UNION ALL Optimization
de samenvoeging van twee of meer datasets wordt meestal uitgedrukt in T-SQL met behulp van de UNION ALL clausule. Gezien het feit dat de SQL Server optimizer vaak dingen zoals joins en aggregaten kan herschikken om de prestaties te verbeteren, is het redelijk om te verwachten dat SQL Server ook zou overwegen om concatenation ingangen opnieuw te ordenen, waar dit een voordeel zou bieden. De optimizer zou bijvoorbeeld de voordelen kunnen overwegen van het herschrijven van A UNION ALL B als B UNION ALL A.
in feite doet de SQL Server optimizer dit niet. Meer precies, Er was enige beperkte ondersteuning voor concatenation input reordering in SQL Server releases tot 2008 R2, maar dit werd verwijderd in SQL Server 2012, en is sindsdien niet meer opgedoken.
SQL Server 2008 R2
intuïtief is de volgorde van concatenatie-invoer alleen van belang als er een rijdoel is. Standaard optimaliseert SQL Server uitvoeringsplannen op basis van het feit dat alle kwalificerende rijen worden geretourneerd aan de client. Wanneer een rijdoel van kracht is, probeert de optimizer een uitvoeringsplan te vinden dat de eerste paar rijen snel zal produceren.
Rijdoelen kunnen op een aantal manieren worden ingesteld, bijvoorbeeld met TOP, een FAST n query hint, of met EXISTS (die door zijn aard ten hoogste één rij moet vinden). Als er geen rijdoel is (dat wil zeggen dat de client alle rijen vereist), maakt het over het algemeen niet uit in welke volgorde de concatenatie-ingangen worden gelezen: elke input zal uiteindelijk in ieder geval volledig worden verwerkt.
De beperkte ondersteuning in versies tot SQL Server 2008 R2 is van toepassing wanneer er een doel van precies één rij is. In deze specifieke situatie zal SQL Server de concatenatie-ingangen opnieuw ordenen op basis van de verwachte kosten.
Dit wordt niet gedaan tijdens kostengebaseerde optimalisatie (zoals men zou verwachten), maar eerder als een last-minute post-optimalisatie herschrijving van de normale Optimizer-uitvoer. Deze regeling heeft het voordeel dat de kostengebaseerde plan zoekruimte niet wordt verhoogd (mogelijk één alternatief voor elke mogelijke herindeling), terwijl er nog steeds een plan wordt geproduceerd dat is geoptimaliseerd om de eerste rij snel terug te keren.
voorbeelden
De volgende voorbeelden gebruiken twee tabellen met identieke inhoud:een miljoen rijen gehele getallen van één tot een miljoen. De ene tabel is een hoop Zonder niet-geclusterde indexen; de andere heeft een unieke geclusterde index:
CREATE TABLE dbo.Expensive( Val bigint NOT NULL); CREATE TABLE dbo.Cheap( Val bigint NOT NULL, CONSTRAINT UNIQUE CLUSTERED (Val));GOINSERT dbo.Cheap WITH (TABLOCKX) (Val)SELECT TOP (1000000) Val = ROW_NUMBER() OVER (ORDER BY SV1.number)FROM master.dbo.spt_values AS SV1CROSS JOIN master.dbo.spt_values AS SV2ORDER BY ValOPTION (MAXDOP 1);GOINSERT dbo.Expensive WITH (TABLOCKX) (Val)SELECT C.ValFROM dbo.Cheap AS COPTION (MAXDOP 1);
Geen Rij-Doel
De volgende query ziet er voor de rijen in elke tabel en geeft als resultaat de concatenatie van de twee sets:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005;
Het uitvoeringsplan geproduceerd door de query optimizer is:
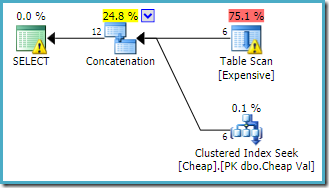
De waarschuwing op de root SELECT operator waarschuwt ons voor de duidelijke ontbrekende index op de heap tabel. De waarschuwing op de table Scan operator wordt toegevoegd door Sentry One Plan Explorer. Het vestigt onze aandacht op de I/O kosten van het resterende predicaat verborgen in de scan.
De volgorde van de invoer in de aaneenschakeling doet er hier niet toe, omdat we geen rijdoel hebben ingesteld. Beide ingangen worden volledig gelezen om alle resultaatrijen te retourneren. Van belang (hoewel dit niet gegarandeerd is) merk op dat de volgorde van de input de tekstvolgorde van de oorspronkelijke vraag volgt. Merk ook op dat de volgorde van de eindresultaatrijen ook niet is opgegeven, omdat we geen top-level ORDER BY clausule hebben gebruikt. We gaan ervan uit dat dit opzettelijk is en dat de uiteindelijke bestelling geen gevolgen heeft voor de taak die voor ons ligt.
als we de geschreven volgorde van de tabellen in de query zo omkeren:
SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 UNION ALL SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005;
De uitvoering van het plan volgt de wijziging, toegang tot de geclusterde tabel eerst (nogmaals, dit is niet gegarandeerd):
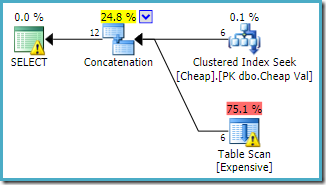
Beide query ‘ s verwacht mag worden om dezelfde prestaties als ze dezelfde handelingen uitvoeren, maar dan in een andere volgorde.
met een Rijdoel
Het is duidelijk dat het ontbreken van indexering op de heaptabel het vinden van specifieke rijen doorgaans duurder maakt, vergeleken met dezelfde bewerking op de geclusterde tabel. Als we de optimizer vragen om een plan dat de eerste rij snel retourneert, verwachten we dat SQL Server de volgorde van de concatenation-ingangen wijzigt zodat de goedkope geclusterde tabel eerst wordt geraadpleegd.
de query gebruiken die als eerste de heaptabel vermeldt, en een snelle 1 query hint gebruiken om het rijdoel te specificeren:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005OPTION (FAST 1);
De geschatte uitvoeringsplan geproduceerd op een exemplaar van SQL Server 2008 R2:
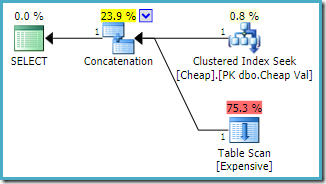
Merk op dat de concatenatie-ingangen werden bijbesteld te verminderen met de geschatte kosten van het terugzenden van de eerste rij. Merk ook op dat de ontbrekende index en resterende I/O waarschuwingen zijn verdwenen. Geen enkel probleem is van belang met deze planvorm wanneer het doel is om een enkele rij zo snel mogelijk terug te keren.
dezelfde query uitgevoerd op SQL Server 2016 (gebruikmakend van een van beide cardinaliteitsschattingsmodellen) is:
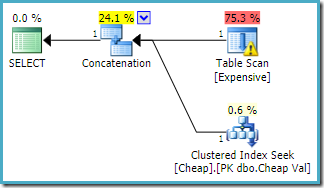
SQL Server 2016 heeft de concatenation-ingangen niet opnieuw geordend. De Plan Explorer I / O waarschuwing is teruggekeerd, maar helaas heeft de optimizer deze keer geen ontbrekende index waarschuwing geproduceerd (hoewel het relevant is).
Algemene herindeling
zoals vermeld, is de herindeling na optimalisatie alleen effectief voor:
- SQL Server 2008 R2 en ouder
- Een rij doel van precies één
Als we echt willen nog maar één rij terug, in plaats van een plan geoptimaliseerd om terug te keren op de eerste rij snel (maar die zal uiteindelijk nog steeds retourneert alle rijen), kunnen we gebruik maken van een TOP – component met een afgeleide tabel of common table expression (CTE):
SELECT TOP (1) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UA;
Op SQL Server 2008 R2 of eerder, dit zorgt voor de optimale nabesteld-ingang plan:
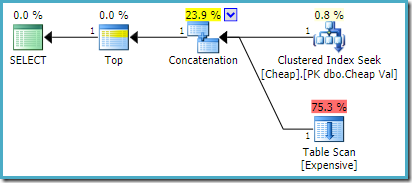
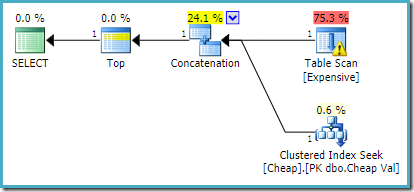
Op SQL Server 2012, 2014 en 2016 Er vindt geen post-optimalisatieherindeling plaats:
als we meer dan één rij willen retourneren, bijvoorbeeld met TOP (2), de gewenste herschrijving zal niet worden toegepast op SQL Server 2008 R2 zelfs als een FAST 1 hint ook wordt gebruikt. In die situatie moeten we gebruik maken van trucs zoals het gebruik van TOP met een variabele en een OPTIMIZE FOR hint:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed SELECT TOP (@TopRows) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UAOPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint
de query hint is voldoende om een rijdoel van één in te stellen, terwijl de runtime waarde van de variabele ervoor zorgt dat het gewenste aantal rijen (2) wordt geretourneerd.
het feitelijke uitvoeringsplan op SQL Server 2008 R2 is:
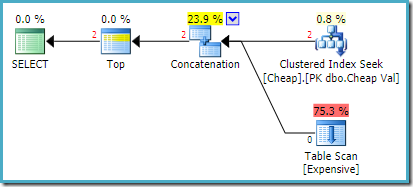
beide geretourneerde rijen komen van de opnieuw geordende zoekinvoer, en de Tabelscan wordt helemaal niet uitgevoerd. Plan Explorer toont de rijen tellingen in rood omdat de schatting was voor een rij (als gevolg van de hint) terwijl twee rijen werden aangetroffen tijdens run time.
zonder UNION ALL
Dit probleem is ook niet beperkt tot queries die expliciet zijn geschreven met UNION ALL. Andere constructies zoals EXISTS en OR kunnen er ook toe leiden dat de optimizer een concatenatie-operator introduceert, die last kan hebben van het gebrek aan herordering van de invoer. Er was een recente Vraag over Database beheerders Stack uitwisseling met precies dit probleem. Het transformeren van de query uit die vraag is gebruik te maken van onze voorbeeld tabellen:
SELECT CASE WHEN EXISTS ( SELECT 1 FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 ) OR EXISTS ( SELECT 1 FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 ) THEN 1 ELSE 0 END;
De uitvoering van het plan op de SQL Server-2016 heeft de hoop tabel op de eerste invoer:
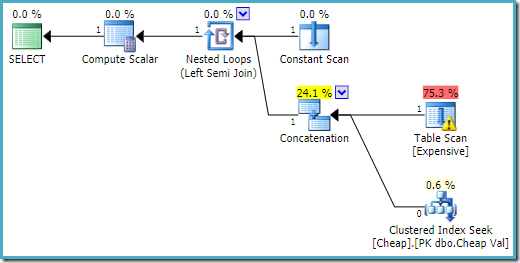
Op SQL Server 2008 R2 is de volgorde van de ingangen is geoptimaliseerd om te reflecteren op de één rij doel van de semi-join:
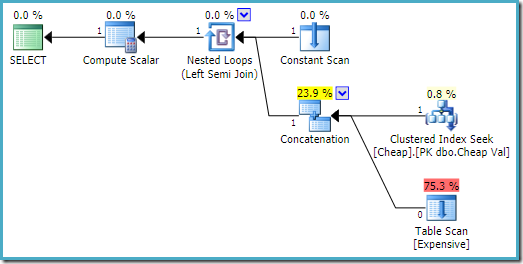
In de meer optimale planning, de heap-scan is nooit uitgevoerd.
Workarounds
in sommige gevallen zal het voor de query writer duidelijk zijn dat een van de concatenation-invoer altijd goedkoper zal zijn dan de andere. Als dat waar is, is het heel geldig om de query te herschrijven, zodat de goedkopere concatenation inputs eerst in geschreven volgorde verschijnen. Dit betekent natuurlijk dat de query writer zich bewust moet zijn van deze optimizer beperking, en bereid moet zijn te vertrouwen op ongedocumenteerd gedrag.
een moeilijker probleem doet zich voor wanneer de kosten van de concatenatie-inputs variëren met de omstandigheden, misschien afhankelijk van parameterwaarden. Het gebruik van OPTION (RECOMPILE) zal niet helpen op SQL Server 2012 of later. Deze optie kan helpen op SQL Server 2008 R2 of eerder, maar alleen als ook aan de doelstelling van een enkele rij wordt voldaan.
als er bezorgdheid is over het vertrouwen op waargenomen gedrag (query plan concatenation input matching the query tekstuele volgorde) een plan gids kan worden gebruikt om de plan vorm forceren. Wanneer verschillende invoerorders optimaal zijn voor verschillende omstandigheden, kunnen meerdere plangidsen worden gebruikt, waarbij de voorwaarden vooraf nauwkeurig kunnen worden gecodeerd. Dit is echter nauwelijks ideaal.
Final Thoughts
De SQL Server query optimizer bevat in feite een op kosten gebaseerde exploratieregel, UNIAReorderInputs, die in staat is om concatenatie invoervolgorde variaties te genereren en alternatieven te verkennen tijdens kostengebaseerde optimalisatie (niet als een single-shot post-optimalisatie herschrijven).
deze regel is momenteel niet ingeschakeld voor algemeen gebruik. Voor zover ik weet wordt het alleen geactiveerd als er een plan guide of USE PLAN hint aanwezig is. Hierdoor kan de motor met succes dwingen een plan dat werd gegenereerd voor een query die gekwalificeerd voor de input-reordering rewrite, zelfs wanneer de huidige query niet in aanmerking komt.
mijn gevoel is dat deze exploratieregel opzettelijk beperkt is tot dit gebruik, omdat query ‘ s die zouden profiteren van concatenation input reordering als onderdeel van kostengebaseerde optimalisatie worden beschouwd als niet voldoende gebruikelijk, of misschien omdat er bezorgdheid is dat de extra inspanning niet loont. Mijn eigen mening is dat Concatenation operator input reordering altijd moet worden onderzocht wanneer een Rij doel in werking is.
Het is ook jammer dat de (meer beperkte) post-optimalisatie rewrite niet effectief is in SQL Server 2012 of later. Dit kan te wijten zijn aan een subtiele bug, maar ik kon niets over dit vinden in de documentatie, knowledge base, of op Connect. Ik heb hier een nieuw Connect item toegevoegd.
Update 9 augustus 2017: Dit is nu opgelost onder trace vlag 4199 voor SQL Server 2014 en 2016, Zie KB 4023419:
FIX: Query met UNION ALL en een rijdoel kan langzamer lopen in SQL Server 2014 of latere versies wanneer het wordt vergeleken met SQL Server 2008 R2
Leave a Reply