Explainer: L1 vs. L2 vs. L3 Cache
varje enskild CPU som finns i vilken dator som helst, från en billig bärbar dator till en miljon dollar server, kommer att ha något som heter cache. Mer troligt än inte, det kommer att ha flera nivåer av det också.
det måste vara viktigt, annars varför skulle det vara där? Men vad gör cache, och varför behovet av olika nivåer av saker? Vad i hela friden betyder 12-vägs uppsättning associativ till och med?
vad exakt är cache?
TL;DR: det är litet, men mycket snabbt minne som sitter precis bredvid CPU: s logiska enheter.
men naturligtvis finns det mycket mer vi kan lära oss om cache…
Låt oss börja med ett imaginärt, magiskt lagringssystem: det är oändligt snabbt, kan hantera ett oändligt antal datatransaktioner samtidigt och håller alltid data säkra och säkra. Inte för att någonting ens på distans till detta existerar, men om det gjorde det skulle processorns design vara mycket enklare.
processorer behöver bara ha logiska enheter för att lägga till, multiplicera etc. och ett system för att hantera dataöverföringarna. Detta beror på att vårt teoretiska lagringssystem direkt kan skicka och ta emot alla nummer som krävs; ingen av de logiska enheterna skulle hållas uppe och vänta på en datatransaktion.
men som vi alla vet finns det ingen magisk lagringsteknik. Istället har vi hårda eller solid state-enheter, och även de bästa av dessa är inte ens på distans kapabla att hantera alla dataöverföringar som krävs för en typisk CPU.
den stora t ’ Phon av datalagring
anledningen är att moderna processorer är otroligt snabba-de tar bara en klockcykel för att lägga till två 64 bitars heltal värden tillsammans, och för en CPU som körs på 4 GHz, skulle detta vara bara 0.00000000025 sekunder eller en fjärdedel av en nanosekund.
samtidigt tar snurrande hårddiskar tusentals nanosekunder bara för att hitta data på skivorna inuti, än mindre överföra den, och solid state-enheter tar fortfarande tiotals eller hundratals nanosekunder.
sådana enheter kan uppenbarligen inte byggas in i processorer, så det betyder att det kommer att finnas en fysisk separation mellan de två. Detta lägger bara mer tid på att flytta data, vilket gör saker ännu värre.

den stora a ’ tuin av datalagring, tyvärr
Så vad vi behöver är ett annat datalagringssystem som sitter mellan processorn och huvudlagringen. Det måste vara snabbare än en enhet, kunna hantera massor av dataöverföringar samtidigt och vara mycket närmare processorn.
Tja, vi har redan en sådan sak, och det kallas RAM, och varje datorsystem har några för just detta ändamål.
nästan av all denna typ av lagring är DRAM (dynamic random access memory) och det kan överföra data mycket snabbare än någon enhet.
men medan DRAM är supersnabb kan den inte lagra någonstans nära så mycket data.
några av de största DDR4-minneskretsarna gjorda av Micron, en av få tillverkare av DRAM, rymmer 32 Gbit eller 4 GB data; de största hårddiskarna håller 4000 gånger mer än detta.
så även om vi har förbättrat hastigheten på vårt datanätverk, kommer ytterligare system-hårdvara och mjukvara-att krävas för att räkna ut vilka data som ska hållas i den begränsade mängden DRAM, redo för CPU.
åtminstone DRAM kan tillverkas för att vara i chippaketet (känt som embedded DRAM). CPU: er är dock ganska små, så du kan inte hålla så mycket i dem.

10 MB DRAM precis till vänster om Xbox 360s grafikprocessor. Källa: CPU Grave Yard
den stora majoriteten av DRAM ligger precis bredvid processorn, ansluten till moderkortet, och det är alltid den närmaste komponenten till CPU, i ett datorsystem. Och ändå är det fortfarande inte tillräckligt snabbt…
DRAM tar fortfarande cirka 100 nanosekunder för att hitta data, men det kan åtminstone överföra miljarder bitar varje sekund. Det verkar som om vi behöver ett annat minnesstadium för att gå in mellan processorns enheter och DRAM.
Ange steg till vänster: SRAM (statiskt slumpmässigt åtkomstminne). Där DRAM använder mikroskopiska kondensatorer för att lagra data i form av elektrisk laddning, använder SRAM transistorer för att göra samma sak och dessa kan fungera nästan lika snabbt som logikenheterna i en processor (ungefär 10 gånger snabbare än DRAM).
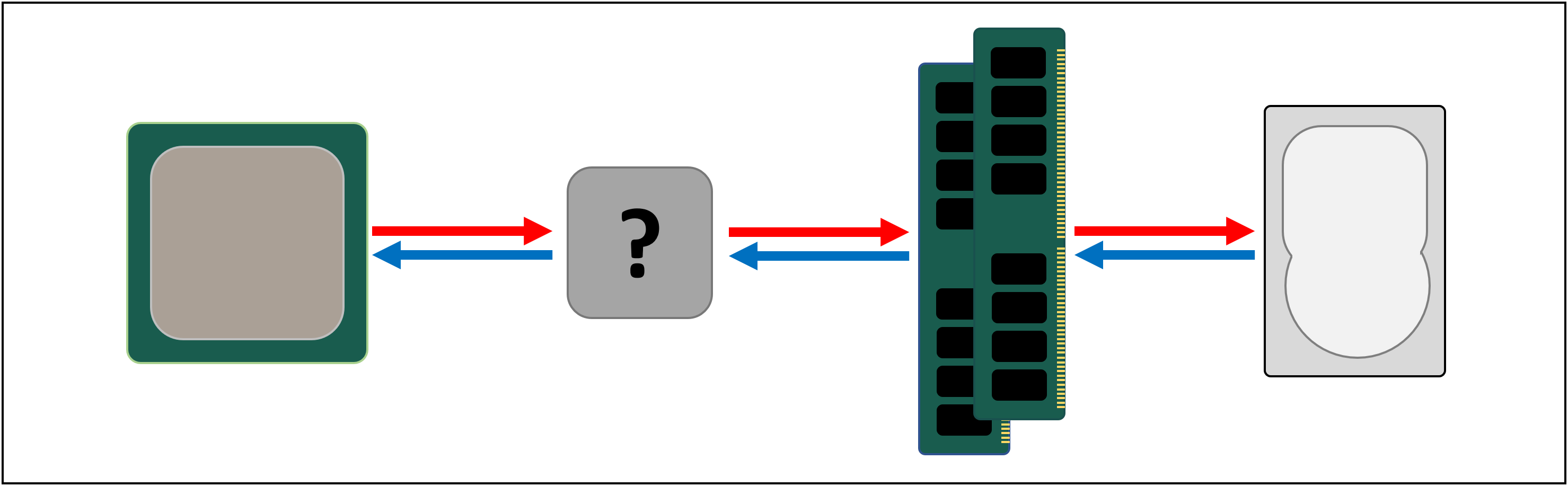
det finns naturligtvis en nackdel med SRAM och återigen handlar det om rymden.
Transistorbaserat minne tar mycket mer utrymme än DRAM: för samma storlek 4 GB DDR4-chip skulle du få mindre än 100 MB värde av SRAM. Men eftersom det görs genom samma process som att skapa en CPU, kan SRAM byggas direkt inuti processorn, så nära de logiska enheterna som möjligt.
Transistorbaserat minne tar mycket mer utrymme än DRAM: för samma storlek 4 GB DDR4-chip skulle du få mindre än 100 MB värde av SRAM.
med varje extra steg har vi ökat hastigheten för att flytta data om, till kostnaden för hur mycket vi kan lagra. Vi kan fortsätta att lägga till i fler avsnitt, var och en är snabbare men mindre.
och så kommer vi fram till en mer teknisk definition av vad cache är: det är flera block av SRAM, alla placerade inuti processorn; de används för att säkerställa att de logiska enheterna hålls så upptagna som möjligt genom att skicka och lagra data med supersnabba hastigheter. Nöjd med det? Bra – för det kommer att bli mycket mer komplicerat härifrån!
Cache: en parkeringsplats på flera nivåer
som vi diskuterade behövs cache eftersom det inte finns ett magiskt lagringssystem som kan hålla jämna steg med datakraven för de logiska enheterna i en processor. Moderna processorer och grafikprocessorer innehåller ett antal SRAM-block, som är internt organiserade i en hierarki-en sekvens av cachar som är ordnade enligt följande:

i ovanstående bild representeras CPU: n av den svarta streckade rektangeln. ALUs (aritmetiska logiska enheter) är längst till vänster; det här är de strukturer som driver processorn och hanterar matematiken som chipet gör. Medan dess tekniskt inte cache, är den närmaste nivån av minne till Alu: erna registren (de är grupperade i en registerfil).
var och en av dessa har ett enda nummer, till exempel ett 64-bitars heltal; själva värdet kan vara en bit data om något, en kod för en specifik instruktion eller minnesadressen för vissa andra data.
registerfilen i en stationär CPU är ganska liten – till exempel i Intels Core i9-9900K finns det två banker av dem i varje kärna, och den för heltal innehåller bara 180 64-bitars register. Den andra registerfilen, för vektorer (små matriser med siffror), har 168 256-bitars poster. Så den totala registerfilen för varje kärna är lite under 7 kB. Som jämförelse är registerfilen i Strömmande Multiprocessorer (GPU: s motsvarighet till en CPU-kärna) av en Nvidia GeForce RTX 2080 Ti 256 kB i storlek.
Register är SRAM, precis som cache, men de är lika snabba som Aluerna de tjänar, och trycker in och ut data i en enda klockcykel. Men de är inte utformade för att hålla mycket data (bara en enda del av det), varför det alltid finns några större minnesblock i närheten: det här är Nivå 1-cachen.
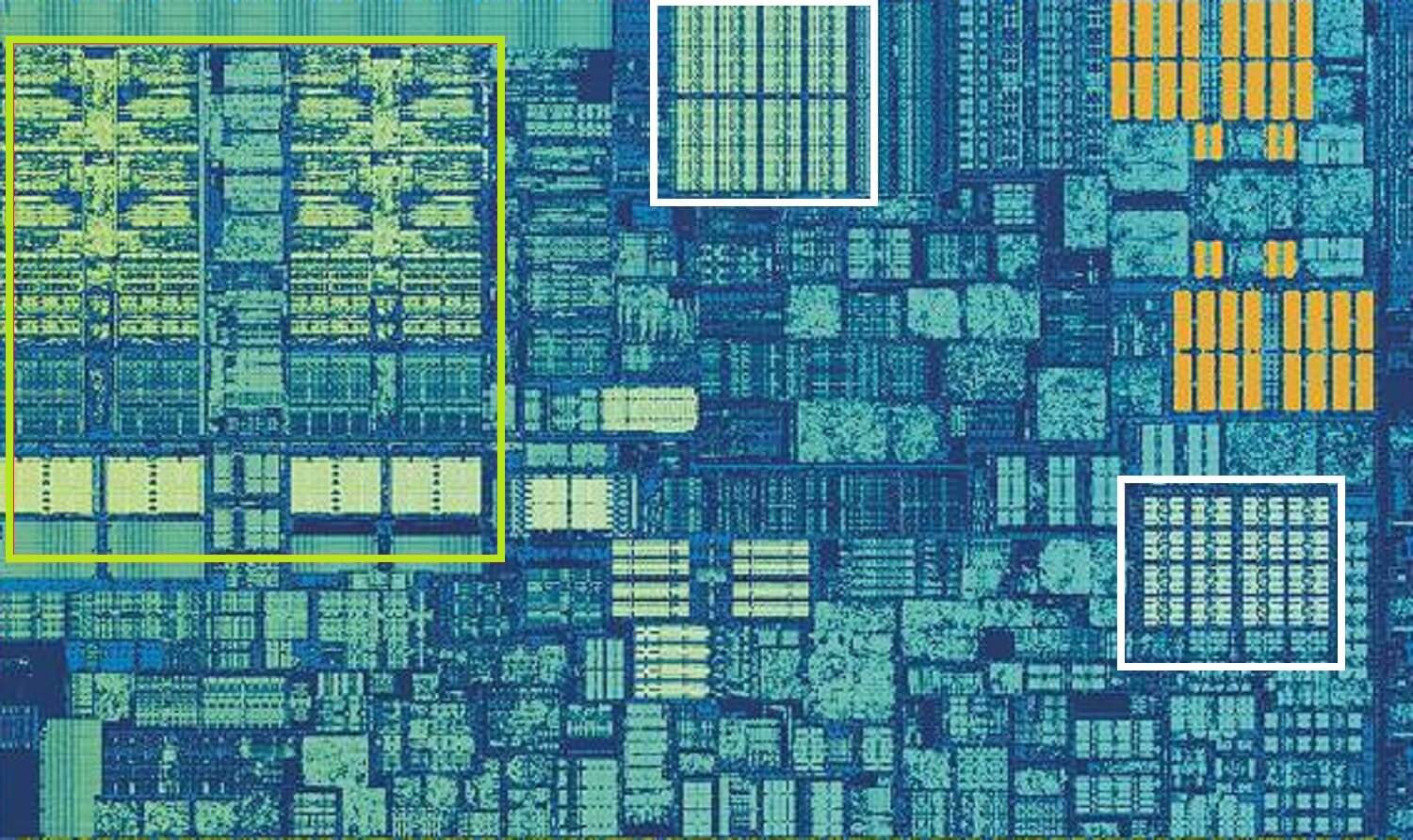
Intel Skylake CPU, zoomad i skott av en enda kärna. Källa: Wikichip
ovanstående bild är en zoomad bild av en enda kärna från Intels Skylake desktop processor design.
Alu: erna och registerfilerna kan ses längst till vänster, markerade med grönt. I den övre mitten av bilden, i vitt, är Nivå 1-datacachen. Det här innehåller inte mycket information, bara 32 kB, men som Register är det mycket nära logikenheterna och körs med samma hastighet som dem.
den andra vita rektangeln indikerar Nivå 1 Instruktionscache, även 32 kB i storlek. Som namnet antyder lagrar detta olika kommandon som är redo att delas upp i mindre, så kallade mikrooperationer (vanligtvis märkta som ubicops), för ALUs att utföra. Det finns också en cache för dem, och du kan klassificera den som Nivå 0, eftersom den är mindre (endast håller 1500 operationer) och närmare än L1-cacharna.
Du kanske undrar varför dessa block av SRAM är så små; varför är de inte en megabyte i storlek? Tillsammans tar data-och instruktionscacherna nästan samma mängd utrymme i chipet som de viktigaste logiska enheterna gör, så att göra dem större skulle öka den totala storleken på munstycket.
men den främsta anledningen till att de bara håller några kB är att tiden som behövs för att hitta och hämta data ökar när minneskapaciteten blir större. L1-cache måste vara riktigt snabb, och så måste en kompromiss nås, mellan storlek och hastighet-i bästa fall tar det cirka 5 klockcykler (längre för flyttalsvärden) för att få data ur denna cache, redo att användas.
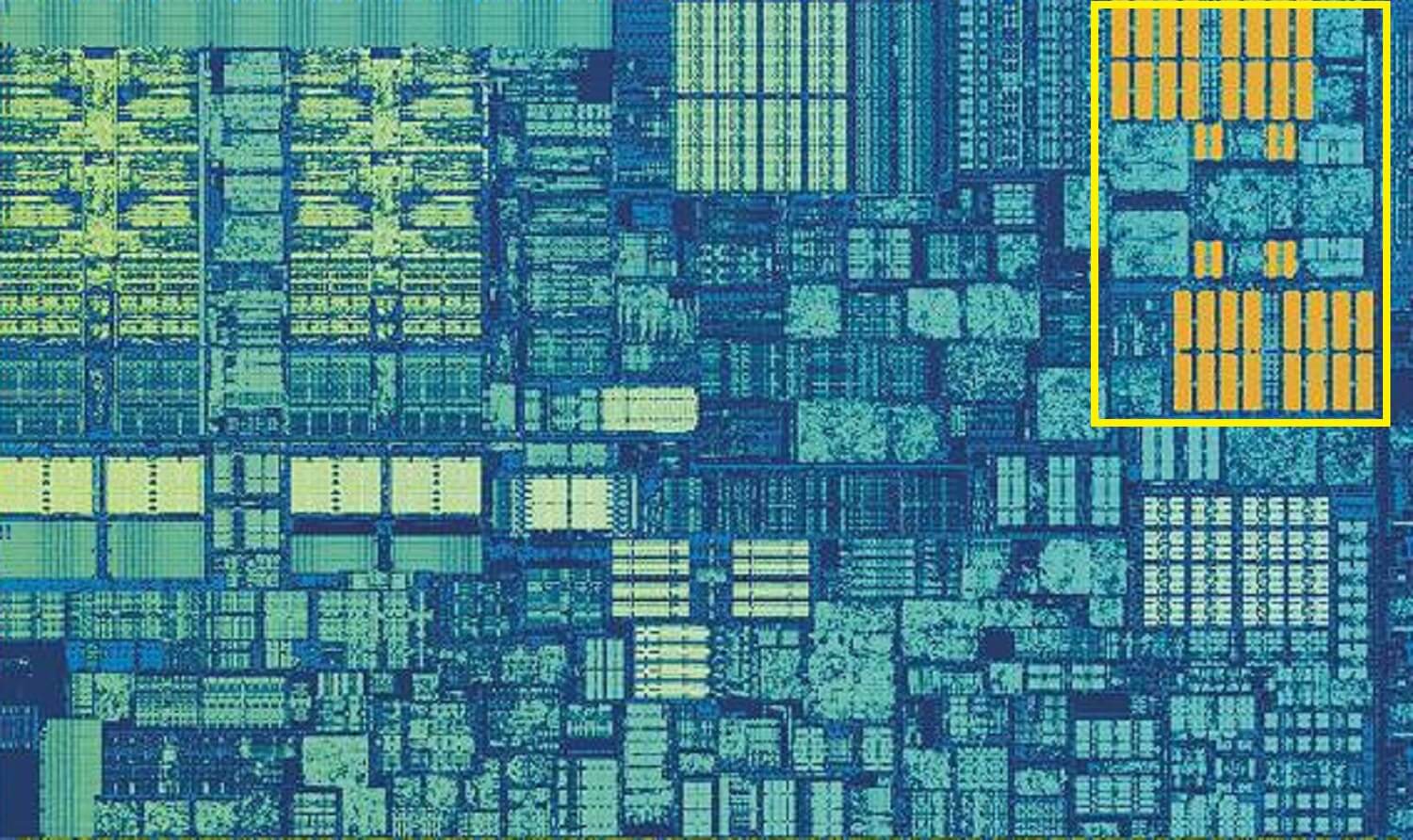
Skylakes L2-cache: 256 kB av SRAM godhet
men om detta var den enda cachen i en processor, skulle dess prestanda slå en plötslig vägg. Det är därför de alla har en annan minnesnivå inbyggd i kärnorna: nivå 2-cachen. Detta är ett allmänt lagringsblock som håller på instruktioner och data.
det är alltid ganska lite större än Nivå 1: AMD Zen 2-processorer packar upp till 512 kB, så de lägre nivåcacharna kan hållas väl levererade. Denna extra storlek kostar dock, och det tar ungefär dubbelt så lång tid att hitta och överföra data från denna cache, jämfört med Nivå 1.
gå tillbaka i tiden, till dagarna för den ursprungliga Intel Pentium, nivå 2 cache var ett separat chip, antingen på ett litet plug-in kretskort (som en RAM DIMM) eller inbyggd i huvudkortets moderkort. Det fungerade så småningom på själva CPU-paketet tills det slutligen integrerades i CPU-matrisen, i likhet med Pentium III och AMD K6-III-processorerna.
denna utveckling följdes snart av en annan nivå av cache, där för att stödja de andra lägre nivåerna, och det uppstod på grund av ökningen av flerkärniga chips.

Intel Kaby Lake chip. Källa: Wikichip
den här bilden, av ett Intel Kaby Lake-chip, visar 4 kärnor i vänster mitten (en integrerad GPU tar upp nästan hälften av munstycket till höger). Varje kärna har sin egen ’privata’ uppsättning Nivå 1 och 2 cachar (vita och gula höjdpunkter), men de kommer också med en tredje uppsättning SRAM-block.
nivå 3-cache, även om den är direkt runt en enda kärna, delas helt med de andra-var och en kan fritt komma åt innehållet i andras L3-cache. Det är mycket större (mellan 2 och 32 MB) men också mycket långsammare, i genomsnitt över 30 cykler, speciellt om en kärna behöver använda data som ligger i ett block av cache något avstånd bort.
nedan kan vi se en enda kärna i AMDs Zen 2-arkitektur: 32 kB Nivå 1 data och instruktionscachar i vitt, 512 KB nivå 2 i gult och ett enormt 4 MB block av L3-cache i rött.

AMD Zen 2 CPU, zoomad i skott av en enda kärna. Källa: Fritzchens Fritz
vänta en sekund. Hur kan 32 kB ta mer fysiskt utrymme än 512 kB? Om Nivå 1 innehåller så lite data, varför är det proportionellt så mycket större än L2 eller L3 cache?
mer än bara ett nummer
Cache ökar prestanda genom att påskynda dataöverföring till de logiska enheterna och hålla en kopia av ofta använda instruktioner och data i närheten. Informationen som lagras i cacheminnet är uppdelad i två delar: själva data och platsen för var den ursprungligen var belägen i systemminnet/lagringen-den här adressen kallas en cachetagg.
när processorn kör en operation som vill läsa eller skriva data från/till minnet börjar den med att kontrollera taggarna i nivå 1-cachen. Om den nödvändiga är närvarande (en cache-träff) kan dessa data nås nästan direkt. En cache miss uppstår när den önskade taggen inte är i den lägsta cache-nivån.
så en ny tagg skapas i L1-cachen, och resten av processorarkitekturen tar över och jagar tillbaka genom de andra cachenivåerna (hela vägen tillbaka till huvudlagringsenheten, om det behövs) för att hitta data för den taggen. Men för att göra plats i L1-cachen för den här nya taggen måste något annat alltid startas ut i L2.
detta resulterar i en nästan konstant blandning av data, alla uppnådda i bara en handfull klockcykler. Det enda sättet att uppnå detta är genom att ha en komplex struktur runt SRAM, för att hantera hanteringen av data. Sätt ett annat sätt: om en CPU-kärna bestod av bara en ALU, skulle L1-cachen vara mycket enklare, men eftersom det finns dussintals av dem (varav många kommer att jonglera två trådar med instruktioner) kräver cachen flera anslutningar för att hålla allt på resande fot.
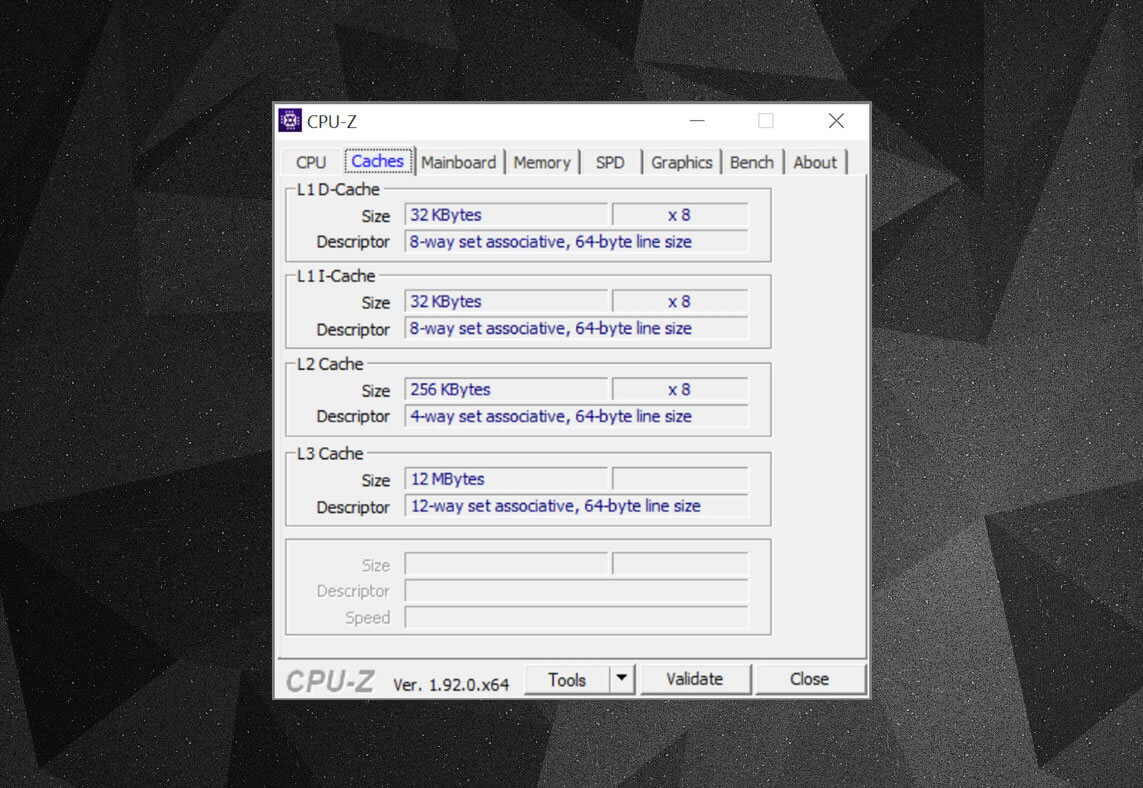
Du kan använda gratisprogram, till exempel CPU-Z, för att kolla in cacheinformationen för processorn som driver din egen dator. Men vad betyder all denna information? Ett viktigt element är etikettuppsättningen associativ – det här handlar om reglerna som verkställs av hur block av data från systemminnet kopieras till cacheminnet.
ovanstående cacheinformation är för en Intel Core i7-9700K. dess nivå 1-cachar delas upp i 64 små block, kallade uppsättningar, och var och en av dessa är vidare uppdelad i cachelinjer (64 byte i storlek). Ange associativ innebär att ett block av data från systemminnet mappas på cacheminnet i en viss uppsättning, snarare än att vara fri att kartlägga över var som helst.
8-vägs delen berättar att ett block kan associeras med 8 cache linjer i en uppsättning. Ju större associativitetsnivå (dvs. fler sätt), desto bättre är chansen att få en cache-träff när CPU går på jakt efter data och en minskning av påföljderna som orsakas av cache-missar. Nackdelarna är att det ger mer komplexitet, ökad strömförbrukning och kan också minska prestanda eftersom det finns fler cachelinjer att bearbeta för ett datablock.

L1+L2 inklusive cache, L3 offer cache, skriv-Back polices, även ECC. Källa: Fritzchens Fritz
en annan aspekt på cachens komplexitet kretsar kring hur data hålls över de olika nivåerna. Reglerna fastställs i något som kallas integrationspolitiken. Till exempel har Intel Core-processorer helt inkluderande L1+L3-cache. Detta innebär att samma data i nivå 1, till exempel, kan också vara i nivå 3. Det kan tyckas att det slösar bort värdefullt cacheutrymme, men fördelen är att om processorn får en miss, när man söker efter en tagg på en lägre nivå, behöver den inte jaga igenom den högre nivån för att hitta den.
i samma processorer är L2-cachen icke-inkluderande: all data som lagras där kopieras inte till någon annan nivå. Detta sparar utrymme, men resulterar i att chipets minnessystem måste söka igenom L3 (vilket alltid är mycket större) för att hitta en missad tagg. Offercachar liknar detta, men de är vana vid lagrad information som skjuts ut ur en lägre nivå-till exempel använder AMDs Zen 2-processorer L3 offercache som bara lagrar data från L2.
det finns andra policyer för cache, till exempel när data skrivs in i cache och huvudsystemminnet. Dessa kallas skrivpolicyer och de flesta av dagens processorer använder skrivback-cachar; detta innebär att när data skrivs in i en cacheminne, finns det en fördröjning innan systemminnet uppdateras med en kopia av det. För det mesta körs denna paus så länge data finns kvar i cachen-bara när den har startats ut, får RAM-minnet informationen.

Nvidias ga100-grafikprocessor, packad med totalt 20 MB L1 och 40 MB L2-cache
för processordesigners handlar det om att välja mängd, typ och policy för cache om att balansera önskan om större processorkapacitet mot ökad komplexitet och krävs die-utrymme. Om det var möjligt att ha 20 MB, 1000-vägs helt associativa Nivå 1-cachar utan att chipsen blev storleken på Manhattan (och konsumerar samma typ av kraft), skulle vi alla ha datorer som sportar sådana chips!
den lägsta nivån av cachar i dagens processorer har inte förändrats så mycket under det senaste decenniet. Nivå 3 cache har dock fortsatt att växa i storlek. För ett decennium sedan kunde du få 12 MB av det, om du hade turen att äga en $999 Intel i7-980X. för hälften av det beloppet idag får du 64 MB.
Cache, i ett nötskal: absolut behövs, absolut fantastiska bitar av teknik. Vi har inte tittat på andra cachtyper i processorer och GPU: er (som översättningsbuffertar eller texturcachar), men eftersom de alla följer en enkel struktur och mönster av nivåer som vi har täckt här, kanske de inte låter så komplicerade.
ägde du en dator som hade L2-cache på moderkortet? Vad sägs om de slot-baserade Pentium II-och Celeron-processorerna (t. ex. 300a) som kom i en daughterboard? Kommer du ihåg din första CPU som hade delat L3? Låt oss veta i kommentarfältet.
Shopping genvägar:
- AMD Ryzen 9 3900X på Amazon
- AMD Ryzen 9 3950X på Amazon
- Intel Core i9-10900k på Amazon
- AMD Ryzen 7 3700X på Amazon
- Intel Core i7-10700k på Amazon
- AMD Ryzen 5 3600 på Amazon
- Intel Core i5-10600k på Amazon
Fortsätt läsa. Förklarare på TechSpot
- Wi-Fi 6 förklarade: nästa Generation av Wi-Fi
- Vad är Tensorkärnor?
- Vad är Chip Binning?
Leave a Reply