. Ale předtím pochopíme, proč je pravděpodobnost predikce lepší než přímé předpovídání cílové třídy.
Pravděpodobnost Předpovědi
strojové učení klasifikace model může být použit k předpovědět skutečnou třídu datového bodu přímo nebo předpovědět svou pravděpodobnost patřící do různých tříd. Ten nám dává větší kontrolu nad výsledkem. Můžeme určit vlastní prahovou hodnotu pro interpretaci výsledku klasifikátoru. To je někdy obezřetnější než jen budování zcela nového modelu!
nastavení různých prahových hodnot pro klasifikaci pozitivní třídy pro datové body neúmyslně změní citlivost a specificitu modelu. A jednou z těchto hodnot, bude pravděpodobně lepší výsledek, než ostatní, v závislosti na tom, zda chceme snížit počet Falešně Negativních nebo Falešně Pozitivních výsledků.
podívejte se na následující tabulku:
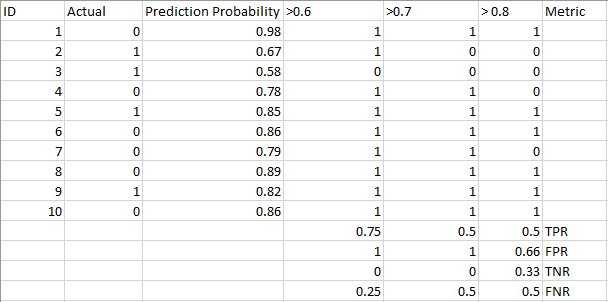
metriky se mění s měnícími se prahovými hodnotami. Můžeme generovat různé matrice zmatku a porovnat různé metriky, které jsme diskutovali v předchozí části. Ale to by nebylo rozumné. Místo toho můžeme vytvořit graf mezi některými z těchto metrik, abychom si mohli snadno představit, který práh nám dává lepší výsledek.
křivka AUC-ROC řeší právě tento problém!
jaká je křivka AUC-ROC?
křivka charakteristiky operátora přijímače (Roc) je hodnotící metrika pro binární klasifikační problémy. Je to křivka pravděpodobnosti, která vykresluje TPR proti FPR při různých prahových hodnotách a v podstatě odděluje „signál“ od „šumu“. Plocha pod křivkou (AUC) je měřítkem schopnosti klasifikátoru rozlišovat mezi třídami a používá se jako souhrn křivky ROC.
čím vyšší je AUC, tím lepší je výkon modelu při rozlišování mezi pozitivními a negativními třídami.
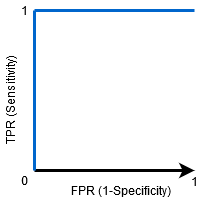
Když AUC = 1, pak klasifikátor je schopen dokonale rozlišovat mezi Pozitivní a Negativní třídy body správně. Li, nicméně, AUC byla 0, pak by klasifikátor předpovídal všechny negativy jako pozitiva, a všechna pozitiva jako negativy.
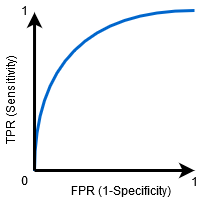
Když 0.5<AUC<1, existuje vysoká šance, že klasifikátor bude schopen rozlišit pozitivní třídy hodnoty z negativního třídy hodnot. Je tomu tak proto, že klasifikátor je schopen detekovat více čísel, Skutečné pozitiva a Pravda negativ než falešně negativních a Falešně pozitivních.
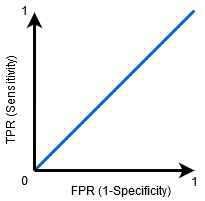
Když AUC=0,5, pak třídění není schopen rozlišovat mezi Pozitivní a Negativní třídy bodů. To znamená, že klasifikátor předpovídá náhodnou třídu nebo konstantní třídu pro všechny datové body.
čím vyšší je hodnota AUC pro klasifikátor, tím lepší je jeho schopnost rozlišovat mezi pozitivními a negativními třídami.
jak křivka AUC-ROC funguje?
v křivce ROC vyšší hodnota osy X označuje vyšší počet falešných pozitiv než skutečné negativy. Zatímco vyšší hodnota osy Y označuje vyšší počet skutečných pozitiv než falešných negativů. Takže volba prahu závisí na schopnosti vyvážit mezi falešnými pozitivy a falešnými negativy.
pojďme kopat trochu hlouběji a pochopit, jak by naše Roc křivka vypadala pro různé prahové hodnoty a jak by se specificita a citlivost lišily.
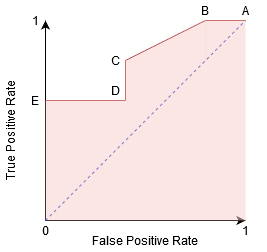
můžeme to zkusit a pochopit tento graf generování confusion matrix pro každý bod odpovídající práh a mluvit o výkonnosti našich klasifikátor:
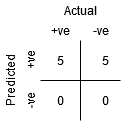
Bod je místo, kde je Citlivost nejvyšší a Specifičnost nejnižší. To znamená, že všechny kladné body třídy jsou klasifikovány správně a všechny záporné body třídy jsou klasifikovány nesprávně.
Ve skutečnosti, každý bod na modré čáře odpovídá situaci, kdy je Pravda, Pozitivní Sazba je rovna Falešné pozitivity.
Všechny body nad tento řádek odpovídá situaci, kdy podíl správně klasifikovaných bodů, které patří do Pozitivní třídy je větší než podíl chybně klasifikovaných bodů, které patří do Negativní třídu.
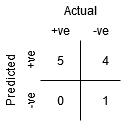
i když Bod B má stejnou Citlivost jako Bod A, má vyšší Specificitu. To znamená, že počet nesprávně záporných bodů třídy je nižší ve srovnání s předchozím prahem. To znamená, že tato prahová hodnota je lepší než předchozí.
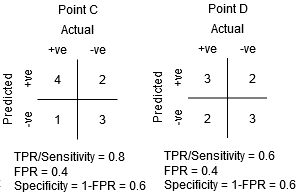
mezi body C A D je citlivost v bodě C vyšší než bod D pro stejnou specificitu. To znamená, že pro stejný počet nesprávně klasifikovaných Negativní třídy bodů, klasifikátor předpokládá vyšší počet Pozitivních třídy bodů. Proto, prahová hodnota v bodě C je lepší než bod D.
Nyní, v závislosti na tom, kolik nesprávně klasifikovány body chceme tolerovat pro náš klasifikátor, bychom si vybrat mezi bodem B nebo C pro predikci, zda můžete porazit mě v PUBG, nebo ne.
“ falešné naděje jsou nebezpečnější než obavy.“- J. R. R. Tolkein

Bod E je místo, kde Specifičnost stává nejvyšší. To znamená, že podle modelu nejsou klasifikovány žádné falešné pozitivy. Model může správně klasifikovat všechny negativní body třídy! Tento bod bychom si vybrali, kdyby naším problémem bylo poskytnout našim uživatelům perfektní doporučení písní.
Pokud jde o tuto logiku, můžete hádat, kde by bod odpovídající dokonalému klasifikátoru ležel na grafu?
Ano! Bylo by to v levém horním rohu grafu ROC odpovídajícího souřadnici (0, 1) v kartézské rovině. Právě zde by citlivost a specificita byly nejvyšší a klasifikátor by správně klasifikoval všechny kladné a záporné třídní body.
Pochopení AUC-ROC Křivka v Pythonu
Nyní můžeme buď ručně otestovat Citlivost a Specificita pro každý práh nebo nechat sklearn dělat práci za nás. Rozhodně jdeme s druhým!
vytvoříme libovolná data pomocí metody sklearn make_classification:
budu testovat výkon dvou klasifikátorů v tomto souboru:
Sklearn má velmi silný způsob roc_curve (), která počítá ROC pro vaše klasifikátor během několika sekund! Vrátí FPR, TPR, a prahové hodnoty:
AUC skóre může být vypočítáno pomocí roc_auc_score() metoda sklearn:
0.9761029411764707 0.9233769727403157
Zkuste tento kód v live codingu okno níže:
můžeme také vykreslit ROC křivky pro dva algoritmy pomocí matplotlib:
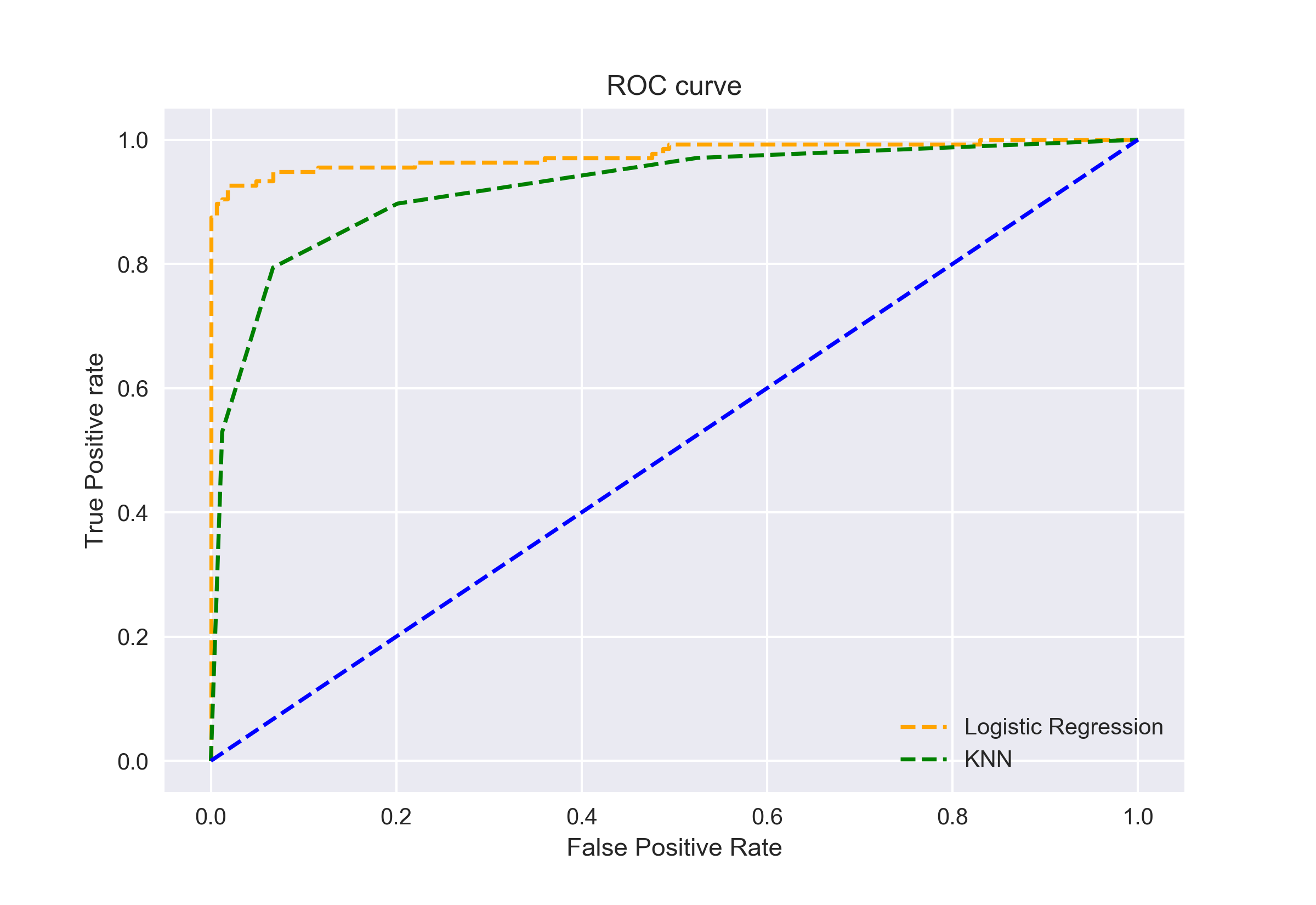
z grafu je zřejmé, že AUC pro křivku Roc logistické regrese je vyšší než AUC pro křivku KNN ROC. Proto můžeme říci, že logistická regrese odvedla lepší práci při klasifikaci pozitivní třídy v datovém souboru.
AUC-ROC pro klasifikaci více tříd
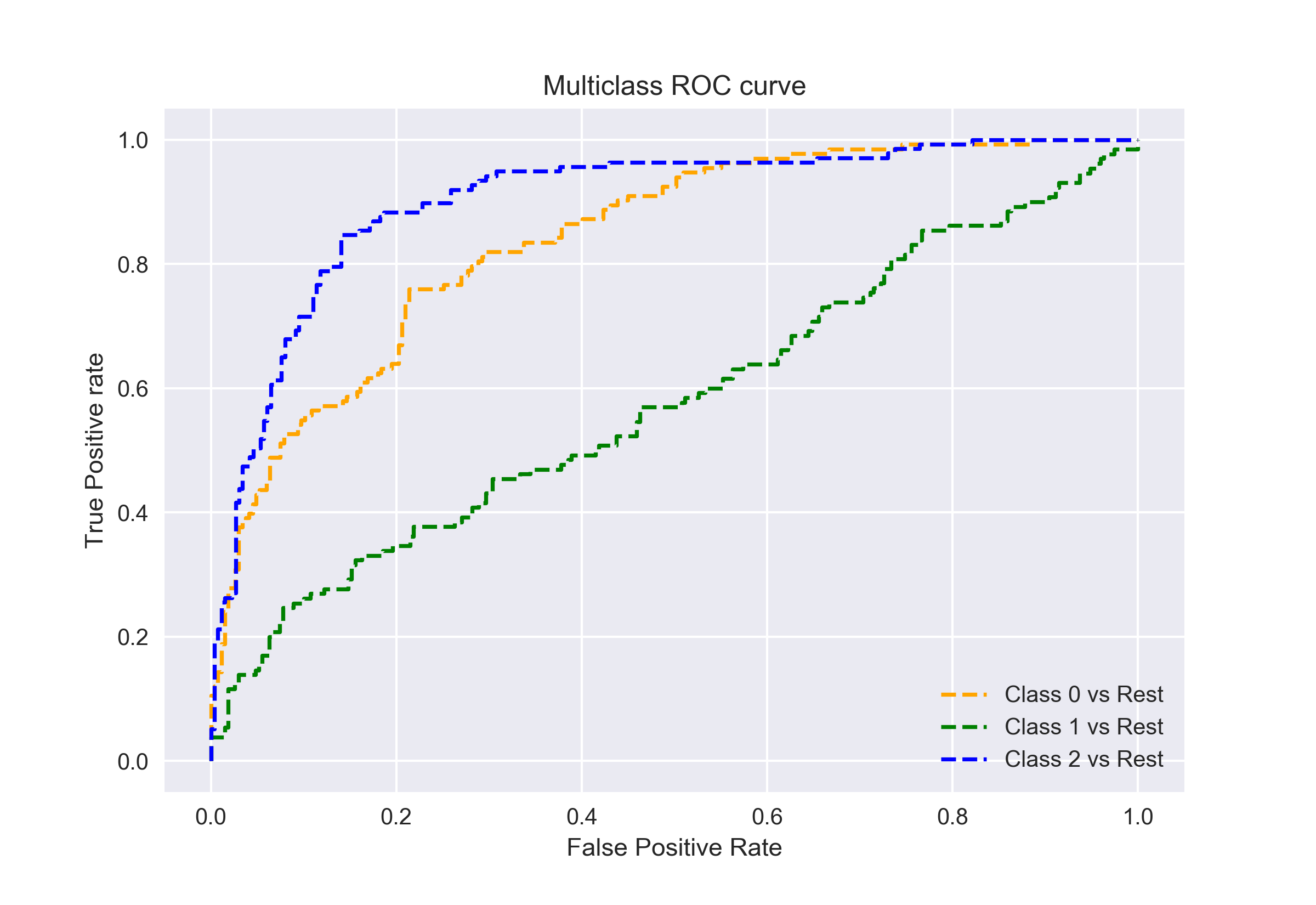
Jak jsem řekl dříve, křivka AUC-ROC je pouze pro binární klasifikační problémy. Ale můžeme ji rozšířit na klasifikační problémy multiclass pomocí techniky One vs All.
takže pokud máme tři třídy 0, 1 a 2, ROC pro třídu 0 bude generován jako klasifikace 0 proti ne 0, tj. 1 a 2. ROC pro třídu 1 bude generován jako klasifikace 1 proti ne 1, a tak dále.
ROC křivka pro multi-třídy klasifikace modelů může být stanovena, jak je uvedeno níže:
Poznámky
doufám, že jste našli tento článek užitečné v pochopení toho, jak silný AUC-ROC křivka metrika je v měření výkonnosti klasifikátoru. Budete používat to hodně v průmyslu a dokonce i v datové vědy nebo strojového učení hackathons. Lepší se s tím seznámit!
dále doporučila bych vám následující kurzy, které budou užitečné při budování vašeho data science postřeh:
- Úvod do Data Science
- Aplikuje Strojového Učení
můžete Si také přečíst tento článek na naší Mobilní APLIKACE![]()

Leave a Reply