UNION ALL optimointi
kahden tai useamman tietojoukon yhtymäkohta ilmaistaan tavallisimmin T-SQL: ssä käyttäen UNION ALL lauseketta. Koska SQL Server optimizer voi usein järjestää uudelleen asioita, kuten liitokset ja aggregaatit suorituskyvyn parantamiseksi, on varsin kohtuullista odottaa, että SQL Server harkitsisi myös uudelleenjärjestely concatenation tuloa, jos tämä antaisi edun. Optimoija voisi esimerkiksi harkita A UNION ALL B uudelleenkirjoittamisen etuja B UNION ALL A.
itse asiassa SQL Server optimizer ei tee näin. Tarkemmin, oli jonkin verran rajoitettu tuki concatenation input uudelleenjärjestely SQL Server julkaisuja jopa 2008 R2, mutta tämä poistettiin SQL Server 2012, ja ei ole palannut sen jälkeen.
SQL Server 2008 R2
intuitiivisesti yhtymätulojen järjestyksellä on merkitystä vain, jos on rivimaali. Oletuksena SQL Server optimoi suoritussuunnitelmat sillä perusteella, että kaikki vaatimukset täyttävät rivit palautetaan asiakkaalle. Kun rivitavoite on voimassa, optimoija yrittää löytää suoritussuunnitelman, joka tuottaa ensimmäiset rivit nopeasti.
Rivitavoitteet voidaan asettaa monella tavalla, esimerkiksi käyttämällä TOP, a FAST n query vinkkiä tai käyttämällä EXISTS (joka luonteensa vuoksi tarvitsee löytää korkeintaan yhden rivin). Jos rivitavoitetta ei ole (eli asiakas vaatii kaikki rivit), ei ole yleensä väliä, missä järjestyksessä tiivistämistulot luetaan: jokainen panos käsitellään lopulta joka tapauksessa kokonaan.
rajoitettu tuki versioissa SQL Server 2008 R2: een asti pätee, jos tavoite on tasan yksi rivi. Tässä erityistilanteessa SQL Server järjestää uudelleen yhteistulot odotettujen kustannusten perusteella.
tätä ei tehdä kustannuspohjaisen optimoinnin aikana (kuten voisi olettaa), vaan pikemminkin normaalin optimointilähdön viime hetken jälkioptimoinnin uudelleenkirjoituksena. Tämän järjestelyn etuna on se, että se ei lisää kustannusperusteista suunnitelman hakutilaa (mahdollisesti yksi vaihtoehto jokaiselle mahdolliselle uudelleenjärjestelylle), mutta tuottaa silti suunnitelman, joka on optimoitu palauttamaan ensimmäinen rivi nopeasti.
esimerkit
seuraavissa esimerkeissä käytetään kahta sisällöltään identtistä taulukkoa: miljoona riviä kokonaislukuja yhdestä miljoonaan. Yksi taulukko on kasa, jossa ei ole nonclustered indeksit; toinen on ainutlaatuinen klusteroitu indeksi:
CREATE TABLE dbo.Expensive( Val bigint NOT NULL); CREATE TABLE dbo.Cheap( Val bigint NOT NULL, CONSTRAINT UNIQUE CLUSTERED (Val));GOINSERT dbo.Cheap WITH (TABLOCKX) (Val)SELECT TOP (1000000) Val = ROW_NUMBER() OVER (ORDER BY SV1.number)FROM master.dbo.spt_values AS SV1CROSS JOIN master.dbo.spt_values AS SV2ORDER BY ValOPTION (MAXDOP 1);GOINSERT dbo.Expensive WITH (TABLOCKX) (Val)SELECT C.ValFROM dbo.Cheap AS COPTION (MAXDOP 1);
Ei Rivimaalia
seuraava kysely etsii samat rivit jokaisessa taulukossa ja palauttaa kahden sarjat:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005;
kyselyn optimoijan tuottama suoritussuunnitelma on:
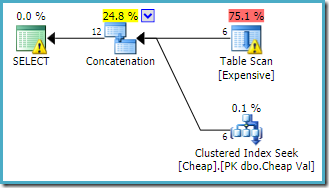
juurella SELECT operaattori varoittaa heap-pöydällä olevasta ilmeisestä puuttuvasta indeksistä. Taulukon Skannausoperaattorin varoituksen lisää Sentry One Plan Explorer. Se kiinnittää huomiomme luotauksessa piilevän predikaatin I/O-kustannuksiin.
syöttöjen järjestyksellä ei ole tässä merkitystä, koska rivitavoitetta ei ole asetettu. Molemmat tulot luetaan kokonaisuudessaan, jotta kaikki tulosrivit voidaan palauttaa. On mielenkiintoista (vaikka tämä ei ole taattu) huomata, että syötteiden järjestys noudattaa alkuperäisen kyselyn tekstimuotoista järjestystä. Huomaa myös, että myöskään lopputulosrivien järjestystä ei ole määritelty, koska emme käyttäneet ylätason ORDER BY lauseketta. Oletamme, että se on tahallista ja lopullinen määräys on merkityksetön tässä tehtävässä.
Jos käännämme kyselyn taulukoiden kirjallisen järjestyksen näin:
SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 UNION ALL SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005;
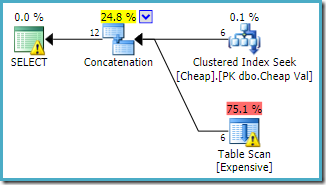 Union all with reversed input
Union all with reversed input
molemmilla kyselyillä voidaan olettaa olevan samat suoritusominaisuudet, koska ne suorittavat samat operaatiot, vain eri järjestyksessä.
Rivitavoitteella
selvästi kasapöydän indeksoinnin puuttuminen tekee yleensä tiettyjen rivien löytämisen kalliimmaksi verrattuna samaan operaatioon ryhmitetyllä pöydällä. Jos pyydämme optimizer varten suunnitelma, joka palauttaa ensimmäisen rivin nopeasti, odotamme SQL Server uudelleen concatenation tuloa niin halpa ryhmitelty taulukko on kuultu ensin.
käyttäen kyselyä, joka mainitsee kasapöydän ensimmäisenä, ja käyttämällä nopeaa 1-kyselyvihjettä rivitavoitteen määrittämiseen:
SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.ValFROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005OPTION (FAST 1);
SQL Server 2008 R2-esiintymän arvioitu toteutussuunnitelma on:
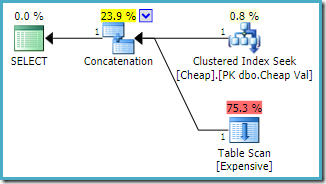
notice that the concatenation inputs have been ordered to reduce the estimated cost of returning the first row. Huomaa myös, että puuttuvat indeksi-ja I/O-varoitukset ovat kadonneet. Kummallakaan asialla ei ole merkitystä tämän kaavamuodon kanssa, kun tavoitteena on palauttaa yksi rivi mahdollisimman nopeasti.
sama kysely, joka on tehty SQL Server 2016: ssa (käyttäen jompaakumpaa kardinaalisuuden estimointimallia), on:
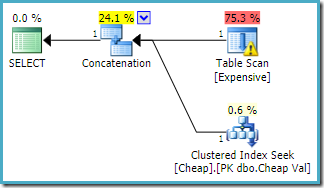
SQL Server 2016 ei ole järjestänyt uudelleen yhtymätuloja. Plan Explorer I / O-varoitus on palannut, mutta valitettavasti optimizer ei ole tuottanut puuttuvaa indeksivaroitusta tällä kertaa (vaikka sillä on merkitystä).
yleinen uudelleenjärjestely
kuten mainittiin, jälkioptimoinnin rewrite että uudelleenjärjestely concatenation tulot on tehokas vain:
- SQL Server 2008 R2 ja aiemmin
- tasan yhden rivin rivitavoite
Jos haluamme aidosti vain yhden rivin palautettavan, eikä suunnitelmaa, joka on optimoitu palauttamaan ensimmäinen rivi nopeasti (mutta joka lopulta kuitenkin palauttaa kaikki rivit), Voimme käyttää TOP lauseketta, jossa on johdettu taulukko tai yhteinen taulukkolauseke (CTE):
SELECT TOP (1) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UA;
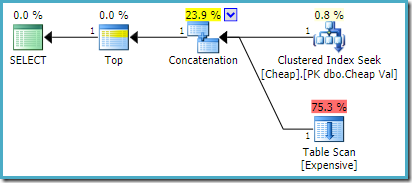
SQL Server 2012, 2014 ja 2016 Ei jälkioptimointia tapahdu:
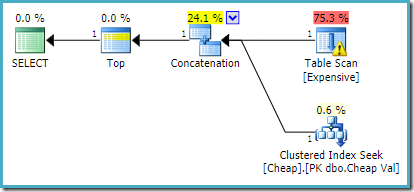
Jos haluamme, että useampi kuin yksi rivi palautetaan, esimerkiksi käyttämällä TOP (2) haluttua uudelleenkirjoitusta ei sovelleta SQL Server 2008 R2: ssa, vaikka myös FAST 1 vihjettä käytetään. Siinä tilanteessa on turvauduttava temppuihin, kuten käyttämällä TOP muuttujan ja OPTIMIZE FOR vihjettä:
DECLARE @TopRows bigint = 2; -- Number of rows actually needed SELECT TOP (@TopRows) UA.ValFROM( SELECT E.Val FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 UNION ALL SELECT C.Val FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005) AS UAOPTION (OPTIMIZE FOR (@TopRows = 1)); -- Just a hint
kyselyvihje riittää asettamaan rivitavoitteeksi yhden, kun muuttujan ajonaikainen arvo takaa halutun rivimäärän (2).
SQL Server 2008 R2: n varsinainen suoritussuunnitelma on:
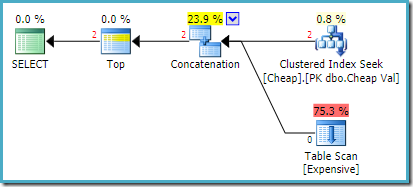
molemmat palautetut rivit tulevat uudelleenjärjestetystä hakusyötöstä, eikä Taulukkokannausta suoriteta lainkaan. Plan Explorer näyttää rivin luvut punaisella, koska arvio oli yhdelle riville (vihjeen vuoksi), kun taas kaksi riviä kohdattiin ajon aikana.
ilman unionia kaikki
tämäkään kysymys ei rajoitu kyselyihin, jotka on kirjoitettu eksplisiittisesti UNION ALL. Myös muut konstruktiot, kuten EXISTS ja OR, voivat johtaa siihen, että optimoija ottaa käyttöön konstruktiooperaattorin, joka saattaa kärsiä syötteen uudelleenjärjestelyn puutteesta. Oli äskettäin kysymys tietokannan ylläpitäjät Pino vaihto juuri tätä asiaa. Kyselyn muuttaminen tästä kysymyksestä esimerkkitaulukkojemme käyttöön:
SELECT CASE WHEN EXISTS ( SELECT 1 FROM dbo.Expensive AS E WHERE E.Val BETWEEN 751000 AND 751005 ) OR EXISTS ( SELECT 1 FROM dbo.Cheap AS C WHERE C.Val BETWEEN 751000 AND 751005 ) THEN 1 ELSE 0 END;
SQL Server 2016: n toteutussuunnitelmassa on heap-taulukko ensimmäisellä syötteellä:
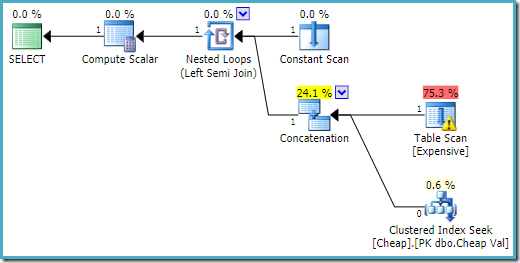
SQL Server 2008 R2: ssa tulojärjestys on optimoitu vastaamaan puolijoukon yksittäistä rivitavoitetta:
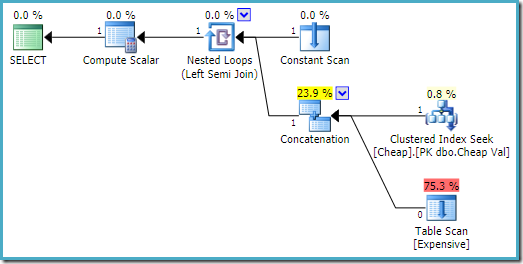
optimaalisemmassa suunnitelmassa heap scan ei ole koskaan teloitettu.
Workarounds
joissakin tapauksissa kyselyn kirjoittajalle käy selväksi, että yksi konsatenaatiopanoksista on aina halvempi ajaa kuin muut. Jos tämä on totta, on aivan perusteltua kirjoittaa kysely uudelleen niin, että halvemmat yhtymätulot näkyvät ensin kirjallisessa järjestyksessä. Tämä tarkoittaa tietenkin sitä, että kyselyn kirjoittajan on oltava tietoinen tästä optimointirajoituksesta ja valmis luottamaan paperittomuuteen.
vaikeampi kysymys syntyy, kun yhdistämispanosten kustannukset vaihtelevat olosuhteiden mukaan, ehkä parametriarvojen mukaan. OPTION (RECOMPILE) käyttäminen ei auta SQL Server 2012: ssa eikä myöhemmässäkään. Tämä vaihtoehto voi auttaa SQL Server 2008 R2: ssa tai aikaisemmin, mutta vain, jos myös yhden rivin maalivaatimus täyttyy.
Jos havaitun käyttäytymisen käyttäminen (kyselyn tekstijärjestystä vastaavat kyselysuunnitelman yhteistulot) huolettaa, suunnitelman muotoa voidaan pakottaa. Jos eri syöttötilaukset ovat optimaalisia eri olosuhteissa, voidaan käyttää useita suunnitelma-oppaita, joissa ehdot voidaan koodata tarkasti etukäteen. Tämä tuskin on ihanteellinen.
Final Thoughts
SQL Server query optimizer sisältää itse asiassa kustannusperusteisen tutkimussäännön, UNIAReorderInputs, joka pystyy tuottamaan konsatenaation tulojärjestyksen vaihteluita ja tutkimaan vaihtoehtoja kustannusperusteisen optimoinnin aikana (ei kertaoptimoinnin jälkeisenä uudelleenkirjoituksena).
Tämä sääntö ei ole tällä hetkellä käytössä yleisessä käytössä. Tietääkseni se aktivoituu vain, kun plan guide tai USE PLAN vihje on läsnä. Tämä mahdollistaa sen, että moottori voi onnistuneesti pakottaa suunnitelman, joka luotiin syötteen uudelleenjärjestämiseen kelpaavaa kyselyä varten, vaikka nykyinen kysely ei kelpuuttaisi.
mielestäni tämä tutkimussääntö on tarkoituksellisesti rajoitettu tähän käyttöön, koska kyselyjä, jotka hyötyisivät yhteistuoton uudelleenjärjestämisestä osana kustannusperusteista optimointia, ei pidetä riittävän yleisinä, tai ehkä siksi, että on olemassa huoli siitä, että lisäpanostus ei kannattaisi. Oma näkemykseni on, että Konsatenaatio operaattorin syötteen uudelleenjärjestämistä tulisi aina tutkia, kun rivitavoite on voimassa.
on myös sääli, että (suppeampi) jälkioptimoinnin uudelleenkirjoitus ei ole tehokas SQL Server 2012: ssa tai myöhemmässä. Tämä saattoi johtua hienovaraisesta viasta, mutta en löytänyt mitään tästä dokumentaatiosta, tietopohjasta tai Connectista. Olen lisännyt uuden Connect kohteen täällä.
päivitys 9. elokuuta 2017: Tämä on nyt korjattu trace-lipulla 4199 SQL Server 2014: lle ja 2016: katso KB 4023419:
FIX: Kysely, jossa on UNION ALL – Ja a row goal, voi ajaa hitaammin SQL Server 2014-tai sitä uudemmissa versioissa verrattuna SQL Server 2008 R2: een
Leave a Reply