uitleg: L1 vs. L2 vs. L3 Cache
elke CPU gevonden in een computer, van een goedkope laptop tot een server van een miljoen dollar, zal iets genaamd cache hebben. Waarschijnlijker dan niet, zal het ook meerdere niveaus hebben.
Het moet belangrijk zijn, anders waarom zou het er zijn? Maar wat doet cache, en waarom de noodzaak van verschillende niveaus van het spul? Wat in hemelsnaam betekent 12-weg set associatief?
Wat is cache precies?
TL; DR: het is klein, maar zeer snel geheugen dat vlak naast de logische eenheden van de CPU zit.
maar natuurlijk kunnen we nog veel meer leren over cache…
laten we beginnen met een imaginair, magisch opslagsysteem: het is oneindig snel, kan een oneindig aantal gegevenstransacties tegelijk verwerken, en houdt gegevens altijd veilig en beveiligd. Niet dat er ook maar iets op afstand van dit bestaat, maar als het wel zo was, zou processorontwerp veel eenvoudiger zijn.
CPU ‘ s hoeven alleen logische eenheden te hebben voor optellen, vermenigvuldigen, enz. en een systeem om de gegevensoverdracht af te handelen. Dit komt omdat ons theoretische opslagsysteem direct alle benodigde nummers kan verzenden en ontvangen; geen van de logische eenheden zou worden opgehouden te wachten op een datatransactie.
maar, zoals we allemaal weten, is er geen magische opslagtechnologie. In plaats daarvan hebben we harde of solid state drives, en zelfs de beste van deze zijn niet eens op afstand in staat om alle gegevensoverdracht die nodig is voor een typische CPU.
De grote T ‘Phon van gegevensopslag
de reden waarom is dat moderne CPU’ s ongelooflijk snel zijn-ze nemen slechts één klokcyclus om twee 64 bit integer waarden samen te voegen, en voor een CPU die op 4 GHz draait, zou dit gewoon 0 zijn.00000000025 seconden of een kwart nanoseconde.
ondertussen duurt het draaien van harde schijven duizenden nanoseconden om alleen maar gegevens op de schijven binnen te vinden, laat staan over te dragen, en solid state drives nemen nog steeds tientallen of honderden nanoseconden in beslag.
dergelijke schijven kunnen uiteraard niet in processors worden ingebouwd, dus dat betekent dat er een fysieke scheiding tussen de twee zal zijn. Dit voegt gewoon meer tijd toe aan het verplaatsen van gegevens, waardoor de dingen nog erger worden.

De Grote a ‘ tuin van gegevensopslag, helaas
dus wat we nodig hebben is een ander gegevensopslagsysteem, dat tussen de processor en de hoofdopslag zit. Het moet sneller zijn dan een schijf, in staat zijn om veel gegevensoverdracht tegelijkertijd te verwerken, en een stuk dichter bij de processor.
Nou, we hebben al zoiets, en het heet RAM, en elk computersysteem heeft er een paar voor dit doel.
bijna van al dit soort opslag is DRAM (dynamic random access memory) en het is in staat om gegevens veel sneller dan elke schijf door te geven.
hoewel DRAM supersnel is, kan het niet zoveel gegevens opslaan.
sommige van de grootste DDR4-geheugenchips gemaakt door Micron, een van de weinige fabrikanten van DRAM ‘ s, bevatten 32 Gbits of 4 GB aan gegevens; de grootste harde schijven bevatten 4.000 keer meer dan dit.
dus hoewel we de snelheid van ons datanetwerk hebben verbeterd, zullen extra systemen — hardware en software — nodig zijn om uit te zoeken welke gegevens moeten worden bewaard in de beperkte hoeveelheid DRAM, klaar voor de CPU.
ten minste DRAM kan worden vervaardigd om zich in het chippakket te bevinden (bekend als ingebedde DRAM). CPU ‘ s zijn vrij klein, hoewel, dus je kunt niet steken dat veel in hen.

10 MB DRAM links van de grafische processor van de Xbox 360. Bron: CPU Grave Yard
het overgrote deel van DRAM bevindt zich direct naast de processor, aangesloten op het moederbord, en het is altijd het dichtst bij de CPU, in een computersysteem. En toch is het nog steeds niet snel genoeg…
DRAM duurt nog steeds ongeveer 100 nanoseconden om gegevens te vinden, maar het kan tenminste miljarden bits per seconde overbrengen. Het lijkt erop dat we nog een fase van geheugen nodig hebben, om tussen de processor ‘ s units en de DRAM te gaan.
voer fase links in: SRAM (static random access memory). Waar DRAM microscopische condensatoren gebruikt om gegevens op te slaan in de vorm van elektrische lading, gebruikt SRAM transistors om hetzelfde te doen en deze kunnen bijna net zo snel werken als de logische eenheden in een processor (ongeveer 10 keer sneller dan DRAM).
Er is natuurlijk een nadeel aan SRAM en nogmaals, het gaat over ruimte.
Transistorgeheugen neemt veel meer ruimte in beslag dan DRAM: voor dezelfde 4 GB DDR4-chip, krijg je minder dan 100 MB aan SRAM. Maar omdat het is gemaakt door middel van hetzelfde proces als het maken van een CPU, SRAM kan worden gebouwd recht in de processor, zo dicht mogelijk bij de logische eenheden mogelijk.
Transistorgeheugen neemt veel meer ruimte in beslag dan DRAM: voor dezelfde 4 GB DDR4-chip, krijg je minder dan 100 MB aan SRAM.
met elke extra fase hebben we de snelheid van het verplaatsen van gegevens verhoogd, tot de kosten van hoeveel we kunnen opslaan. We kunnen doorgaan met het toevoegen van meer secties, met elk een sneller, maar kleiner.
en zo komen we tot een meer technische definitie van wat cache is: het zijn meerdere blokken van SRAM, allemaal in de processor; ze worden gebruikt om ervoor te zorgen dat de logische eenheden zo druk mogelijk worden gehouden, door het verzenden en opslaan van gegevens op super hoge snelheden. Ben je daar blij mee? Goed , want vanaf nu wordt het een stuk ingewikkelder.
Cache: een multi-level parkeerplaats
zoals we besproken hebben, is cache nodig omdat er geen magisch opslagsysteem is dat de gegevensvereisten van de logische eenheden in een processor kan bijhouden. Moderne CPU ‘ s en grafische processors bevatten een aantal SRAM-blokken, die intern zijn georganiseerd in een hiërarchie — een reeks caches die als volgt zijn geordend:

In de bovenstaande afbeelding wordt de CPU weergegeven door de zwartgestreepte rechthoek. De ALU ‘ s (rekenkundige logische eenheden) bevinden zich uiterst links; dit zijn de structuren die de processor aandrijven, die de wiskunde van de chip verwerken. Terwijl zijn technisch niet cache, het dichtstbijzijnde niveau van geheugen aan de ALU ‘ s zijn de registers (ze zijn gegroepeerd in een register bestand).
elk van deze bevat een enkel getal, zoals een 64-bit integer; de waarde zelf kan een stuk gegevens over iets zijn, een code voor een specifieke instructie, of het geheugenadres van een aantal andere gegevens.
het register bestand in een desktop CPU is vrij klein — bijvoorbeeld, in Intel ‘ s Core i9-9900K, zijn er twee banken van hen in elke core, en de ene voor gehele getallen bevat slechts 180 64-bit registers. Het andere register bestand, voor vectoren (kleine series van nummers), heeft 168 256-bit ingangen. Dus het totale register bestand voor elke core is iets minder dan 7 kB. Ter vergelijking, het register bestand in de Streaming Multiprocessors (de GPU equivalent van een CPU ‘ s core) van een Nvidia GeForce RTX 2080 Ti is 256 kB groot.
Registers zijn SRAM, net als cache, maar ze zijn net zo snel als de ALU ‘ s die ze bedienen, en pushen data in en uit in een enkele klokcyclus. Maar ze zijn niet ontworpen om heel veel data te bevatten (slechts een enkel stukje ervan), daarom zijn er altijd wat grotere blokken geheugen in de buurt: Dit is de level 1 cache.
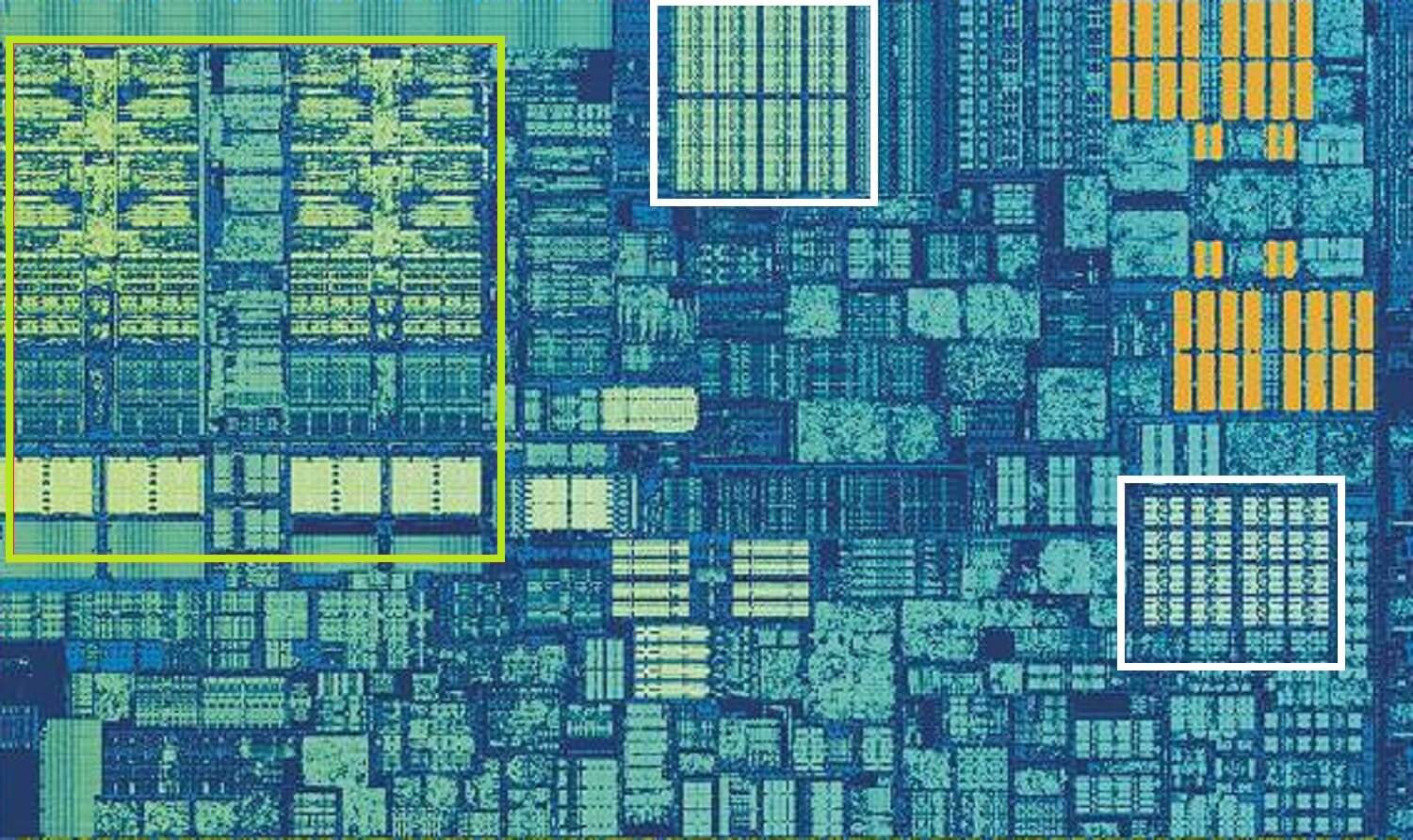
Intel Skylake CPU, ingezoomd schot van een enkele kern. Bron: Wikichip
bovenstaande afbeelding is een ingezoomd beeld van een enkele kern van Intel ‘ s Skylake desktop processor ontwerp.
de ALU ‘ s en de registerbestanden zijn uiterst links te zien, gemarkeerd in het groen. In het midden van de afbeelding, in het wit, staat de Niveau 1 data cache. Dit bevat niet veel informatie, slechts 32 kB, maar net als registers, het is heel dicht bij de logische eenheden en draait op dezelfde snelheid als hen.
de andere witte rechthoek geeft de level 1 Instructie cache aan, ook 32 kB groot. Zoals de naam al doet vermoeden, dit slaat verschillende commando ’s klaar om te worden opgesplitst in kleinere, zogenaamde micro-operaties (meestal gelabeld als µops), voor de ALU’ s uit te voeren. Er is ook een cache voor hen, en je zou het kunnen classificeren als Niveau 0, want het is kleiner (alleen met 1.500 operaties) en dichter dan de L1 caches.
je vraagt je misschien af waarom deze blokken SRAM zo klein zijn; waarom zijn ze geen megabyte groot? Samen, de gegevens en instructie caches nemen bijna dezelfde hoeveelheid ruimte in de chip als de belangrijkste logische eenheden doen, dus het maken van hen groter zou de totale grootte van de matrijs te verhogen.
maar de belangrijkste reden waarom ze slechts een paar kB bevatten, is dat de tijd die nodig is om gegevens te vinden en op te halen toeneemt naarmate de geheugencapaciteit groter wordt. L1 cache moet echt snel zijn, en dus moet een compromis worden bereikt, tussen grootte en snelheid-op zijn best, het duurt ongeveer 5 klokcycli (langer voor drijvende komma waarden) om de gegevens uit deze cache, klaar voor gebruik.
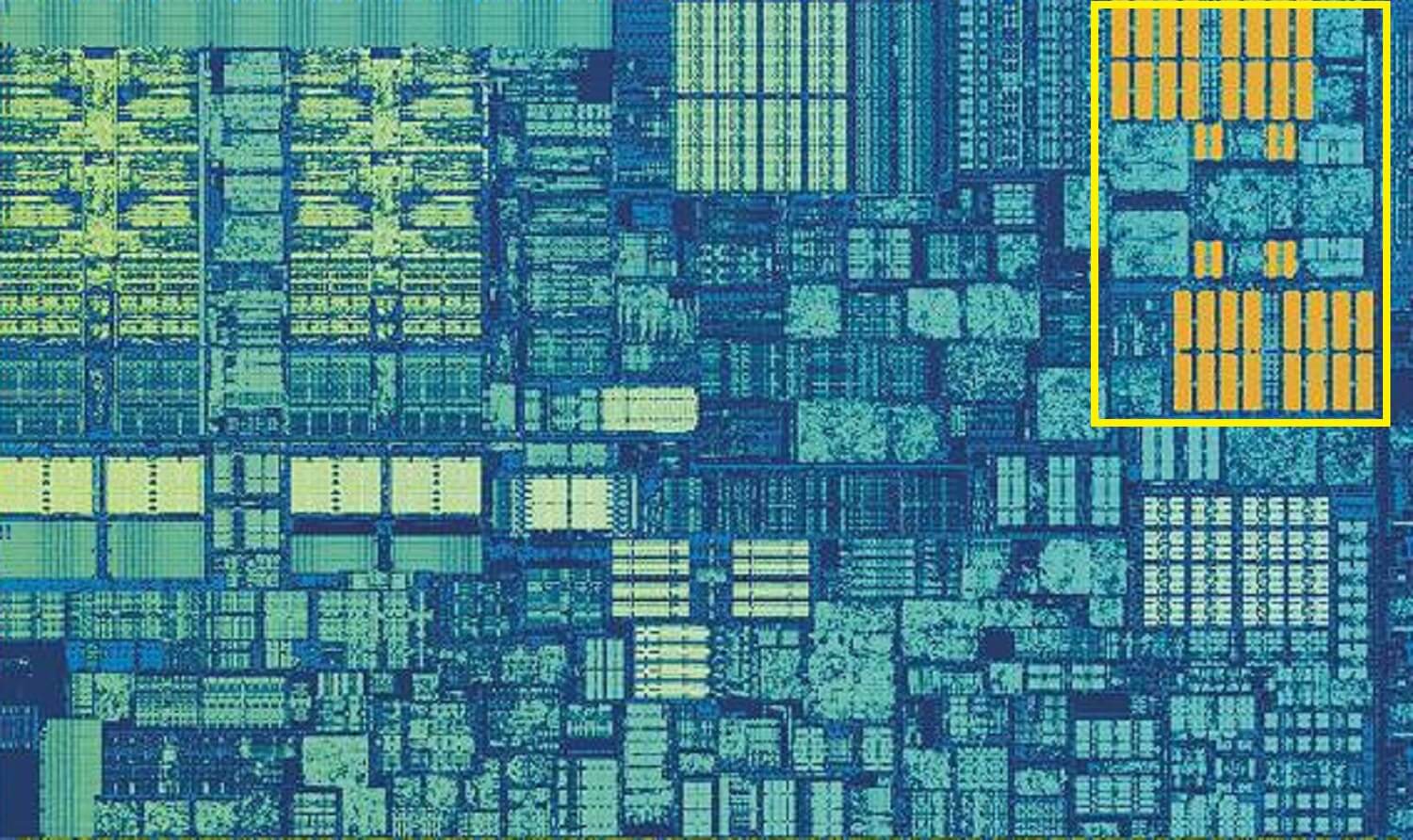
Skylake ‘ s L2 cache: 256 kB van SRAM goodness
maar als dit de enige cache in een processor was, dan zou de prestaties een plotselinge muur raken. Dit is de reden waarom ze allemaal een ander niveau van geheugen ingebouwd in de kernen: de LEVEL 2 cache. Dit is een algemeen blok van opslag, het vasthouden van instructies en gegevens.
Het is altijd een stuk groter dan Niveau 1: AMD Zen 2 processors pakken tot 512 kB in, zodat de lagere caches goed meegeleverd kunnen worden. Deze extra grootte komt tegen een kostprijs, hoewel, en het duurt ongeveer twee keer zo lang om de gegevens van deze cache te vinden en over te dragen, in vergelijking met Niveau 1.
teruggaand in de tijd, tot de dagen van de oorspronkelijke Intel Pentium, was Level 2 cache een aparte chip, ofwel op een kleine plug-in printplaat (zoals een RAM DIMM) of ingebouwd in het moederbord. Het werkte uiteindelijk zijn weg naar het CPU-pakket zelf, totdat het uiteindelijk werd geïntegreerd in de CPU die, zoals de Pentium III en AMD K6-III processors.
deze ontwikkeling werd al snel gevolgd door een ander niveau van cache, daar om de andere lagere niveaus te ondersteunen, en het kwam tot stand door de opkomst van multi-core chips.

Intel Kaby Lake chip. Bron: Wikichip
deze afbeelding, van een Intel Kaby Lake chip, toont 4 cores in het links-midden (een geïntegreerde GPU neemt bijna de helft van de dobbelsteen in beslag, aan de rechterkant). Elke kern heeft zijn eigen ‘private’ set van niveau 1 en 2 caches (witte en gele highlights), maar ze komen ook met een derde set SRAM blokken.
niveau 3 cache, ook al is het direct rond een enkele kern, wordt volledig gedeeld met de anderen-elk kan vrij toegang krijgen tot de inhoud van een ander L3 cache. Het is veel groter (tussen 2 en 32 MB) maar ook een stuk langzamer, gemiddeld over 30 cycli, vooral als een kern moet gegevens die in een blok van cache enige afstand te gebruiken.
hieronder kunnen we een enkele kern zien in de Zen 2-architectuur van AMD: de 32 kB niveau 1 data en instructie caches in het wit, De 512 KB niveau 2 in het geel, en een enorm 4 MB blok L3 cache in het rood.

AMD Zen 2 CPU, ingezoomd schot van een enkele kern. Bron: Fritzchens Fritz
wacht even. Hoe kan 32 kB meer fysieke ruimte innemen dan 512 kB? Als Niveau 1 zo weinig gegevens bevat, waarom is het proportioneel zo veel groter dan L2 of L3 cache?
meer dan alleen een getal
Cache verhoogt de prestaties door de gegevensoverdracht naar de logische eenheden te versnellen en een kopie van veelgebruikte instructies en gegevens in de buurt te houden. De informatie die is opgeslagen in de cache is opgesplitst in twee delen: de gegevens zelf en de locatie waar het oorspronkelijk zich bevond in het systeemgeheugen/Opslag — dit adres wordt een cache-tag genoemd.
wanneer de CPU een bewerking uitvoert die gegevens van/naar het geheugen wil lezen of schrijven, begint het met het controleren van de tags in de level 1 cache. Als de vereiste aanwezig is (een cache hit), die gegevens kunnen dan bijna meteen worden benaderd. Een cache miss treedt op wanneer de vereiste tag zich niet in het laagste cache niveau bevindt.
dus een nieuwe tag wordt aangemaakt in de L1 cache, en de rest van de processorarchitectuur neemt het over, door terug te jagen via de andere cache levels (helemaal terug naar het hoofd opslagstation, indien nodig) om de gegevens voor die tag te vinden. Maar om ruimte te maken in de L1 cache voor deze nieuwe tag, moet er altijd iets anders worden opgestart in de L2.
Dit resulteert in een bijna constant schuifelen over gegevens, allemaal bereikt in slechts een handvol klokcycli. De enige manier om dit te bereiken is door een complexe structuur rond het SRAM te hebben, om het beheer van de data te beheren. Zet een andere manier: als een CPU-kern uit slechts één ALU bestond, dan zou de L1-cache veel eenvoudiger zijn, maar aangezien er tientallen van zijn (waarvan er vele twee threads met instructies zullen jongleren), vereist de cache meerdere verbindingen om alles in beweging te houden.
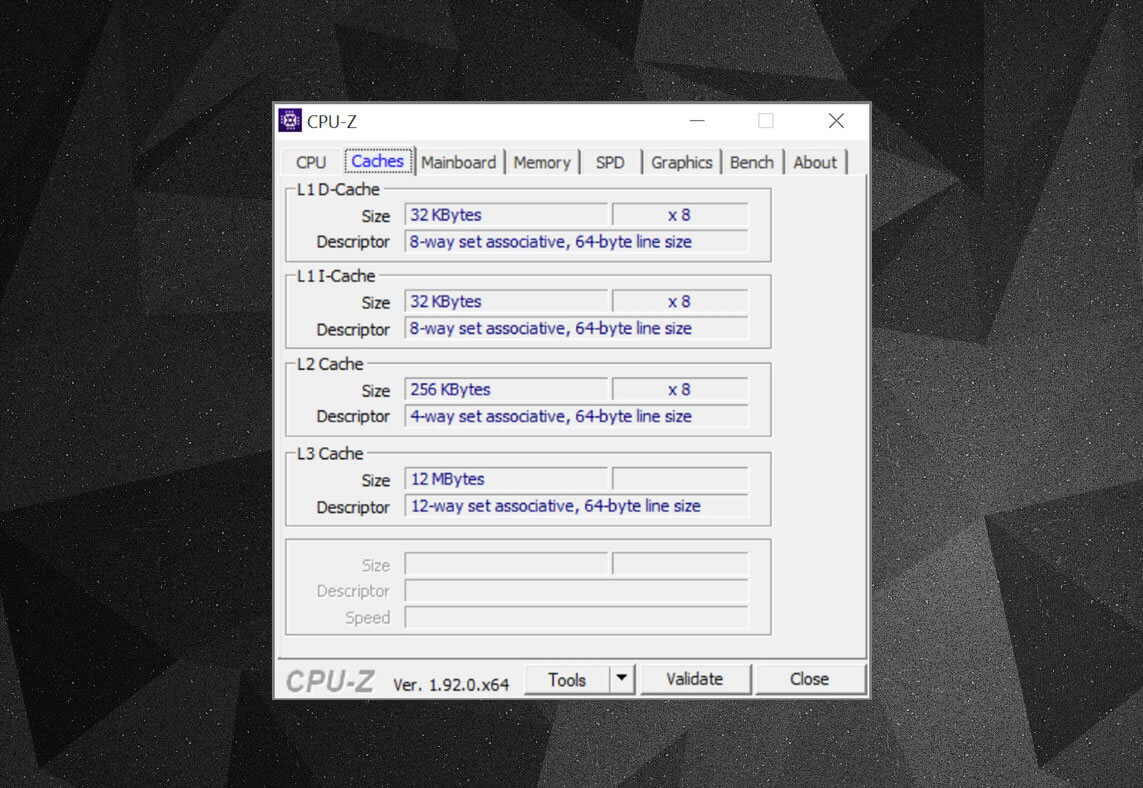
u kunt vrije programma ‘ s, zoals CPU-Z, gebruiken om de cache-informatie te bekijken voor de processor die uw eigen computer voedt. Maar wat betekent al die informatie? Een belangrijk element is de label set associatieve-dit gaat allemaal over de regels afgedwongen door hoe blokken van gegevens uit het systeemgeheugen worden gekopieerd in de cache.
de bovenstaande cache informatie is voor een Intel Core i7-9700K. de Niveau 1 caches zijn elk opgesplitst in 64 kleine blokken, genaamd sets, en elk van deze is verder verdeeld in cache regels (64 bytes groot). Set associative betekent dat een blok van gegevens uit het systeemgeheugen wordt toegewezen aan de cache lijnen in een bepaalde set, in plaats van vrij om overal in kaart te brengen.
het 8-weg gedeelte vertelt ons dat een blok geassocieerd kan worden met 8 cache regels in een set. Hoe groter het niveau van associativiteit (dat wil zeggen meer ‘manieren’), hoe groter de kans op het krijgen van een cache hit wanneer de CPU gaat jagen voor gegevens, en een vermindering van de sancties veroorzaakt door cache misses. De nadelen zijn dat het voegt meer complexiteit, verhoogd energieverbruik, en kan ook de prestaties te verminderen, omdat er meer cache lijnen te verwerken voor een blok van gegevens.

L1+L2 inclusive cache, L3 victim cache, write-back polices, even ECC. Bron: Fritzchens Fritz
een ander aspect van de complexiteit van de cache draait om hoe gegevens worden bewaard over de verschillende niveaus. De regels zijn vastgelegd in iets dat het inclusiebeleid wordt genoemd. Bijvoorbeeld, Intel Core processors hebben volledig inclusieve L1 + L3 cache. Dit betekent dat dezelfde gegevens in niveau 1 bijvoorbeeld ook in niveau 3 kunnen zijn. Dit lijkt misschien alsof het verspillen van waardevolle cache ruimte, maar het voordeel is dat als de processor krijgt een miss, bij het zoeken naar een tag in een lager niveau, het hoeft niet te jagen door het hogere niveau om het te vinden.
In dezelfde processors is de L2-cache niet inclusief: alle gegevens die daar zijn opgeslagen, worden niet naar een ander niveau gekopieerd. Dit bespaart ruimte, maar zorgt ervoor dat het geheugensysteem van de chip moet zoeken via L3 (die altijd veel groter is) om een gemiste tag te vinden. Slachtoffer caches zijn vergelijkbaar met deze, maar ze zijn gewend aan opgeslagen informatie die wordt geduwd uit een lager niveau-bijvoorbeeld, AMD ‘ s Zen 2 processors gebruiken L3 slachtoffer cache die alleen slaat gegevens van L2.
Er zijn andere beleidsregels voor cache, zoals wanneer gegevens in cache en het hoofdsysteemgeheugen worden geschreven. Deze worden write policies genoemd en de meeste van de huidige CPU ‘ s gebruiken write-back caches; dit betekent dat wanneer gegevens in een cache-niveau worden geschreven, er een vertraging is voordat het systeemgeheugen wordt bijgewerkt met een kopie ervan. Voor het grootste deel, deze pauze loopt voor zolang de gegevens in de cache blijft-alleen als het eenmaal is opgestart, krijgt het RAM de informatie.

Nvidia ‘ s ga100 grafische processor, verpakt met een totaal van 20 MB van L1 en 40 MB van L2 cache
voor processor ontwerpers, het kiezen van de hoeveelheid, het type en het beleid van cache is alles over het afwegen van de wens voor een grotere processorcapaciteit tegen verhoogde complexiteit en vereiste die ruimte. Als het mogelijk was om 20 MB, 1000-weg volledig associatieve niveau 1 caches zonder de chips worden de grootte van Manhattan (en consumeren van dezelfde soort macht), dan zouden we allemaal computers met dergelijke chips!
het laagste niveau van caches in de huidige CPU ‘ s zijn niet veel veranderd in de afgelopen tien jaar. Level 3 cache is echter blijven groeien in omvang. Tien jaar geleden kon je er 12 MB van krijgen, als je het geluk had om een $ 999 Intel i7-980X te bezitten. voor de helft van dat bedrag vandaag, krijg je 64 MB.
Cache, in een notendop: absoluut nodig, absoluut geweldige stukjes technologie. We hebben niet gekeken naar andere caches types in CPU ’s en GPU’ s (zoals vertaling lookup buffers of texture caches), maar omdat ze allemaal volgen een eenvoudige structuur en patroon van niveaus zoals we hier hebben behandeld, zullen ze misschien niet zo ingewikkeld klinken.
had u een computer met L2-cache op het moederbord? Hoe zit het met die slot-gebaseerde Pentium II en Celeron CPU ‘ s (b. v. 300a) die in een daughterboard kwamen? Kun je je eerste CPU herinneren die L3 had gedeeld? Laat het ons weten in de commentaren sectie.
sneltoetsen Voor Winkelen:
- AMD Ryzen 9 3900X op Amazon
- AMD Ryzen 9 3950X op Amazon
- Intel Core i9-10900K op Amazon
- AMD Ryzen 7 3700X op Amazon
- Intel Core i7-10700K op Amazon
- AMD Ryzen 5 3600 op Amazon
- Intel Core i5-10600K op Amazon
verder Lezen. Explainers at TechSpot
- Wi – Fi 6 uitgelegd: de volgende generatie Wi-Fi
- Wat zijn Tensor Cores?
- Wat Is Chip Binning?
Leave a Reply