UNION ALL Optimization
concatenarea a două sau mai multe seturi de date este cel mai frecvent exprimată în T-SQL folosind clauzaUNION ALL. Având în vedere că SQL Server optimizer poate reordona adesea lucruri precum îmbinări și agregate pentru a îmbunătăți performanța, este destul de rezonabil să ne așteptăm ca SQL Server să ia în considerare și reordonarea intrărilor de concatenare, unde acest lucru ar oferi un avantaj. De exemplu, Optimizatorul ar putea lua în considerare beneficiile rescrierii A UNION ALL B ca B UNION ALL A.
de fapt, SQL Server optimizer nu face acest lucru. Mai precis, a existat un anumit suport limitat pentru reordonarea intrărilor de concatenare în versiunile SQL Server până la 2008 R2, dar acest lucru a fost eliminat în SQL Server 2012 și nu a reapărut de atunci.
SQL Server 2008 R2
intuitiv, ordinea intrărilor de concatenare contează numai dacă există un obiectiv rând. În mod implicit, SQL Server optimizează planurile de execuție pe baza faptului că toate rândurile de calificare vor fi returnate clientului. Când un obiectiv rând este în vigoare, Optimizatorul încearcă să găsească un plan de execuție care va produce primele câteva rânduri rapid.
obiectivele rândului pot fi setate în mai multe moduri, de exemplu folosindTOP, unFAST n sugestie de interogare sau folosindEXISTS (care prin natura sa trebuie să găsească cel mult un rând). În cazul în care nu există un obiectiv de rând (adică clientul necesită toate rândurile), nu contează în general în ce ordine sunt citite intrările de concatenare: fiecare intrare va fi complet procesată în cele din urmă în orice caz.
suportul limitat în versiunile de până la SQL Server 2008 R2 se aplică în cazul în care există un obiectiv de exact un rând. În această circumstanță specifică, SQL Server va reordona intrările de concatenare pe baza costului așteptat.
acest lucru nu se face în timpul optimizării bazate pe costuri (așa cum s-ar putea aștepta), ci mai degrabă ca o rescriere post-optimizare de ultimă oră a ieșirii normale a optimizatorului. Acest aranjament are avantajul de a nu crește spațiul de căutare a planului bazat pe costuri (potențial o alternativă pentru fiecare reordonare posibilă), producând în același timp un plan optimizat pentru a returna rapid primul rând.
Exemple
următoarele exemple folosesc două tabele cu conținut identic: Un milion de rânduri de numere întregi de la unu la un milion. Un tabel este o grămadă fără indici nonclustered; celălalt are un indice unic grupat:
CREATE TABLE dbo.Expensive( Val bigint NOT NULL); CREATE TABLE dbo.Cheap( Val bigint NOT NULL, CONSTRAINT UNIQUE CLUSTERED (Val));GOINSERT dbo.Cheap WITH (TABLOCKX) (Val)SELECT TOP (1000000) Val = ROW_NUMBER() OVER (ORDER BY SV1.number)FROM master.dbo.spt_values AS SV1CROSS JOIN master.dbo.spt_values AS SV2ORDER BY ValOPTION (MAXDOP 1);GOINSERT dbo.Expensive WITH (TABLOCKX) (Val)SELECT C.ValFROM dbo.Cheap AS COPTION (MAXDOP 1);
nici un gol rând
următoarea interogare caută aceleași rânduri în fiecare tabel, și returnează concatenarea celor două seturi:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005;
planul de execuție produs de instrumentul de optimizare a interogărilor este:
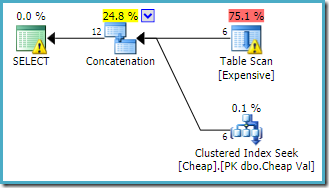
avertismentul de pe rădăcinăSELECT operatorul ne avertizează cu privire la indexul lipsă evident pe tabelul heap. Avertismentul de pe operatorul de scanare de masă este adăugat de Sentry One Plan Explorer. Ne atrage atenția asupra costului I / O al predicatului rezidual ascuns în Scanare.
ordinea intrărilor la concatenare nu contează aici, pentru că nu am stabilit un obiectiv rând. Ambele intrări vor fi citite complet pentru a returna toate rândurile de rezultate. De interes (deși acest lucru nu este garantat) observați că ordinea intrărilor urmează ordinea textuală a interogării originale. Observați, de asemenea, că ordinea rândurilor de rezultat final nu este specificată, deoarece nu am folosit un nivel superior ORDER BY clauză. Vom presupune că este deliberată și ordonarea finală este neimportantă pentru sarcina la îndemână.
dacă inversăm ordinea scrisă a tabelelor din interogare așa:
SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 UNION ALL SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005;
planul de execuție urmează schimbarea, accesând Mai întâi tabelul pus în cluster (din nou, acest lucru nu este garantat):
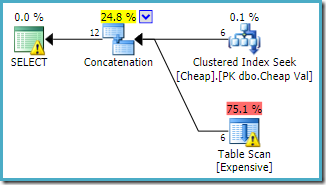
ambele interogări pot fi de așteptat să aibă aceleași caracteristici de performanță, deoarece efectuează aceleași operații, doar într-o ordine diferită.
cu un gol rând
în mod clar, lipsa de indexare pe masa heap va face în mod normal, găsirea rânduri specifice mai scumpe, în comparație cu aceeași operație pe masa grupate. Dacă solicităm optimizatorului un plan care returnează rapid primul rând, ne-am aștepta ca SQL Server să reordoneze intrările de concatenare, astfel încât tabelul grupat ieftin să fie consultat mai întâi.
utilizarea interogării care menționează mai întâi tabelul heap și utilizarea unui indiciu rapid de interogare 1 pentru a specifica obiectivul rândului:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005OPTION (FAST 1);
planul de execuție estimat produs pe o instanță de SQL Server 2008 R2 este:
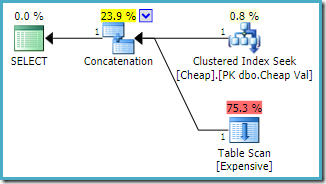
observați că intrările de concatenare au fost reordonate pentru a reduce costul estimat al returnării primului rând. Rețineți, de asemenea, că indexul lipsă și avertismentele i/o reziduale au dispărut. Nici o problemă nu este de consecință cu această formă de plan atunci când obiectivul este de a returna un singur rând cât mai repede posibil.
aceeași interogare executată pe SQL Server 2016 (folosind oricare model de estimare a cardinalității) este:
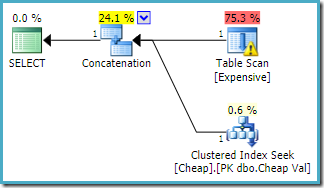
SQL Server 2016 nu a reordonat intrările de concatenare. Avertismentul I/O Plan Explorer a revenit, dar, din păcate, Optimizatorul nu a produs de data aceasta un avertisment index lipsă (deși este relevant).
reordonarea generală
după cum sa menționat, rescrierea post-optimizare care reordonează intrările de concatenare este eficientă numai pentru:
- SQL Server 2008 R2 și mai devreme
- un obiectiv rând de exact un
dacă vrem cu adevărat doar un rând a revenit, mai degrabă decât un plan optimizat pentru a reveni primul rând rapid (dar care va reveni în cele din urmă în continuare toate rândurile), putem folosi un TOP clauza cu un tabel derivat sau
SELECT TOP (1) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UA;
pe SQL Server 2008 R2 sau mai devreme, aceasta produce planul optim reordonate-intrare:
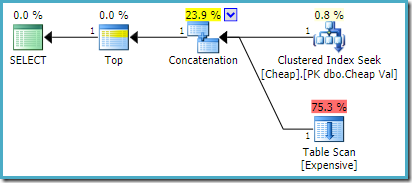
pe SQL Server 2012, 2014 și 2016 nu apare nicio reordonare post-optimizare:
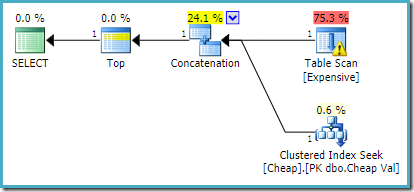
dacă vrem mai mult de un rând returnat, de exemplu folosindTOP (2), rescrierea dorită nu va fi aplicată pe SQL Server 2008 R2 chiar dacă se folosește și un indiciuFAST 1. În această situație, trebuie să recurgem la trucuri precum utilizareaTOP cu o variabilă și unOPTIMIZE FOR indiciu:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed SELECT TOP (@TopRows) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UAOPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint
indiciul de interogare este suficient pentru a seta un obiectiv rând de unul, în timp ce valoarea runtime a variabilei asigură numărul dorit de rânduri (2) este returnat.
planul de execuție real pe SQL Server 2008 R2 este:
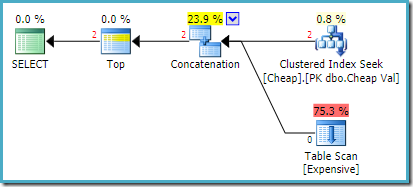
ambele rânduri returnate provin de la intrarea reordonată seek, iar scanarea tabelului nu este executată deloc. Plan Explorer arată numărul de rânduri în roșu, deoarece estimarea a fost pentru un rând (datorită indicației), în timp ce două rânduri au fost întâlnite la timpul de rulare.
fără uniune toate
această problemă nu este, de asemenea, limitată la interogări scrise în mod explicit cu UNION ALL. Alte construcții, cum ar fiEXISTS șiOR poate duce, de asemenea, la Optimizatorul introducerea unui operator de concatenare, care pot suferi de lipsa de reordonare de intrare. A existat o întrebare recentă privind administratorii de baze de date Stack Exchange cu exact această problemă. Transformarea interogării din această întrebare pentru a utiliza tabelele noastre de exemplu:
SELECT CASE WHEN EXISTS ( SELECT 1 FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 ) OR EXISTS ( SELECT 1 FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 ) THEN 1 ELSE 0 END;
planul de execuție pe SQL Server 2016 are tabelul heap pe prima intrare:
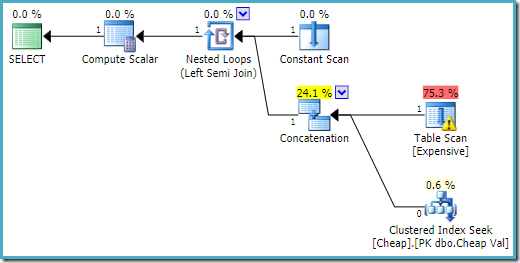
pe SQL Server 2008 R2 ordinea intrărilor este optimizată pentru a reflecta obiectivul unui singur rând al semi join:
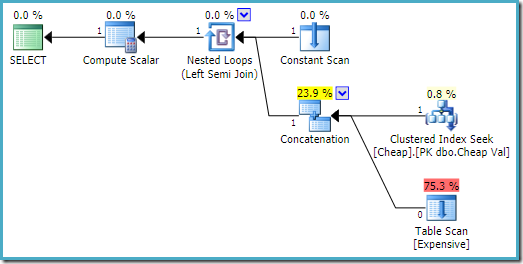
în planul mai optim, scanarea heap nu este executată niciodată.
soluții
În unele cazuri, va fi evident pentru scriitorul de interogări că una dintre intrările de concatenare va fi întotdeauna mai ieftină de rulat decât celelalte. Dacă acest lucru este adevărat, este destul de valabil să rescrieți interogarea, astfel încât intrările de concatenare mai ieftine să apară mai întâi în ordine scrisă. Desigur, acest lucru înseamnă că scriitorul de interogări trebuie să fie conștient de această limitare a optimizatorului și pregătit să se bazeze pe un comportament nedocumentat.
o problemă mai dificilă apare atunci când costul intrărilor de concatenare variază în funcție de circumstanțe, poate în funcție de valorile parametrilor. Folosind OPTION (RECOMPILE) nu va ajuta pe SQL Server 2012 sau mai târziu. Această opțiune poate ajuta pe SQL Server 2008 R2 sau mai devreme, dar numai în cazul în care cerința de obiectiv singur rând este, de asemenea, îndeplinite.
dacă există îngrijorări cu privire la dependența de comportamentul observat (intrări de concatenare a planului de interogare care corespund ordinii textuale a interogării), un ghid de plan poate fi utilizat pentru a forța forma planului. În cazul în care diferite ordine de intrare sunt optime pentru circumstanțe diferite, pot fi utilizate mai multe ghiduri de plan, unde condițiile pot fi codificate cu precizie în avans. Acest lucru este cu greu ideal, deși.
Gânduri finale
SQL Server query optimizer conține de fapt o regulă de explorare bazată pe costuri,UNIAReorderInputs, care este capabilă să genereze variații de ordine de intrare de concatenare și să exploreze alternative în timpul optimizării bazate pe costuri (nu ca o rescriere post-optimizare unică).
această regulă nu este activată momentan pentru uz general. Din câte pot spune, este activat numai atunci când este prezent un ghid de plan sau USE PLAN indiciu. Acest lucru permite motorului să forțeze cu succes un plan care a fost generat pentru o interogare care s-a calificat pentru rescrierea de reordonare a intrărilor, chiar și atunci când interogarea curentă nu se califică.
sentimentul meu este că această regulă de explorare este limitată în mod deliberat la această utilizare, deoarece interogările care ar beneficia de reordonarea intrărilor de concatenare ca parte a optimizării bazate pe costuri sunt considerate nu suficient de comune sau poate pentru că există îngrijorarea că efortul suplimentar nu ar da roade. Opinia mea este că Reordonarea intrării operatorului de concatenare ar trebui să fie întotdeauna explorată atunci când un obiectiv rând este în vigoare.
de asemenea, este păcat că rescrierea post-optimizare (mai limitată) nu este eficientă în SQL Server 2012 sau o versiune ulterioară. Acest lucru s-ar fi putut datora unei erori subtile, dar nu am putut găsi nimic despre acest lucru în documentație, în baza de cunoștințe sau pe Connect. Am adăugat un nou element de conectare aici.
actualizare 9 August 2017: Aceasta este acum fixată sub steagul de urmărire 4199 pentru SQL Server 2014 și 2016, consultați KB 4023419:
remediere: Interogare cu Uniunea toate și un obiectiv rând poate rula mai lent în SQL Server 2014 sau versiuni mai recente atunci când este comparat cu SQL Server 2008 R2
Leave a Reply